| y | x1 | x2 | x3 | b |
|---|---|---|---|---|
| 10.56 | 1 | 1 | 1 | 1 |
| 6.57 | -1 | 1 | 1 | 1 |
| 9.03 | 1 | -1 | 1 | 1 |
| 5.37 | -1 | -1 | 1 | 1 |
| 5.71 | 1 | 1 | -1 | 1 |
| 1.36 | -1 | 1 | -1 | 1 |
| 2.77 | 1 | -1 | -1 | 1 |
| -0.19 | -1 | -1 | -1 | 1 |
48 実験計画法
実験計画法(Design of Experiments)とは、何らかの実験を行う際に、29章で説明した分散分析や30章で説明した一般線形モデルを用いて、うまく傾き・切片を求めるための実験を組むための方法論です。
分散分析や一般線形モデルでは、各説明変数の主効果(傾き)や切片の他に、説明変数間の交互作用(Interaction)を求めます。しかし、説明変数が増えると、一般線形モデルについての説明に述べた通り、交互作用がたくさん生まれることになります。また、実験をたくさん行うには、時間やお金がかかります。できるだけ行う実験の数を減らしつつ、主効果・交互作用をうまく求めたい場合、実験計画法が役に立ちます。
Tipフィッシャーの3原則
実験計画法を説明する前に、実験を計画する際に守るべき基本のルール、フィッシャーの3原則について簡単に説明します。フィッシャーの3原則とは、「反復」・「無作為化」・「局所管理」の3つで、この3つを守って実験を行うことで分散分析に必要となるデータを適切に取得することができます。
48.0.1 反復(replication)
反復とはその名の通り、繰り返すことです。同じセットの実験を繰り返すことで、求まる平均値・標準偏差や回帰の傾き・切片などは真の値に近づいていきます。真の値に近づいていく様子は12章で標準誤差の意味と共に簡単に説明しています。
48.0.2 無作為化(randomization)
無作為化はランダム化とも呼ばれます。
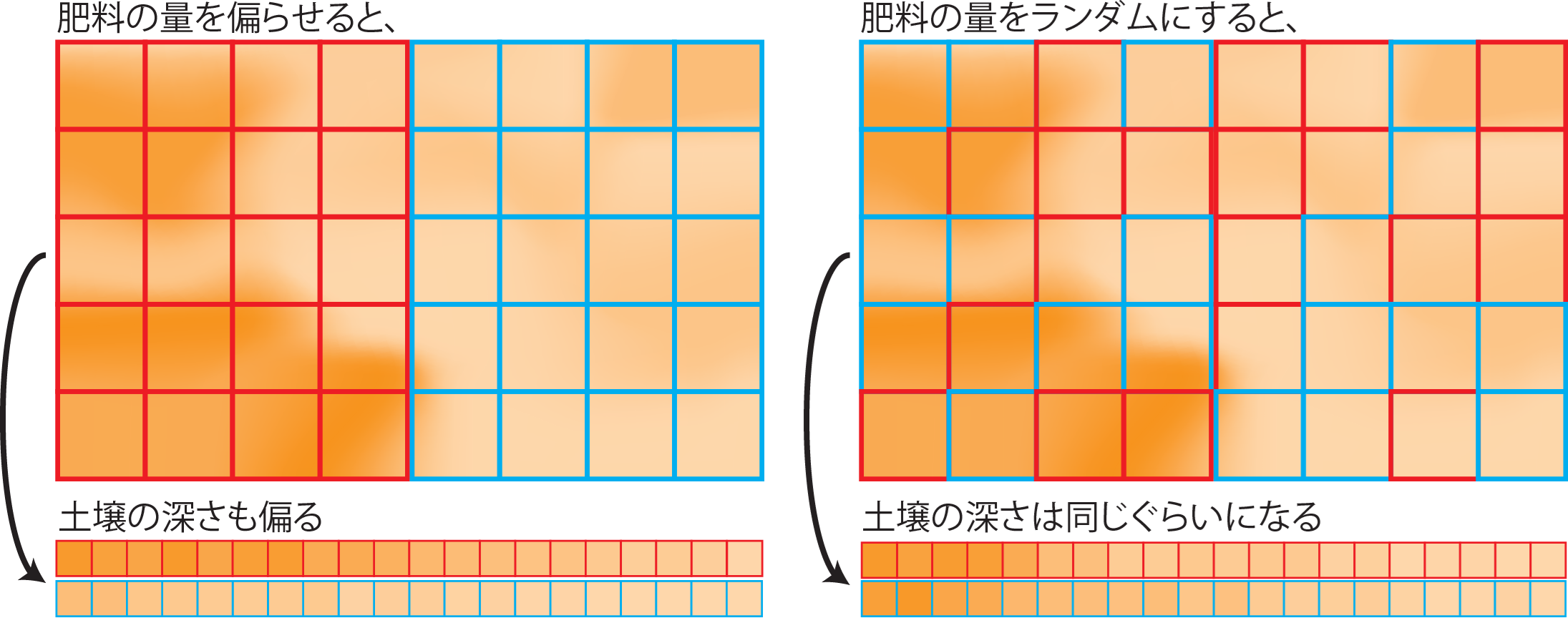
実験では、評価したい項目(目的変数)に影響があるかもしれないけれども、うまく実験に組み込めない要素というものがあります。例えば、肥料が作物の収量に与える影響を評価するときに、土壌の深さや灌漑水路からの距離などの要素は実験の主な目的(肥料と収量の関係)には直接関わりがありませんが、収量には影響を与えるかもしれません。このように、実験の主な目的とは関わらないけれども実験の結果に影響を及ぼしうる要素のことを、共変量(covariates)と呼ぶことがあります。共変量の評価を実験の計画に組み込むことは難しいため、その効果を正確に評価するのは困難です。例えば、土壌の深さや灌漑水路からの距離はその測定や評価が難しく、実験でコントロールすることができません。
肥料(例えば肥料が多い・少ない時)の収量への影響を調べる時に、このような共変量が肥料の多い方、少ない方に偏ってしまうと、肥料の影響で収量が変化したのか、それとも共変量の影響で収量が変化したのか、評価できなくなることがあります。ですので、肥料の多い作物の個体と少ない作物の個体で、共変量の偏りがないようにしないと実験がうまくいきません。
この、共変量の偏りを少なくするための方法が無作為化です。上記の例では、肥料を多く与える作物、少なく与える作物をなるべくランダムな位置に植えることで、窒素の多い方、少ない方で共変量は平均すると概ね均等になります。したがって、無作為化することで共変量の偏りを小さくすることができ、共変量による実験への影響を小さくすることができます。
48.0.3 局所管理(blocking)
局所管理とは、ひとまとめの実験の各セットには、実験に必要となるすべての要素を均等に分配することを指します。
すべての実験を同じ時間や空間で実施することができるとよいのですが、実験にかかる時間や土地の広さなどの制約のため、必ずしもそのような実験を組むことはできません。したがって、実験は数日・数年にわたって行ったり、土地の違う位置を用いて行う必要があります。上記の肥料の影響の実験を数年に分けて行ったり、違う位置で作物を育てた場合、年ごとの違いや土地の位置ごとの違いが結果に影響を及ぼす可能性があります。無作為化で説明したのと同様に、年ごとに肥料が多い、少ないと偏っていたり、土地の西に肥料が多い、東に肥料が少ないなどの傾向があると、肥料の効果のために収量が異なるのか、年・位置の違いのために収量が違うのか、見分けがつかなくなります。
この時間や位置の効果を小さくするために、ある時間、ある位置には、すべての実験の条件を同じ数だけ含めます。つまり、肥料の例であれば同じ時間に肥料を多く与えた作物と少なく与えた作物を同じ数だけ準備します。このように時間・空間ですべての条件を均等に分配して実験を行うことが局所管理です。

48.1 説明変数の数と実験の計画
実験の結果は分散分析や回帰を用いて解析し、説明変数(実験でコントロールする条件)が目的変数(実験の結果)に与える影響を求めます。説明変数と目的変数の関係を分散分析や回帰で求めるためには、その統計手法に適した形の実験を組む必要があります。
48.1.1 説明変数が1つの場合
肥料の量が作物の収量に与える影響について調べたいとしましょう。説明変数が一つ(肥料の量)なら、肥料の多い・少ない環境での作物の収量を評価すれば、肥料の量が収量に与える影響を評価することができます。説明変数が1つで、2条件だけなら、最小の実験の単位は2です。実験の単位が2なので、上記のフィッシャーの3原則:反復に従い実験を繰り返したとしても、それほどたくさんの実験を行うことにはなりません。条件を3条件、4条件にしても、それほど実験の数は必要ないでしょう。
48.1.2 説明変数が2つ以上の場合
実験はシンプルである方が反復を行いやすく、結果の解釈も容易です。しかし、大抵の実験では、説明変数を一つに絞り切れません。例えば、上記の作物の収量であれば、肥料の量だけでなく、日照や水、土壌のpHや土壌の質、肥料の構成など、たくさんの因子の影響を受けます。
説明変数が2つや3つの場合であれば、2元や3元の分散分析で解析することができます。交互作用もそれほど多くありませんし、総当たりの実験を組んだとしても、それほど実験の数は増えないでしょう。
しかし、4つ以上の説明変数の影響を調べる場合、実験は複雑になり、たくさんの実験を行う必要が生じます。説明変数間の交互作用も複雑になり、その理解も難しくなります。ですので、できればあまりたくさんの説明変数を取り扱わず、目的変数(結果)に大きな影響がある説明変数だけを取り扱い、実験を行いたいところです。そのためには、たくさんの説明変数の中から、結果に大きな影響がある説明変数を選び出す必要があります。
このように、たくさんの説明変数の中から、真に目的変数に影響を与えるものを探す試行のことを、スクリーニングと呼びます。以下では、まずこのスクリーニングにおける実験計画を対象として説明を進めていきます。
48.2 スクリーニングにおける説明変数
作物の例でスクリーニングを考えてみましょう。目的変数は作物の収量(重さ)とします。説明変数は肥料の量、日照量、水の量、土壌のpH、土壌の粒の細かさなどです。
説明変数に対して目的変数が線形(直線的)に応答するかわからないため、可能であればそれぞれの説明変数は小さい・中ぐらい・大きいの3条件を用いて実験する方が望ましいです。ただし、実験の条件が増えると行う実験の数も増えます。ですので、スクリーニングでは説明変数の設定は大きい、小さいなどの2条件とします。
また、スクリーニングでは設定した2条件の説明変数は1と-1に正規化します(正規化については30章を参照)。肥料の例であれば、土地1 m2あたりに20 gと5 gの2条件で実験する場合、20 gを1、5 gを-1に置き換えます。このように正規化することで、後の演算を簡単にするとともに、多数の説明変数の間のパラメータ(傾き)を比較しやすくすることができます。
スクリーニング試験の結果から、説明変数からパラメータが大きいもの・パラメータが統計的に有意に0とは異なるものを選び、少ない説明変数をコントロールした、より詳細な実験へと進めていきます。
Tip遺伝子のスクリーニング
生物学では、スクリーニングとは表現形に影響を与える遺伝子を探り出すことを指します。これは数千~数万個の遺伝子、つまり説明変数から、真に表現形(目的変数)に影響を与えるものを見つける、ということです。以下に説明する説明変数のスクリーニングとは方法は異なりますが、いずれもその目的は無数の説明変数から真に目的変数に影響を与えるものを見つけることです。
Tip 48.1: 一般線形モデルの演算
実験計画について説明する前に、実験計画を考えるための基本になる一般線形モデルの演算方法について簡単に説明しておきます。実験計画法のうちOptimal Designと呼ばれる手法には、この演算の一部を理解しておいた方がわかりやすいものがあります。
一般線形モデルは30章で説明した通り、重回帰と分散分析を混ぜたような統計手法です。ですので、重回帰も多元の分散分析も同じ方法で演算できます。
まず、線形のモデルとして、以下の数式のようなものを考えます。
\(x_1\)、\(x_2\)、\(x_3\)はそれぞれ説明変数(上の作物の収量の例での肥料や水、日照量にあたるもの)、\(b\)は切片、\(y\)は目的変数(上の例では収量)、\(a_1\)、\(a_2\)、\(a_3\)はそれぞれの説明変数のパラメータです。ただし、データは正規分布に従いばらつくため、ばらつきを表す項(\(u\))を加えます。\(u\)は平均値0の正規分布に従います。
\[ y = a_1x_1 + a_2x_2 + a_3x_3 + b + u \]
実験を行い、以下のような結果を得たとして、回帰のパラメータ(\(a_1\)、\(a_2\)、\(a_3\)、\(b\))を求めることを考えてみます。以下の例では、8回実験して、\(x_1\)、\(x_2\)、\(x_3\)を各2条件(1と-1)で実験した時のyを表に示しています。
一般線形モデルでは、回帰を行列の式で表します。目的変数yを、yの回帰での推定値と\(u_i\)の和とした以下のような式で表現します。
\[ \begin{pmatrix} 10.56 \\ 6.57\\ 9.03\\ 5.37\\ 5.71\\ 1.36\\ 2.77\\ 0.19 \end{pmatrix} = \begin{pmatrix} 1 \cdot a_1 + 1 \cdot a_2 + 1 \cdot a_3 + 1 \cdot b \\ -1 \cdot a_1 + 1 \cdot a_2 + 1 \cdot a_3 + 1 \cdot b \\ 1 \cdot a_1 -1 \cdot a_2 + 1 \cdot a_3 + 1 \cdot b \\ -1 \cdot a_1 -1 \cdot a_2 + 1 \cdot a_3 + 1 \cdot b \\ 1 \cdot a_1 + 1 \cdot a_2 -1 \cdot a_3 + 1 \cdot b \\ -1 \cdot a_1 + 1 \cdot a_2 -1 \cdot a_3 + 1 \cdot b \\ 1 \cdot a_1 -1 \cdot a_2 -1 \cdot a_3 + 1 \cdot b \\ -1 \cdot a_1 -1 \cdot a_2 -1 \cdot a_3 + 1 \cdot b \\ \end{pmatrix} + \begin{pmatrix} u_1 \\ u_2 \\ u_3 \\ u_4 \\ u_5 \\ u_6 \\ u_7 \\ u_8 \end{pmatrix} \]
ただ、このままでは説明変数とそのパラメータの取り扱いが分かりにくいので、通常は説明変数の行列とパラメータの行列を分けて、以下のような形で表します。
\[ \begin{pmatrix} 10.56 \\ 6.57\\ 9.03\\ 5.37\\ 5.71\\ 1.36\\ 2.77\\ 0.19 \end{pmatrix} = \begin{pmatrix} 1 & 1 & 1 & 1 \\ -1 & 1 & 1 & 1\\ 1 & -1 & 1 & 1 \\ -1 & -1 & 1 & 1 \\ 1 & 1 & -1 & 1 \\ -1 & 1 & -1 & 1 \\ 1 & -1 & -1 & 1 \\ -1 & -1 & -1 & 1 \\ \end{pmatrix} \begin{pmatrix} a_1 \\ a_2 \\ a_3 \\ b \end{pmatrix} + \begin{pmatrix} u_1 \\ u_2 \\ u_3 \\ u_4 \\ u_5 \\ u_6 \\ u_7 \\ u_8 \end{pmatrix} \]
\(u_i\)は平均0、標準偏差\(\sigma\)の正規分布に従います。このとき、\(u_1\)~\(u_n\)はそれぞれ独立(相関を取ると相関係数が0)で、同じ分布(平均0、標準偏差\(\sigma\)の正規分布)を取ると仮定します。この仮定のことをi.i.d(Independent and Identically Distributed)と呼ぶことがあります。
\[ u_i \sim Normal(0, \sigma^2) \]
上の式の目的変数の行列を\(Y\)、説明変数の行列を\(X\)、パラメータの行列を\(\beta\)、ばらつきの項を\(u\)と置き換えると、以下の式で表すことができます。
\[ Y = X \beta + u \]
\(\beta\)の真の値はわからないため、\(\beta\)の予測値(\(\hat{\beta}\)、ベータハット)を\(\beta\)の変わりに用いることにします。また、\(X\)は実験のデザインを表す行列なので、デザイン行列と呼ばれます。
残差(30章のy方向の誤差を参照)は実際の目的変数の値(\(Y\))と\(\hat{\beta}\)を用いた線形モデルで予測した値(\(X\hat{\beta}\))の差なので、以下の式で表すことができます。
\[ Y - X\hat{\beta} \]
最小二乗法では、この残差の2乗和(残差平方和、\(S_e\))を最小にする\(\hat{\beta}\)を求めます。単純に考えると\((Y-X\hat{\beta})^2\)を最小にすればよいのですが、この式は行列なので、2乗にする場合には片方を転置(行と列を反転させること、Rでは16章で説明したt関数で計算)することになります。ですので、以下の式で残差平方和\(S_e\)を表します。
\[ S_e = (Y - X\hat{\beta})^T\cdot(Y-X\hat{\beta}) \]
この式を展開すると以下の式となります。
\[ S_e = Y^TY - Y^TX\hat{\beta}-(X\hat{\beta})^TY + (X\hat{\beta})^TX\hat{\beta} \]
\(S_e\)の式は分かりにくいのですが、真ん中の2つの項はうまくまとめることができます。
上で示した通り、\(X\)は8行4列、\(Y\)は8行1列、\(\hat{\beta}\)は4行1列の行列ですが、一般化して、\(X\)はn行m列、\(Y\)はn行1列、\(\hat{\beta}\)はm行1列としてみます。
\(Y\)はn行1列の行列、\(X\)はn行m列の行列、\(\hat{\beta}\)はm行1列の行列なので、\(Y^TX\hat{\beta}\)のうち、\(Y^TX\)は1行m列の行列、\(Y^TX\hat{\beta}\)は1行m列の行列とm行1列の行列の積で、数値(スカラー)になります。
また、 \((X\hat{\beta})^TY\)のうち、\(X\hat{\beta}\)はn行1列、\((X\hat{\beta})^TY\)は1行n列の行列とn行1列の行列の積で、\(Y^TX\hat{\beta}\)と同様に数値(スカラー)となります(また、\(S_e\)が数値なので、\(S_e\)の式のすべての項は数値になります)。数値は1行1列の行列なので、転置しても値は変わりません。
また、転置の性質(\((AB)^T=B^TA^T\))より、\((X\hat{\beta})^TY\)を転置すると、\(Y^TX\hat{\beta}\)になります。
\(((X\hat{\beta})^TY)^T = Y^TX\hat{\beta}\)
ですので、\(Y^TX\hat{\beta}\)と\((X\hat{\beta})^TY\)は転置すると一致し、共に数値なので等しくなります。
\[ Y^TX\hat{\beta} = (X\hat{\beta})^TY \]
従って、残差平方和\(S_e\)は以下の式で表すことができます。
\[ S_e = Y^TY - 2(X\hat{\beta})^TY + (X\hat{\beta})^TX\hat{\beta} \]
\(S_e\)を最小化する、つまり二乗誤差(残差平方和)を最小とする\(\hat{\beta}\)を求めるには、\(S_e\)を\(\hat{\beta}\)で偏微分し、微分値が0となる\(\hat{\beta}\)を求めればよいので、\(S_e\)を\(\hat{\beta}\)で偏微分します。
\(S_e\)を\(\hat{\beta}\)で偏微分(\(\frac{\partial S_e}{\partial \hat{\beta}}\))する演算は、行列の微分となるため分かりにくいのですが、概ね通常の微分と同じように計算することができ、以下の式となります。
\[ \frac{\partial S_e}{\partial \hat{\beta}} = -2X^TY + 2X^TX\hat{\beta} \]
\(\frac{\partial S_e}{\partial \hat{\beta}}=0\)となる\(\hat{\beta}\)を求めるには、以下の式を\(\hat{\beta}\)について解くことになります。
\[ -2X^TY + 2X^TX\hat{\beta} = 0 \]
この方程式を解くと、\(\hat{\beta}\)は以下の式として求まることになります。
\[ \hat{\beta} = (X^TX)^{-1}X^TY \]
\((X^TX)^{-1}\)は\(X^TX\)の逆行列です。逆行列と元の行列の積は単位行列になります(\(AA^{-1}=I\))。16章で説明した通り、逆行列の演算はsolve関数、転置はt関数で演算できますので、上記の\(\hat{\beta}\)の演算は以下のスクリプトで実行できます。
演算結果はlm関数で回帰した場合と同じとなります。
線形回帰の結果
lm(y ~ x$x1 + x$x2 + x$x3)
Call:
lm(formula = y ~ x$x1 + x$x2 + x$x3)
Coefficients:
(Intercept) x$x1 x$x2 x$x3
5.1475 1.8700 0.9025 2.7350 また、\(\hat{\beta}\)のばらつき(\(\hat{\beta}\)の分散共分散行列、\(Cov(\hat{\beta})\))は以下の式で表されます。
\[ Cov(\hat{\beta}) = E|(\hat{\beta}-\beta)(\hat{\beta}-\beta)^T| = \sigma^2(X^TX)^{-1} \]
このとき、\(\sigma\)は\(u_i \sim Normal(0, \sigma^2)\)であり、\(\sigma\)の真の値は分からないので、\(\sigma^2\)の推定値(\(\hat{\sigma}^2\))を以下の式から演算します。\(n\)はデータ数、\(k\)はパラメータの数です。
\[ \hat{\sigma}^2 = \frac{1}{n-k}S_e \]
48.2.1 交互作用
29章で説明した交互作用は、デザイン行列\(X\)に交互作用の列を追加したものになります。交互作用は説明変数同士の掛け算になります。
交互作用のデザイン行列
| x1 | x2 | x3 | x1x2 | x1x3 | x2x3 | x1x2x3 | b |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| -1 | 1 | 1 | -1 | -1 | 1 | -1 | 1 |
| 1 | -1 | 1 | -1 | 1 | -1 | -1 | 1 |
| -1 | -1 | 1 | 1 | -1 | -1 | 1 | 1 |
| 1 | 1 | -1 | 1 | -1 | -1 | -1 | 1 |
| -1 | 1 | -1 | -1 | 1 | -1 | 1 | 1 |
| 1 | -1 | -1 | -1 | -1 | 1 | 1 | 1 |
| -1 | -1 | -1 | 1 | 1 | 1 | -1 | 1 |
交互作用があっても、\((X^TX)^{-1}X^TY\)で回帰の計算を行うことができます。
[,1]
x1 1.8700
x2 0.9025
x3 2.7350
x1x2 0.2150
x1x3 0.0425
x2x3 -0.2200
x1x2x3 -0.1325
b 5.1475結果は交互作用ありの線形回帰と一致します。
交互作用ありの線形モデルの計算
lm(y ~ x$x1 * x$x2 * x$x3)
Call:
lm(formula = y ~ x$x1 * x$x2 * x$x3)
Coefficients:
(Intercept) x$x1 x$x2 x$x3 x$x1:x$x2
5.1475 1.8700 0.9025 2.7350 0.2150
x$x1:x$x3 x$x2:x$x3 x$x1:x$x2:x$x3
0.0425 -0.2200 -0.1325 48.2.2 多項式回帰と多重共線性
多項式回帰は、説明変数の2乗や3乗を説明変数に加えた回帰の方法です。こちらも交互作用ありの回帰と同様にデザイン行列に説明変数の2乗や3乗の列を追加したものになります。
多項式の行をデザイン行列に追加する
| x1 | x2 | x3 | x1x1 | b |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 |
| -1 | 1 | 1 | 1 | 1 |
| 1 | -1 | 1 | 1 | 1 |
| -1 | -1 | 1 | 1 | 1 |
| 1 | 1 | -1 | 1 | 1 |
| -1 | 1 | -1 | 1 | 1 |
| 1 | -1 | -1 | 1 | 1 |
| -1 | -1 | -1 | 1 | 1 |
ただし、x1の2乗の項が含まれているなら、回帰の結果は2次関数のような曲線になるはずですが、x1は-1と1の2つの値しか取っていないため、このデータではyとx1の関係について、どのように曲がっているのかはわかりません。つまり、2点では多項式のパラメータは求まりそうにありません。
実際にこの多項式を入れた場合のデザイン行列を見ると、x1x1の列とbの列の値が同じになっています。このような場合には\((X^TX)^{-1}X^TY\)が計算できなくなります。
Error in `solve.default()`:
! Lapack routine dgesv: system is exactly singular: U[5,5] = 0\((X^TX)^{-1}X^TY\)が計算できないのは、\(X^TX\)の逆行列が計算できなくなる(\(X^TX\)が正則行列ではない)ためです。
Error in `solve.default()`:
! Lapack routine dgesv: system is exactly singular: U[5,5] = 0実際にlm関数で計算しても、結果が求まりません。
回帰が求まらない例
lm(y = x$x1 + x$x2 + x$x3 + x$x1^2)Error in `terms.formula()`:
! argument is not a valid modelですので、\(X^TX\)の逆行列が求まらない場合には、重回帰の演算ができなくなります。上記の場合のように、x1x1とbが同じ、つまり完全に相関している場合は、30章で説明した多重共線性の問題に相当します。また、x1x1とbの関係のように、説明変数や交互作用の間で列の値が同じになる関係のことを、エイリアス(aliase、別名関係)と呼びます。
48.3 要因配置計画(factorial design)
説明変数が2つ以上の場合、例えば、作物の収量に影響を与えるものとして、肥料の量、水の量を調べる場合の実験について考えます。肥料の量を2条件(nutrient、1と-1)、水の量を2条件(water、1と-1)で実験を行い、以下のように収量(weight)を得たとします。
データの準備
# seed_weight関数を以下のように定義する
seed_weightfunction (nutrient, water, light = 1)
{
1.5 * nutrient + 1.1 * water - 0.3 * nutrient * water + 2 *
light + rnorm(length(nutrient), 5, 1)
}d <- data.frame(
nutrient = c(-1, 1, -1, 1),
water = c(1, 1, -1, -1)
) |>
mutate(weight = seed_weight(nutrient, water))
knitr::kable(d)| nutrient | water | weight |
|---|---|---|
| -1 | 1 | 6.894233 |
| 1 | 1 | 11.704653 |
| -1 | -1 | 4.863594 |
| 1 | -1 | 6.900991 |
上記の通り、肥料と水を2条件ずつで実験する場合、行う実験の単位は「肥料の2条件×水の2条件」で4条件となります。つまり、総当たりの実験を行うことになります。
同様に、もう一つ説明変数、例えば日照量を加えるとすると、日照量を2条件(1と-1)追加した実験を行うことになります。この場合には、肥料、水、日照量に関して各2条件について総当たりの実験をすることになります。このように総当たりの実験を行う実験計画のことを、要因配置計画(factorial design)と呼びます。
要因配置計画のデータフレームを作成する時には、16章で説明したexpand.grid関数や20章で説明したtidyr::expand関数を用いるとよいでしょう。
expand.grid関数で要因配置計画を設計
expand.grid(nutrient = c(1, -1), water = c(1, -1), light = c(1, -1)) nutrient water light
1 1 1 1
2 -1 1 1
3 1 -1 1
4 -1 -1 1
5 1 1 -1
6 -1 1 -1
7 1 -1 -1
8 -1 -1 -148.3.1 要因配置計画と分散分析
要因配置計画を用いて実験を行い、結果を取得したら、どの説明変数がどの程度目的変数に影響するかを評価するために、29章で説明した分散分析や30章で説明した重回帰で解析します。Rでは多元の分散分析も重回帰もlm関数で計算することができます。要因配置計画では、それぞれの説明変数の効果(パラメータ、傾き)と、交互作用の効果を評価することができます。
要因配置計画を分析する
lm(weight ~ nutrient * water, data = d)
Call:
lm(formula = weight ~ nutrient * water, data = d)
Coefficients:
(Intercept) nutrient water nutrient:water
7.5909 1.7120 1.7086 0.6933 48.3.2 要因配置計画からデータを減らす
とは言え、要因配置計画は総当たりですので、説明変数が増えると実験の数が増えていきます。スクリーニング実験では、説明変数が2つの時は22で4、3つの時は23で8の実験が必要となります。一般化すると、各説明変数に2条件を設定し、n個の説明変数を評価したい場合、2nの実験が必要となります。したがって、説明変数が増えると指数的に実験の数が増えていくことになります。実験には時間とお金がかかるため、できれば要因配置計画より少なめの実験で結果が得たいところです。
では、上に示した肥料と水の要因配置計画から、データを減らしてみましょう。まずは1つデータを削除した場合のlm関数の結果を見てみます。データを1つ削除すると、肥料(nutrient)と水(water)の主効果(傾き)、切片(intercept)は求まりますが、交互作用(nutrient:water)が求まらなくなります。
要因配置計画からデータを減らしてみる
lm(weight ~ nutrient * water, data = d[1:3, ]) # 4行目を削除する
Call:
lm(formula = weight ~ nutrient * water, data = d[1:3, ])
Coefficients:
(Intercept) nutrient water nutrient:water
8.284 2.405 1.015 NA 次に、2つのデータを削除してみます。2つ削除した場合には、以下のように肥料(nutrient)の主効果だけが求まる場合と、水(water)の主効果だけが求まる場合の2パターンが生じます。
d[1:2, ] # 3、4行目を削除する nutrient water weight
1 -1 1 6.894233
2 1 1 11.704653lm(weight ~ nutrient * water, data = d[1:2, ])
Call:
lm(formula = weight ~ nutrient * water, data = d[1:2, ])
Coefficients:
(Intercept) nutrient water nutrient:water
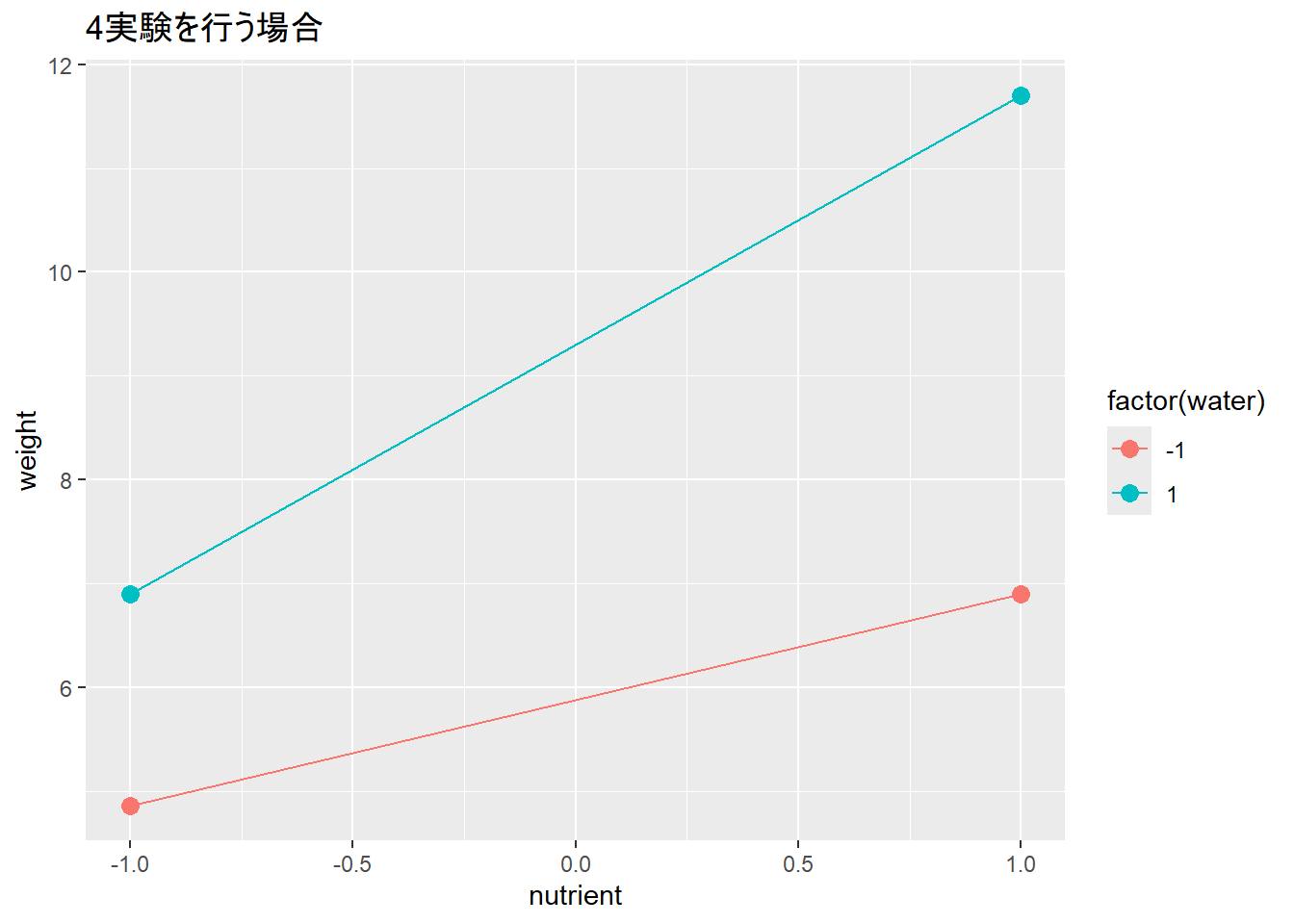
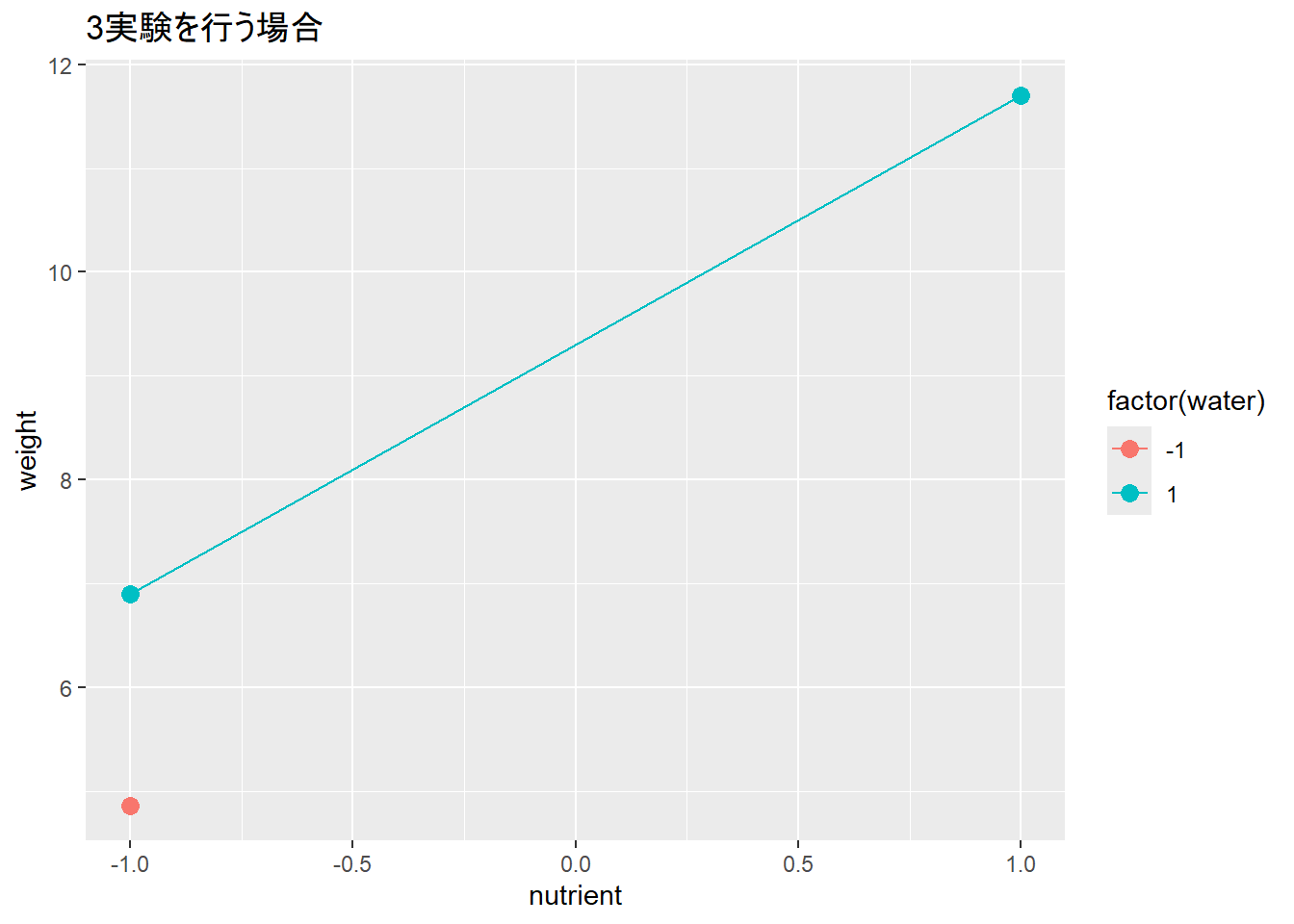
9.299 2.405 NA NA なぜデータを減らすと求まるパラメータが変わるのかは、データをグラフに示してみるとわかります。パラメータは傾き(横軸:nutrient)か、線のシフト(青と赤の線の幅:water)として計算されます。また、交互作用は青と赤の線の傾きの差です。
点(データ)が4つあると、傾きも線のシフトも、傾きの差も評価できます。点が3つになると、傾きと線のシフトは計算できますが、傾きの差は線が2本ないため評価できなくなります。点が2つになると、傾きかシフトのいずれかだけが計算できます。ですので、データが減れば求まるパラメータが変わっていくことになります。
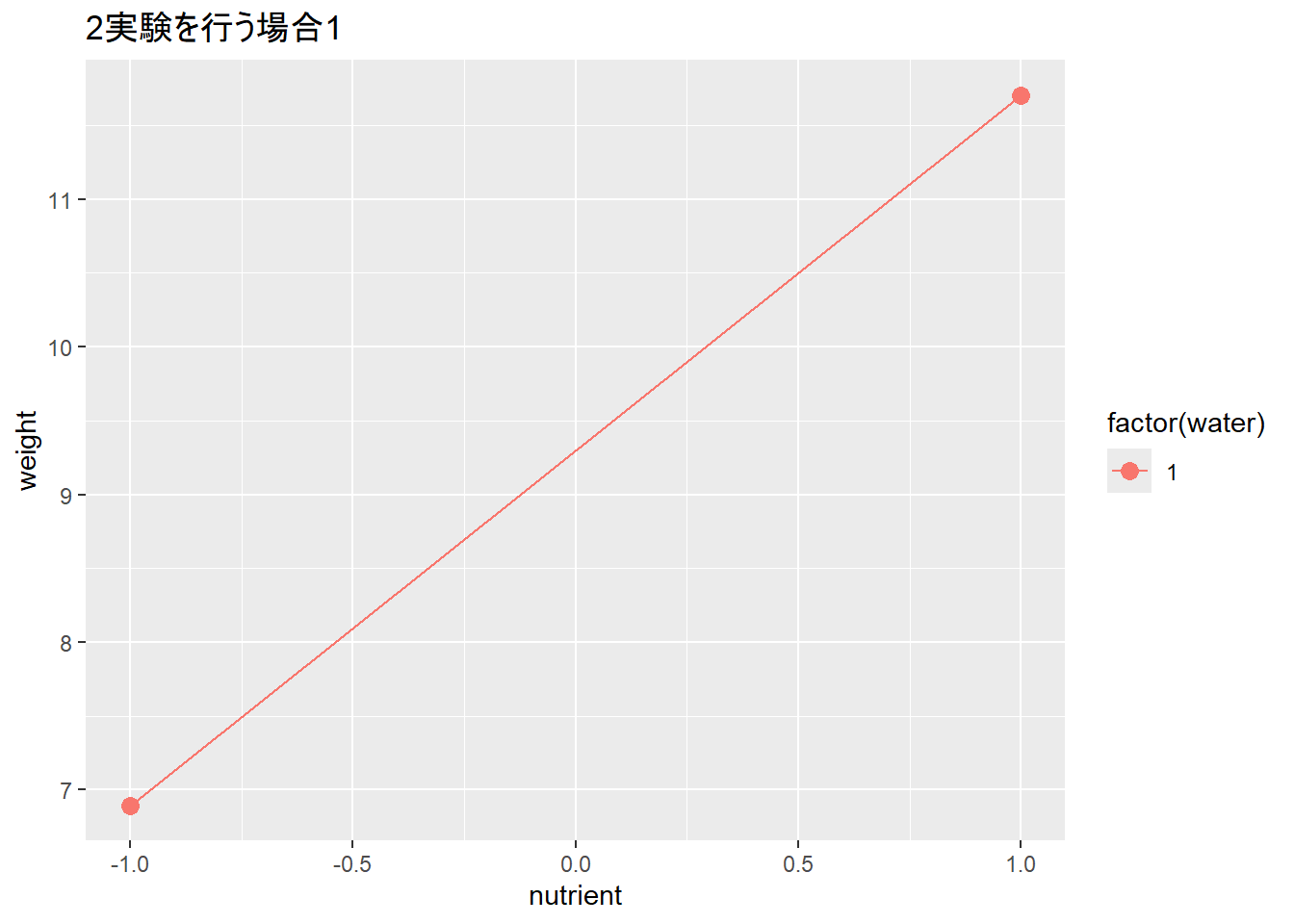
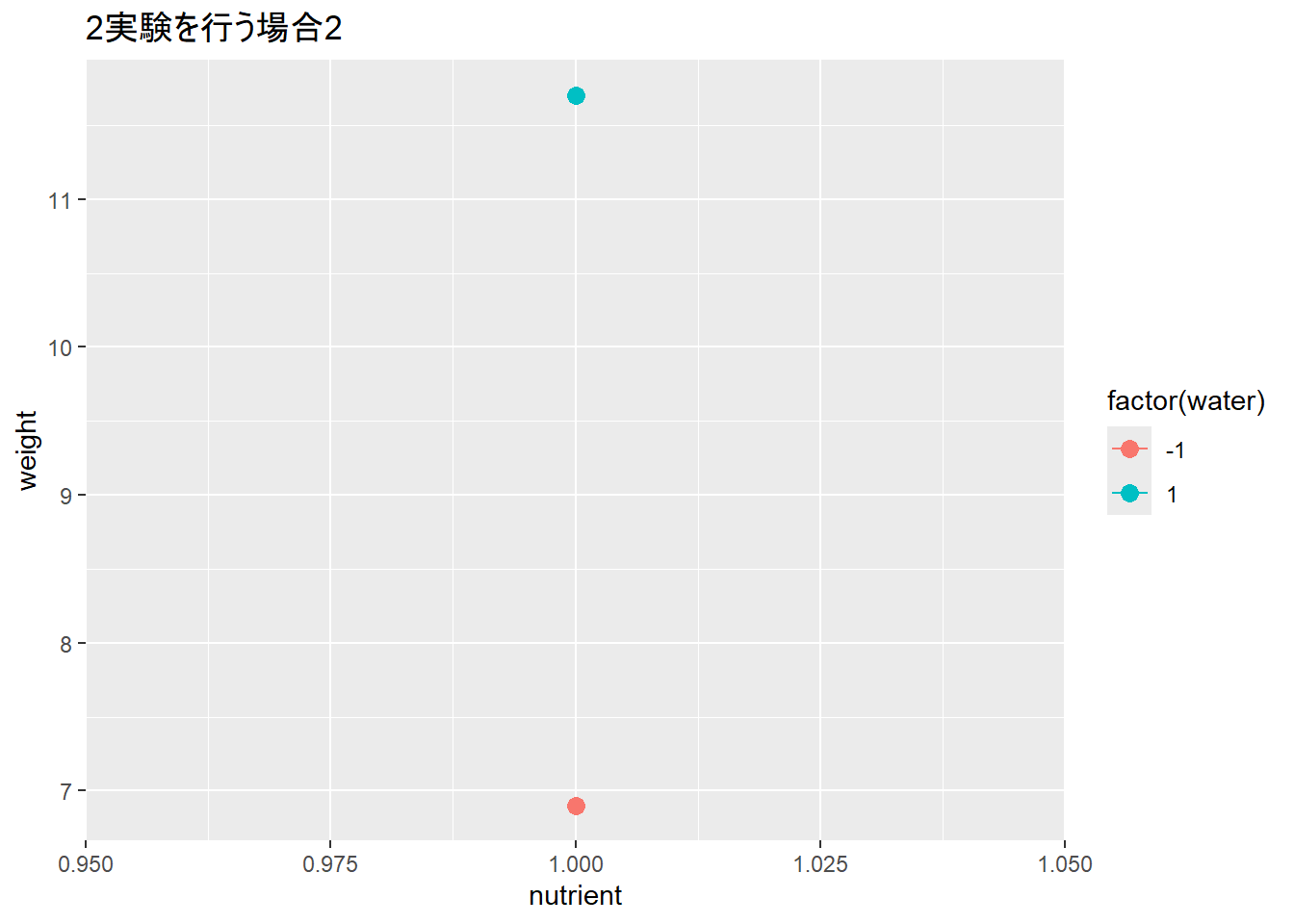
48.3.3 パラメータの標準誤差の計算
4つのデータで4つのパラメータ(説明変数2つの傾き、交互作用1つ、切片1つ)を求めると、標準誤差が求まらなくなります。これは、下の演算の結果に示されている通り、残差の自由度が0になるからです。
Call:
lm(formula = weight ~ nutrient * water, data = d)
Residuals:
ALL 4 residuals are 0: no residual degrees of freedom!
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.5909 NaN NaN NaN
nutrient 1.7120 NaN NaN NaN
water 1.7086 NaN NaN NaN
nutrient:water 0.6933 NaN NaN NaN
Residual standard error: NaN on 0 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: NaN
F-statistic: NaN on 3 and 0 DF, p-value: NA要因配置計画でも、主効果のみを計算すると、交互作用に割り振る自由度がなくなり、自由度に余裕ができるので標準誤差が求まります。
Call:
lm(formula = weight ~ nutrient + water, data = d)
Residuals:
1 2 3 4
-0.6933 0.6933 0.6933 -0.6933
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.5909 0.6933 10.950 0.058 .
nutrient 1.7120 0.6933 2.469 0.245
water 1.7086 0.6933 2.465 0.245
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.387 on 1 degrees of freedom
Multiple R-squared: 0.9241, Adjusted R-squared: 0.7722
F-statistic: 6.086 on 2 and 1 DF, p-value: 0.2755また、要因配置計画を2回繰り返すと交互作用を含めても標準誤差が求まるようになります。
要因配置計画を2回繰り返す
Call:
lm(formula = weight ~ nutrient * water, data = d2)
Residuals:
1 2 3 4 5 6 7 8
-0.6999 0.3012 -0.3674 0.4130 0.6999 -0.3012 0.3674 -0.4130
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.0682 0.4707 15.016 0.000115 ***
nutrient 0.6072 0.6657 0.912 0.413261
water 0.5840 0.6657 0.877 0.429820
nutrient:water 0.4498 0.9414 0.478 0.657746
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.6657 on 4 degrees of freedom
Multiple R-squared: 0.6119, Adjusted R-squared: 0.3209
F-statistic: 2.102 on 3 and 4 DF, p-value: 0.2427
Tip自由度と分散
上の一般線形モデルの計算に関するcallout(Tip 48.1)で説明した通り、一般線形モデルの分散の推定値を示す\(\hat{\sigma}^2\)は以下の式で求まります。\(n\)はデータ数、\(k\)はパラメータの数です。
\[ \hat{\sigma}^2 = \frac{1}{n-k}S_e \]
2つの説明変数に各2条件の要因配置計画の実験、4条件の実験を行ったとします。\(n\)は実験の数で4、\(k\)はパラメータ、つまり説明変数や交互作用の傾き、切片の数です。2つの説明変数の場合、各説明変数の傾きで2個、交互作用で1個、切片で1個ですので、パラメータ\(k\)は4です。上の式より、右辺の分母は自由度\(n-k\)、つまり0となるため、\(\hat{\sigma}^2\)は計算できなくなります。
48.3.4 データの数と結果の正確さ
実験数(データ)を増やせば、求まるパラメータ(傾き)は正確になっていきます。また、大きな交互作用がある場合には、要因配置計画からデータを減らすと主効果(説明変数)の正確な傾きは求まらなくなります。
| 2データの回帰 | 3データの回帰 | 要因配置計画 | 要因配置計画×2 | 要因配置計画×5 | 真の値 | |
|---|---|---|---|---|---|---|
| (Intercept) | 9.299443 | 8.284123 | 7.5908676 | 7.0682341 | 7.2602588 | 5.0 |
| nutrient | 2.405210 | 2.405210 | 1.7119545 | 0.6072413 | 0.9456713 | 1.5 |
| water | NA | 1.015320 | 1.7085755 | 0.5840491 | 0.9950202 | 1.1 |
| nutrient:water | NA | NA | 0.6932558 | 0.4497841 | -0.0295328 | -0.3 |
48.4 一部要因配置計画(fractional factorial design)
上記の通り、交互作用を含めたすべてのパラメータを計算する場合には、要因配置計画の実験が必要となります。ただし、交互作用を評価せず、説明変数の主効果だけを評価する場合には、実験を減らすことができます。とは言え、データを減らす場合には、要因配置計画からどの実験を削ることができるのかわからないと、実験を削ることはできません。
実験数を減らす方法の一つが一部要因配置計画(fractional factorial design)です。一部要因配置計画は要因配置計画(総当たり)から実験を適切に減らすことで、少ない実験回数で分散分析で評価できるようにすることができる実験計画の手法です。一部要因配置計画は、基本的にはスクリーニングのような1説明変数に2条件の実験に適用します。
Rでは、FrF2パッケージ(Groemping 2025, 2014)のFrF2関数を用いることで、一部要因配置計画の実験デザインを作成することができます。以下の例では、3つの説明変数(nutrient、water、light)を用いて、4実験の一部要因配置計画をFrF2関数で作成しています。FrF2関数の第1引数は実験数(nruns)、第2引数は説明変数の数(nfactors)、第3引数は説明変数の名前(factor.names)です。
FrF2関数で一部要因配置計画
nutrient water light
1 1 -1 -1
2 1 1 1
3 -1 1 -1
4 -1 -1 1
class=design, type= FrF2 # factorを数値のデータフレームに変換しておく
ffd <- ffd |> map(as.character) |> map(as.numeric) |> as.data.frame() 一部要因配置計画を分散分析に当てはめると、上の例(説明変数3つ、各2条件、実験数4)であれば交互作用が求まりませんが、各説明変数の主効果(傾き、パラメータ)は評価することができます。
一部要因配置計画を分散分析する
y_ffd <- seed_weight(ffd$nutrient, ffd$water, ffd$light)
lm(y_ffd ~ ffd$nutrient * ffd$water * ffd$light)
Call:
lm.default(formula = y_ffd ~ ffd$nutrient * ffd$water * ffd$light)
Coefficients:
(Intercept) ffd$nutrient
5.346 1.623
ffd$water ffd$light
1.128 2.008
ffd$nutrient:ffd$water ffd$nutrient:ffd$light
NA NA
ffd$water:ffd$light ffd$nutrient:ffd$water:ffd$light
NA NA 説明変数が3つぐらいだと一部要因配置計画の恩恵は大きくないですが、説明変数がより多くなっていくと実験数をかなり少なくすることができるようになります。以下の例では、説明変数が8つの場合を示しています。各説明変数と2次の交互作用(説明変数2つずつの交互作用)のパラメータを求めたいだけであれば、要因配置計画(28=256実験)を行う必要はなく、16実験で計算できます。
Tip一部要因配置計画の実験数とパラメータの関係(説明変数8つの場合、結果が長いので折りたたんで表示)
5次の交互作用のパラメータまで求まる
一部要因配置計画:説明変数が8つ、128実験の場合
e128 <- FrF2(128, 8)
lm(rep(1, 128) ~ e128$A * e128$B * e128$C * e128$D * e128$E * e128$F * e128$G * e128$H) |>
_$coef |>
as.data.frame() |>
na.omit() |>
rownames() [1] "(Intercept)" "e128$A1"
[3] "e128$B1" "e128$C1"
[5] "e128$D1" "e128$E1"
[7] "e128$F1" "e128$G1"
[9] "e128$H1" "e128$A1:e128$B1"
[11] "e128$A1:e128$C1" "e128$B1:e128$C1"
[13] "e128$A1:e128$D1" "e128$B1:e128$D1"
[15] "e128$C1:e128$D1" "e128$A1:e128$E1"
[17] "e128$B1:e128$E1" "e128$C1:e128$E1"
[19] "e128$D1:e128$E1" "e128$A1:e128$F1"
[21] "e128$B1:e128$F1" "e128$C1:e128$F1"
[23] "e128$D1:e128$F1" "e128$E1:e128$F1"
[25] "e128$A1:e128$G1" "e128$B1:e128$G1"
[27] "e128$C1:e128$G1" "e128$D1:e128$G1"
[29] "e128$E1:e128$G1" "e128$F1:e128$G1"
[31] "e128$A1:e128$H1" "e128$B1:e128$H1"
[33] "e128$C1:e128$H1" "e128$D1:e128$H1"
[35] "e128$E1:e128$H1" "e128$F1:e128$H1"
[37] "e128$G1:e128$H1" "e128$A1:e128$B1:e128$C1"
[39] "e128$A1:e128$B1:e128$D1" "e128$A1:e128$C1:e128$D1"
[41] "e128$B1:e128$C1:e128$D1" "e128$A1:e128$B1:e128$E1"
[43] "e128$A1:e128$C1:e128$E1" "e128$B1:e128$C1:e128$E1"
[45] "e128$A1:e128$D1:e128$E1" "e128$B1:e128$D1:e128$E1"
[47] "e128$C1:e128$D1:e128$E1" "e128$A1:e128$B1:e128$F1"
[49] "e128$A1:e128$C1:e128$F1" "e128$B1:e128$C1:e128$F1"
[51] "e128$A1:e128$D1:e128$F1" "e128$B1:e128$D1:e128$F1"
[53] "e128$C1:e128$D1:e128$F1" "e128$A1:e128$E1:e128$F1"
[55] "e128$B1:e128$E1:e128$F1" "e128$C1:e128$E1:e128$F1"
[57] "e128$D1:e128$E1:e128$F1" "e128$A1:e128$B1:e128$G1"
[59] "e128$A1:e128$C1:e128$G1" "e128$B1:e128$C1:e128$G1"
[61] "e128$A1:e128$D1:e128$G1" "e128$B1:e128$D1:e128$G1"
[63] "e128$C1:e128$D1:e128$G1" "e128$A1:e128$E1:e128$G1"
[65] "e128$B1:e128$E1:e128$G1" "e128$C1:e128$E1:e128$G1"
[67] "e128$D1:e128$E1:e128$G1" "e128$A1:e128$F1:e128$G1"
[69] "e128$B1:e128$F1:e128$G1" "e128$C1:e128$F1:e128$G1"
[71] "e128$D1:e128$F1:e128$G1" "e128$E1:e128$F1:e128$G1"
[73] "e128$A1:e128$B1:e128$H1" "e128$A1:e128$C1:e128$H1"
[75] "e128$B1:e128$C1:e128$H1" "e128$A1:e128$D1:e128$H1"
[77] "e128$B1:e128$D1:e128$H1" "e128$C1:e128$D1:e128$H1"
[79] "e128$A1:e128$E1:e128$H1" "e128$B1:e128$E1:e128$H1"
[81] "e128$C1:e128$E1:e128$H1" "e128$D1:e128$E1:e128$H1"
[83] "e128$A1:e128$F1:e128$H1" "e128$B1:e128$F1:e128$H1"
[85] "e128$C1:e128$F1:e128$H1" "e128$D1:e128$F1:e128$H1"
[87] "e128$E1:e128$F1:e128$H1" "e128$A1:e128$G1:e128$H1"
[89] "e128$B1:e128$G1:e128$H1" "e128$C1:e128$G1:e128$H1"
[91] "e128$D1:e128$G1:e128$H1" "e128$E1:e128$G1:e128$H1"
[93] "e128$F1:e128$G1:e128$H1" "e128$A1:e128$B1:e128$C1:e128$D1"
[95] "e128$A1:e128$B1:e128$C1:e128$E1" "e128$A1:e128$B1:e128$D1:e128$E1"
[97] "e128$A1:e128$C1:e128$D1:e128$E1" "e128$B1:e128$C1:e128$D1:e128$E1"
[99] "e128$A1:e128$B1:e128$C1:e128$F1" "e128$A1:e128$B1:e128$D1:e128$F1"
[101] "e128$A1:e128$C1:e128$D1:e128$F1" "e128$B1:e128$C1:e128$D1:e128$F1"
[103] "e128$A1:e128$B1:e128$E1:e128$F1" "e128$A1:e128$C1:e128$E1:e128$F1"
[105] "e128$B1:e128$C1:e128$E1:e128$F1" "e128$A1:e128$D1:e128$E1:e128$F1"
[107] "e128$B1:e128$D1:e128$E1:e128$F1" "e128$C1:e128$D1:e128$E1:e128$F1"
[109] "e128$A1:e128$B1:e128$C1:e128$G1" "e128$A1:e128$B1:e128$D1:e128$G1"
[111] "e128$A1:e128$C1:e128$D1:e128$G1" "e128$B1:e128$C1:e128$D1:e128$G1"
[113] "e128$A1:e128$B1:e128$E1:e128$G1" "e128$A1:e128$C1:e128$E1:e128$G1"
[115] "e128$B1:e128$C1:e128$E1:e128$G1" "e128$A1:e128$D1:e128$E1:e128$G1"
[117] "e128$B1:e128$D1:e128$E1:e128$G1" "e128$C1:e128$D1:e128$E1:e128$G1"
[119] "e128$A1:e128$B1:e128$F1:e128$G1" "e128$A1:e128$C1:e128$F1:e128$G1"
[121] "e128$B1:e128$C1:e128$F1:e128$G1" "e128$A1:e128$D1:e128$F1:e128$G1"
[123] "e128$B1:e128$D1:e128$F1:e128$G1" "e128$C1:e128$D1:e128$F1:e128$G1"
[125] "e128$A1:e128$E1:e128$F1:e128$G1" "e128$B1:e128$E1:e128$F1:e128$G1"
[127] "e128$C1:e128$E1:e128$F1:e128$G1" "e128$D1:e128$E1:e128$F1:e128$G1"4次の交互作用のパラメータまで求まる
一部要因配置計画:説明変数が8つ、64実験の場合
e64 <-FrF2(64, 8)
lm(rep(1, 64) ~ e64$A * e64$B * e64$C * e64$D * e64$E * e64$F * e64$G * e64$H) |>
_$coef |>
as.data.frame() |>
na.omit() |>
rownames() [1] "(Intercept)" "e64$A1" "e64$B1"
[4] "e64$C1" "e64$D1" "e64$E1"
[7] "e64$F1" "e64$G1" "e64$H1"
[10] "e64$A1:e64$B1" "e64$A1:e64$C1" "e64$B1:e64$C1"
[13] "e64$A1:e64$D1" "e64$B1:e64$D1" "e64$C1:e64$D1"
[16] "e64$A1:e64$E1" "e64$B1:e64$E1" "e64$C1:e64$E1"
[19] "e64$D1:e64$E1" "e64$A1:e64$F1" "e64$B1:e64$F1"
[22] "e64$C1:e64$F1" "e64$D1:e64$F1" "e64$E1:e64$F1"
[25] "e64$A1:e64$G1" "e64$B1:e64$G1" "e64$C1:e64$G1"
[28] "e64$D1:e64$G1" "e64$E1:e64$G1" "e64$F1:e64$G1"
[31] "e64$A1:e64$H1" "e64$B1:e64$H1" "e64$C1:e64$H1"
[34] "e64$D1:e64$H1" "e64$E1:e64$H1" "e64$F1:e64$H1"
[37] "e64$G1:e64$H1" "e64$A1:e64$C1:e64$E1" "e64$B1:e64$C1:e64$E1"
[40] "e64$A1:e64$D1:e64$E1" "e64$B1:e64$D1:e64$E1" "e64$C1:e64$D1:e64$E1"
[43] "e64$A1:e64$C1:e64$F1" "e64$B1:e64$C1:e64$F1" "e64$A1:e64$D1:e64$F1"
[46] "e64$B1:e64$D1:e64$F1" "e64$C1:e64$D1:e64$F1" "e64$C1:e64$E1:e64$F1"
[49] "e64$D1:e64$E1:e64$F1" "e64$A1:e64$E1:e64$G1" "e64$B1:e64$E1:e64$G1"
[52] "e64$C1:e64$E1:e64$G1" "e64$D1:e64$E1:e64$G1" "e64$A1:e64$F1:e64$G1"
[55] "e64$B1:e64$F1:e64$G1" "e64$C1:e64$F1:e64$G1" "e64$D1:e64$F1:e64$G1"
[58] "e64$E1:e64$F1:e64$G1" "e64$A1:e64$C1:e64$H1" "e64$B1:e64$C1:e64$H1"
[61] "e64$A1:e64$D1:e64$H1" "e64$B1:e64$D1:e64$H1" "e64$A1:e64$G1:e64$H1"
[64] "e64$B1:e64$G1:e64$H1"3次の交互作用のパラメータまで求まる
一部要因配置計画:説明変数が8つ、32実験の場合
e32 <-FrF2(32, 8)
lm(rep(1, 32) ~ e32$A * e32$B * e32$C * e32$D * e32$E * e32$F * e32$G * e32$H) |>
_$coef |>
as.data.frame() |>
na.omit() |>
rownames() [1] "(Intercept)" "e32$A1" "e32$B1"
[4] "e32$C1" "e32$D1" "e32$E1"
[7] "e32$F1" "e32$G1" "e32$H1"
[10] "e32$A1:e32$B1" "e32$A1:e32$C1" "e32$B1:e32$C1"
[13] "e32$A1:e32$D1" "e32$B1:e32$D1" "e32$C1:e32$D1"
[16] "e32$A1:e32$E1" "e32$B1:e32$E1" "e32$C1:e32$E1"
[19] "e32$D1:e32$E1" "e32$D1:e32$F1" "e32$E1:e32$F1"
[22] "e32$E1:e32$G1" "e32$A1:e32$H1" "e32$B1:e32$H1"
[25] "e32$C1:e32$H1" "e32$D1:e32$H1" "e32$E1:e32$H1"
[28] "e32$F1:e32$H1" "e32$G1:e32$H1" "e32$B1:e32$C1:e32$D1"
[31] "e32$A1:e32$B1:e32$E1" "e32$A1:e32$B1:e32$H1"2次の交互作用のパラメータまで求まる
一部要因配置計画:説明変数が8つ、16実験の場合
e16 <-FrF2(16, 8)
lm(rep(1, 16) ~ e16$A * e16$B * e16$C * e16$D * e16$E * e16$F * e16$G * e16$H) |>
_$coef |>
as.data.frame() |>
na.omit() |>
rownames() [1] "(Intercept)" "e16$A1" "e16$B1" "e16$C1"
[5] "e16$D1" "e16$E1" "e16$F1" "e16$G1"
[9] "e16$H1" "e16$A1:e16$B1" "e16$A1:e16$C1" "e16$B1:e16$C1"
[13] "e16$A1:e16$D1" "e16$B1:e16$D1" "e16$C1:e16$D1" "e16$D1:e16$E1"実験数8だと一部要因配置計画の計算ができない。
一部要因配置計画:説明変数が8つ、8実験の場合
FrF2(8, 8)Error in `FrF2()`:
! You can accomodate at most 7 factors in a FrF2 design with 8 runs.
Tip一部要因配置計画と直交表
一部要因配置計画(fractional factorial design)は直交表(orthogonal design)というものを用いて作成します。直交表はデザイン行列であり、2乗したとき(直交表のデザイン行列を\(X\)としたとき、\(X^TX\))、対角成分以外が0となる特徴があります。
直交表:2乗を計算する
[,1] [,2] [,3] [,4]
1 -1 -1 1 1
2 1 1 1 1
3 -1 1 -1 1
4 1 -1 -1 1 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
1 1 1 -1 -1 -1 -1 1 1 1
2 -1 1 -1 1 1 -1 1 -1 1
3 -1 1 -1 -1 1 1 -1 1 1
4 1 -1 1 -1 -1 1 -1 1 1
5 -1 -1 -1 1 -1 1 1 1 1
6 -1 1 1 -1 -1 1 1 -1 1
7 -1 -1 1 -1 1 -1 1 1 1
8 1 -1 -1 1 1 -1 -1 1 1
9 1 -1 1 1 -1 -1 1 -1 1
10 1 1 1 -1 1 -1 -1 -1 1
11 -1 -1 -1 -1 -1 -1 -1 -1 1
12 -1 -1 1 1 1 1 -1 -1 1
13 1 -1 -1 -1 1 1 1 -1 1
14 1 1 -1 1 -1 1 -1 -1 1
15 -1 1 1 1 -1 -1 -1 1 1
16 1 1 1 1 1 1 1 1 1 [,1] [,2] [,3] [,4]
[1,] 4 0 0 0
[2,] 0 4 0 0
[3,] 0 0 4 0
[4,] 0 0 0 4 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] 16 0 0 0 0 0 0 0 0
[2,] 0 16 0 0 0 0 0 0 0
[3,] 0 0 16 0 0 0 0 0 0
[4,] 0 0 0 16 0 0 0 0 0
[5,] 0 0 0 0 16 0 0 0 0
[6,] 0 0 0 0 0 16 0 0 0
[7,] 0 0 0 0 0 0 16 0 0
[8,] 0 0 0 0 0 0 0 16 0
[9,] 0 0 0 0 0 0 0 0 16統計ソフトが発達していなかった時代はこの直交表を手と頭を使って作成して実験を行っていたわけですが、Rを含めた現代の統計ソフトには直交表を作成する手法が備わっています。
48.4.1 FrF2
FrF2についてもう少し詳しく見ていきます。FrF2関数には引数がたくさん設定されており、様々な方法で一部要因配置計画の計画を作成することができます。まずはnrunsとnfactorsの2つの引数について説明します。nrunsは実験数、nfactorsは説明変数の数であり、この2つを設定するのが最も基本的なFrF2関数の使い方となります。nrunsは4以上の2の指数(2n)で設定する必要があります。
FrF2関数:実験数と説明変数の数を設定する
FrF2(nruns = 8, nfactors = 4) # 説明変数が4つ、実験数が8の一部要因配置計画 A B C D
1 1 -1 -1 1
2 -1 1 1 -1
3 1 1 -1 -1
4 -1 -1 -1 -1
5 -1 1 -1 1
6 -1 -1 1 1
7 1 -1 1 -1
8 1 1 1 1
class=design, type= FrF2 48.4.1.1 FrF2関数:要因配置計画を作成する
nrunsとnfactorsの2つの引数について、\(nruns = 2^{nfactors}\)の場合には要因配置計画(full factorial design)を作成することができます。また、\(nruns > 2^{nfactors}\)の場合には要因配置計画を繰り返す実験計画を作成することになります。
FrF2:要員配置実験を作成する
FrF2(nruns = 8, nfactors = 3) # 説明変数が3つ、実験数が8の要因配置計画creating full factorial with 8 runs ... A B C
1 1 -1 1
2 -1 -1 1
3 1 1 -1
4 1 -1 -1
5 -1 -1 -1
6 1 1 1
7 -1 1 -1
8 -1 1 1
class=design, type= full factorial FrF2(nruns = 16, nfactors = 3) # 説明変数が3つ、実験数が8の要因配置計画を2セット実施creating full factorial with 8 runs ... run.no run.no.std.rp A B C Blocks
1 1 6.1 1 -1 1 .1
2 2 4.1 1 1 -1 .1
3 3 1.1 -1 -1 -1 .1
4 4 8.1 1 1 1 .1
5 5 3.1 -1 1 -1 .1
6 6 2.1 1 -1 -1 .1
7 7 5.1 -1 -1 1 .1
8 8 7.1 -1 1 1 .1
9 9 3.2 -1 1 -1 .2
10 10 5.2 -1 -1 1 .2
11 11 2.2 1 -1 -1 .2
12 12 7.2 -1 1 1 .2
13 13 4.2 1 1 -1 .2
14 14 6.2 1 -1 1 .2
15 15 8.2 1 1 1 .2
16 16 1.2 -1 -1 -1 .2
class=design, type= full factorial
NOTE: columns run.no and run.no.std.rp are annotation,
not part of the data frame48.4.1.2 FrF2関数:説明変数のレベルに名前を付ける
デフォルトでは各説明変数に設定される条件は1、-1の2つですが、default.levels引数を設定すると1、-1以外の条件を設定することもできます。default.levelsには長さ2のベクターを指定します。
FrF2:条件を1、-1以外に設定する
FrF2(8, 3, default.levels = c("A", "B"))creating full factorial with 8 runs ... A B C
1 B B B
2 B A A
3 B B A
4 A A A
5 A B B
6 A A B
7 B A B
8 A B A
class=design, type= full factorial 48.4.1.3 FrF2関数:説明変数の名前を設定する
説明変数の名前を設定するための引数がfactor.namesです。factor.namesは説明変数の数(nfactors)と同じ長さの文字列のベクターとして設定します。
FrF2関数:factor.names引数で説明変数の名前を設定する
FrF2(4, 3, factor.names = c("nutrient", "water", "light")) nutrient water light
1 -1 -1 1
2 1 -1 -1
3 -1 1 -1
4 1 1 1
class=design, type= FrF2 48.4.1.4 FrF2関数:formulaから計画を作成する
また、実験で求めたいパラメータ(主効果や交互作用の傾き)が決まっている時には、estimableにformulaを設定することでも実験デザインを作成することができます。以下の例では、5つの主効果(A、B、C、D、E)に加えて、AB、BC、ACの交互作用のパラメータを求めるための一部要因配置計画の計画を作成する例を示しています。
FrF2:求めたいパラメータのformulaから計画を作成する
FrF2(estimable = formula("~(A+B+C)^2+D+E")) A B C D E
1 -1 1 -1 1 1
2 -1 -1 1 -1 -1
3 1 1 1 -1 -1
4 -1 1 -1 -1 -1
5 -1 -1 1 1 1
6 1 1 -1 1 -1
7 -1 -1 -1 -1 1
8 1 1 -1 -1 1
9 -1 1 1 -1 1
10 -1 -1 -1 1 -1
11 -1 1 1 1 -1
12 1 -1 1 1 -1
13 1 -1 -1 1 1
14 1 -1 1 -1 1
15 1 -1 -1 -1 -1
16 1 1 1 1 1
class=design, type= FrF2.estimable 説明変数の数を指定しておき、すべての主効果を求めないデザインを採用することもできます。この時、引数にclear=FALSEを設定しておく必要があります。clearは主効果のパラメータをすべて求めるかどうかを定める引数で、clearのデフォルト値はTRUE、主効果をすべて求める設定となっています。clear=FALSEとすることで求まらない主効果を許容することができます。
主効果を求めない因子を加える
# 6つのnfactorを指定し、5つをestimableに加える
# clear=FALSEがないと演算できない
FrF2(nfactor = 6, estimable=formula("~(A+B+C)^2+D+E"), clear = FALSE) A B C D E F
1 1 -1 -1 1 1 -1
2 1 1 -1 1 -1 1
3 -1 1 -1 -1 1 1
4 -1 -1 -1 1 -1 1
5 -1 1 1 -1 -1 1
6 -1 -1 1 -1 1 -1
7 1 -1 1 1 -1 -1
8 1 1 -1 -1 -1 -1
9 -1 -1 -1 -1 -1 -1
10 -1 1 1 1 -1 -1
11 1 1 1 1 1 1
12 1 -1 1 -1 -1 1
13 -1 -1 1 1 1 1
14 1 -1 -1 -1 1 1
15 1 1 1 -1 1 -1
16 -1 1 -1 1 1 -1
class=design, type= FrF2.estimable FrF2(nfactor = 6, estimable=formula("~(A+B+C)^2+D+E")) # エラーError in `mapcalc()`:
! The required interactions cannot be accomodated clear of aliasing in 16 runs with resolution IV or higher.48.4.1.5 FrF2関数:generatorsを利用する
また、generators引数を設定すると、評価したい交互作用を追加し評価するための計画を作成することができます。
A B C D E
1 1 -1 1 -1 -1
2 -1 1 -1 -1 1
3 1 1 -1 1 -1
4 1 -1 -1 -1 1
5 1 -1 1 1 -1
6 -1 1 1 -1 -1
7 1 1 -1 -1 -1
8 -1 1 1 1 -1
9 -1 1 -1 1 1
10 -1 -1 -1 -1 -1
11 -1 -1 1 -1 1
12 -1 -1 -1 1 -1
13 1 1 1 1 1
14 1 1 1 -1 1
15 -1 -1 1 1 1
16 1 -1 -1 1 1
class=design, type= FrF2.generators FrF2(16, 5, generators = "ABD") # ABDの交互作用を評価できるようにする A B C D E
1 -1 -1 -1 1 1
2 -1 -1 1 -1 -1
3 -1 1 1 1 -1
4 -1 1 -1 -1 1
5 1 1 -1 1 1
6 1 -1 1 1 -1
7 1 1 1 -1 -1
8 -1 1 1 -1 1
9 1 -1 -1 1 -1
10 -1 -1 1 1 1
11 1 1 1 1 1
12 1 -1 -1 -1 1
13 -1 1 -1 1 -1
14 -1 -1 -1 -1 -1
15 1 1 -1 -1 -1
16 1 -1 1 -1 1
class=design, type= FrF2.generators 48.4.1.6 FrF2関数:実験計画に中間点を追加する
実験計画に中間の点(2条件が1、-1の時、0)を加えると、その説明変数に対する目的変数の応答が直線的か、曲線になっているかを評価できます。
FrF2関数では、ncenter引数を用いることで、中間点を加えることができます。ncenterには数値を設定し、設定した数だけ中間点のみの実験を追加します。
FrF2:中間点を追加する
FrF2(8, 5, ncenter = 3) A B C D E
1 0 0 0 0 0
2 1 -1 -1 -1 -1
3 1 -1 1 -1 1
4 1 1 1 1 1
5 -1 -1 1 1 -1
6 0 0 0 0 0
7 -1 -1 -1 1 1
8 1 1 -1 1 -1
9 -1 1 -1 -1 1
10 -1 1 1 -1 -1
11 0 0 0 0 0
class=design, type= FrF2.center また、すでに作成したFrF2関数の返り値を引数に取る、add.center関数でも中間点を設定することができます。
FrF2:作成した計画に中間点を追加する
# 計画を作成した後でも中間点を設定できる
design_exp <- FrF2(8,5)
add.center(design_exp, 3) # 計画に中間点の実験を3つ追加する A B C D E
1 0 0 0 0 0
2 -1 -1 1 1 -1
3 1 1 1 1 1
4 1 -1 -1 -1 -1
5 1 -1 1 -1 1
6 0 0 0 0 0
7 -1 -1 -1 1 1
8 1 1 -1 1 -1
9 -1 1 1 -1 -1
10 -1 1 -1 -1 1
11 0 0 0 0 0
class=design, type= FrF2.center 48.4.1.7 FrF2関数:一部要因配置計画のresolution
一部要因配置計画には、resolution(分解能)というものがあり、resolutionにはクラスが3つ(class III、class IV、 class V)あります。resolutionが高くなると、以下の通り求まる交互作用のパラメータが多くなり、実験数が増えることになります。
- class III:すべての主効果のパラメータが求まる
- class IV:すべての主効果と2次の交互作用の一部のパラメータが求まる
- class V:すべての2次の交互作用のパラメータが求まる
FrF2関数では、resolution引数にresolutionのクラスを数値で指定することで、resolutionを指定した実験計画を得ることができます。resulutionは3、4、5のいずれかの数値を取ります。resolutionを指定する場合には実験数(nruns)は指定せず、説明変数の数(nfactors)とresolutionのみを指定します。
FrF2:resolutionを指定する
FrF2(nfactors = 7, resolution = 5) |> nrow() # resolution Vだと64実験[1] 64FrF2(nfactors = 7, resolution = 4) |> nrow() # resolution IVだと16実験[1] 16FrF2(nfactors = 7, resolution = 3) # resolution III(主効果のみ)だと8実験 A B C D E F G
1 1 1 -1 1 -1 -1 -1
2 1 1 1 1 1 1 1
3 -1 1 1 -1 -1 1 -1
4 1 -1 1 -1 1 -1 -1
5 -1 1 -1 -1 1 -1 1
6 -1 -1 1 1 -1 -1 1
7 1 -1 -1 -1 -1 1 1
8 -1 -1 -1 1 1 1 -1
class=design, type= FrF2 48.4.1.8 FrF2関数:実験計画の評価
FrF2関数で実験計画を作成した後、実験計画の情報を取得する場合にはdesign.info関数を用います。design.info関数はFrF2関数の返り値を引数に取ります。
design.info関数で計画情報を得る
x <- FrF2(8, 5)
x |> design.info() |> head(3) # デザインの詳細を表示(出力が多いので3つだけ表示)$type
[1] "FrF2"
$nruns
[1] 8
$nfactors
[1] 548.4.1.9 FrF2関数:行列への変換
FrF2関数の返り値はデータフレームですが、各列は因子(factor)になっています。そのまま行列に変換すると、文字列の行列が返ってきます。
FrF2:返り値をas.matrix関数で行列に変換
FrF2(8, 3) |> as.matrix()creating full factorial with 8 runs ... A B C
1 "1" "1" "1"
2 "1" "1" "-1"
3 "-1" "1" "1"
4 "1" "-1" "-1"
5 "-1" "-1" "-1"
6 "1" "-1" "1"
7 "-1" "1" "-1"
8 "-1" "-1" "1" 数値の行列に変換する場合には、desnum関数を用います。
FrF2:desnum関数で数値の行列に変換
x <- FrF2(8, 7)
desnum(x) # matrixにする関数 A B C D E F G
1 1 1 1 1 1 1 1
2 1 -1 -1 -1 -1 1 1
3 -1 -1 1 1 -1 -1 1
4 1 -1 1 -1 1 -1 -1
5 -1 1 -1 -1 1 -1 1
6 -1 1 1 -1 -1 1 -1
7 -1 -1 -1 1 1 1 -1
8 1 1 -1 1 -1 -1 -1desnum(x) |> class()[1] "matrix" "array" この行列はデザイン行列から切片項を除いたものになっています。一部要因配置計画のデザイン行列は直交(orthogonal)ですので、切片項の列を追加して\(X^TX\)の行列を演算すると、単位行列の整数倍になります。
48.4.2 回帰と結果の評価
FrF2には、実験計画を作成するだけではなく、実験計画に沿って実験を行った後、回帰の結果を評価するための関数も備わっています。まずはlm関数で回帰を行い、返り値をオブジェクトに代入しておきます。
FrF2:実験計画を用いて回帰
y <- rnorm(8, 7, 0.5)
x <- FrF2(8, 7)
# 回帰のための行列を作成
xy <- cbind(desnum(x), y)
lm_xy <- lm(y ~ (.)^2, data = xy |> as.data.frame())
lm_xy
Call:
lm.default(formula = y ~ (.)^2, data = as.data.frame(xy))
Coefficients:
(Intercept) A B C D E
7.35961 -0.13706 0.08395 -0.10889 -0.25972 0.06713
F G A:B A:C A:D A:E
-0.01441 -0.08703 NA NA NA NA
A:F A:G B:C B:D B:E B:F
NA NA NA NA NA NA
B:G C:D C:E C:F C:G D:E
NA NA NA NA NA NA
D:F D:G E:F E:G F:G
NA NA NA NA NA この回帰の結果(lm_xy)をFrF2の関数の引数に取ることで、回帰の結果を評価することができます。
48.4.2.1 aliase
aliase(エイリアス、別名関係)とは、説明変数や交互作用のうち、計画の列が同じ値となるため分離ができないもの同士のことを指します。上のlm_xyにおけるaliaseを調べる場合、aliases関数を用います。aliases関数の引数にlm関数の返り値(下の例ではlm_xy)を取ると、aliaseの一覧を表示することができます。
以下の例では、aliases(lm_xy)の結果として「A = B:D = C:E = F:G」という表示が返ってきています。これは、説明変数Aと交互作用B:D、C:E、F:Gが分離不能なので、Aの主効果を求めると交互作用B:D、C:E、F:Gは求まらないこと、Aの主効果に交互作用B:D、C:E、F:Gのパラメータが含まれている可能性があることを示しています。
aliase
aliases(lm_xy)
A = B:D = C:E = F:G
B = A:D = C:F = E:G
C = A:E = B:F = D:G
D = A:B = C:G = E:F
E = A:C = B:G = D:F
F = A:G = B:C = D:E
G = A:F = B:E = C:Daliaseはlm関数の返り値を用いなくても、FrF2関数の返り値から評価することもできます。上記の通り、design.info関数を用いると実験計画の詳細を調べることができます。このdesign.info関数の返り値のうち、aliasedという項目にはaliaseの情報が記載されており、上で示したaliases関数の返り値と同じものが記載されています。
aliaseをFrF2関数の返り値から評価する
design.info(x)$aliased$legend
[1] "A=A" "B=B" "C=C" "D=D" "E=E" "F=F" "G=G"
$main
[1] "A=BD=CE=FG" "B=AD=CF=EG" "C=AE=BF=DG" "D=AB=CG=EF" "E=AC=BG=DF"
[6] "F=AG=BC=DE" "G=AF=BE=CD"
$fi2
character(0)48.4.2.2 主効果・交互作用を評価する
FrF2には、主効果と交互作用を評価するためのグラフを作成する関数である、MEPlot関数とIAPlot関数が準備されています。
MEPlotは、各説明変数の2水準について値を示したグラフで、傾きの大きさがその説明変数の効果の大きさを反映します。また、IAPlotは2説明変数同士の結果を表示したもので、交互作用があれば赤と黒の線の傾きが異なります。MEPlot、IAPlot共にスクリーニングや交互作用の評価の必要性を調べるのに有用です。
MEPlot・IAPlot関数
# 各説明変数の効果に関するプロット
MEPlot(lm_xy)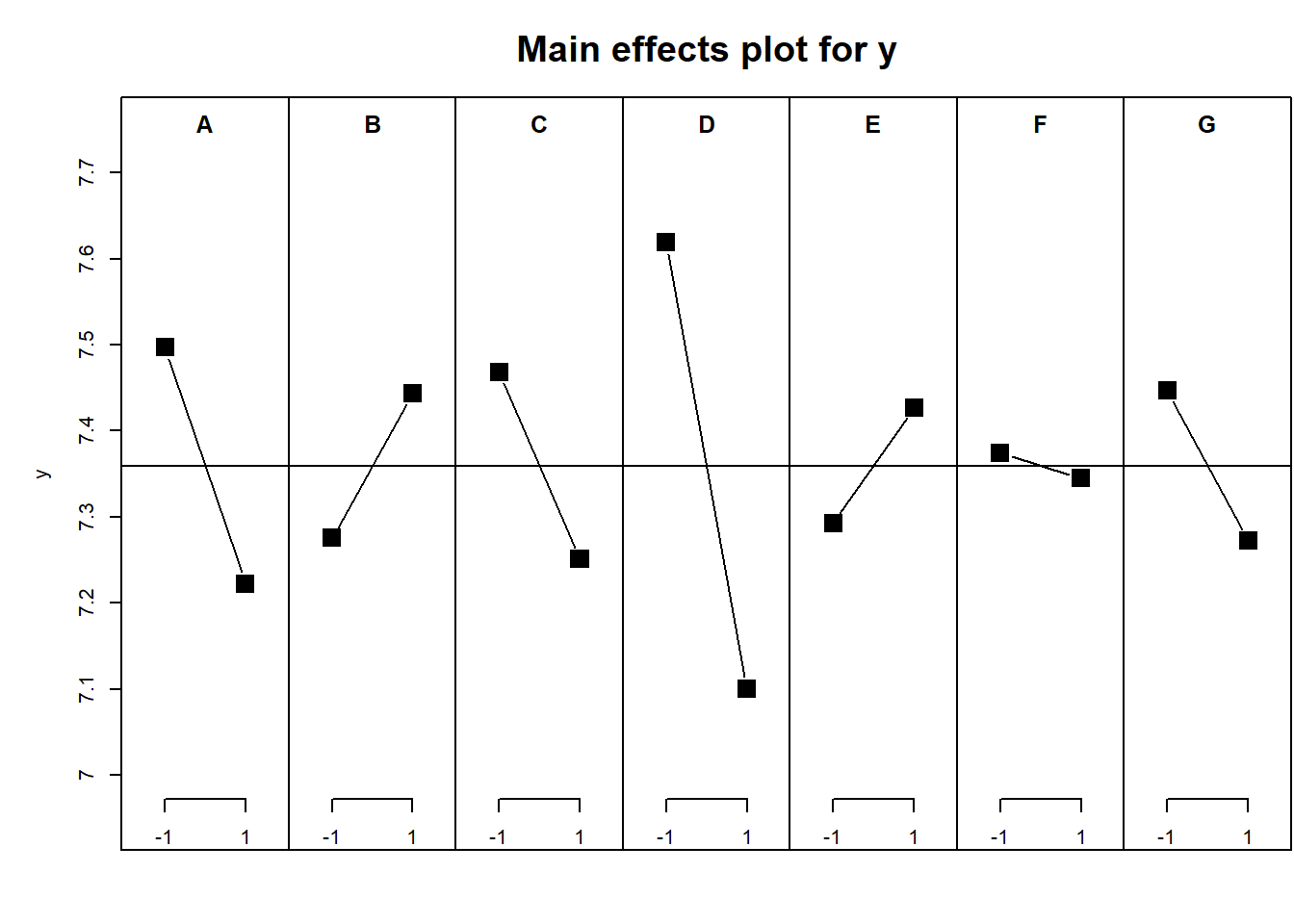
# 交互作用を示すためのプロット
IAPlot(lm_xy)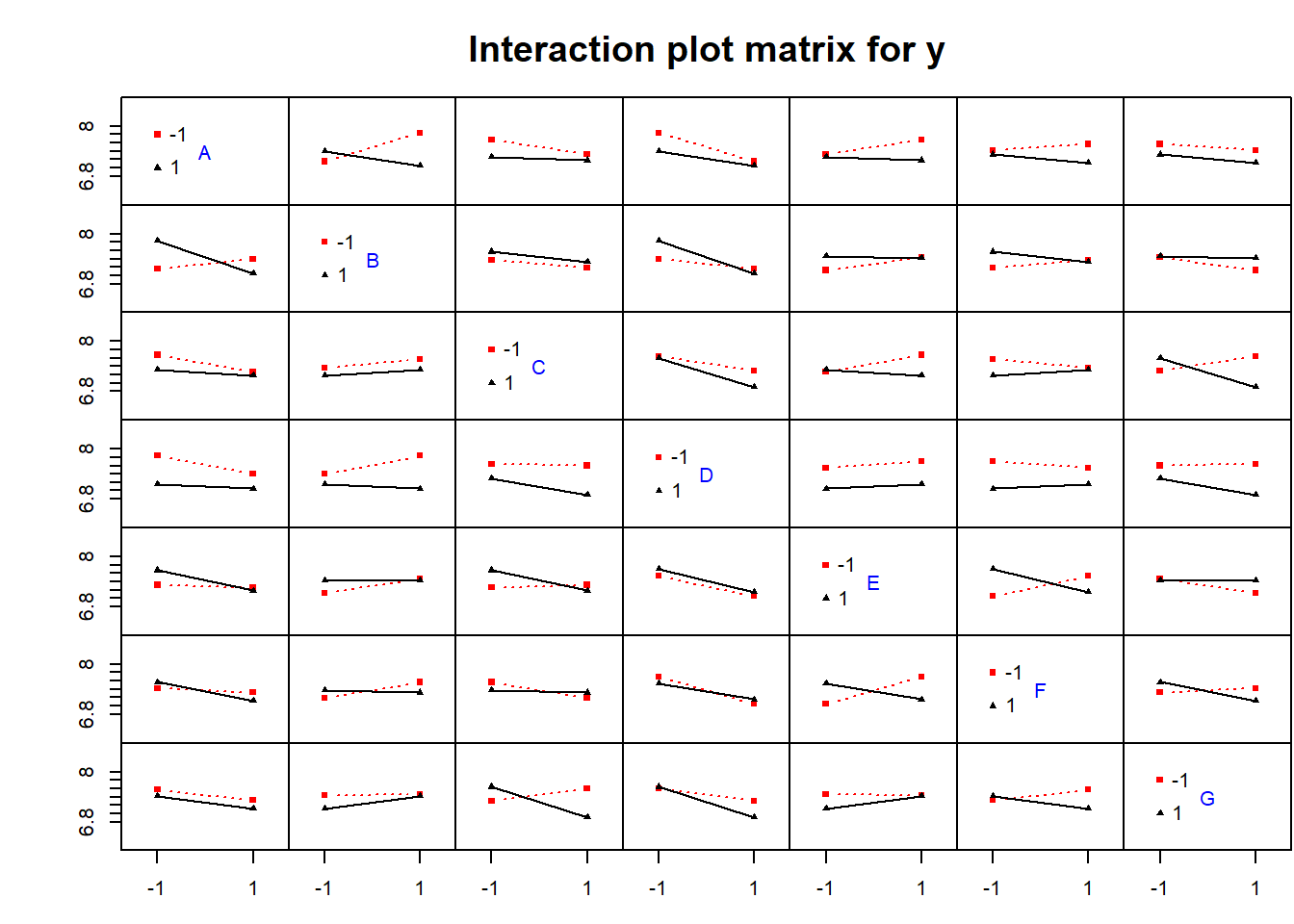
DanielPlot関数は、論文(Daniel 1959)で説明されている、正規分布とパラメータを大きさ順にならべてプロットしたqqplotの一種です。説明変数に何の効果も無ければ、直線上に点が並びます。正規分布の代わりに半正規分布を用いたプロットにすることもでき(half = TRUE)、こちらの方が直線に点が乗っているかわかりやすくなります。説明変数に効果がある場合には、直線より右側に点が外れることになります。
回帰のコードに示した通り、目的変数yはただの正規乱数ですので、どの説明変数にも明確な効果がなく、すべての点が直線上に乗ります。
Daniel Plot
# 直線に乗らない説明変数には有意な効果があると考える
DanielPlot(lm_xy)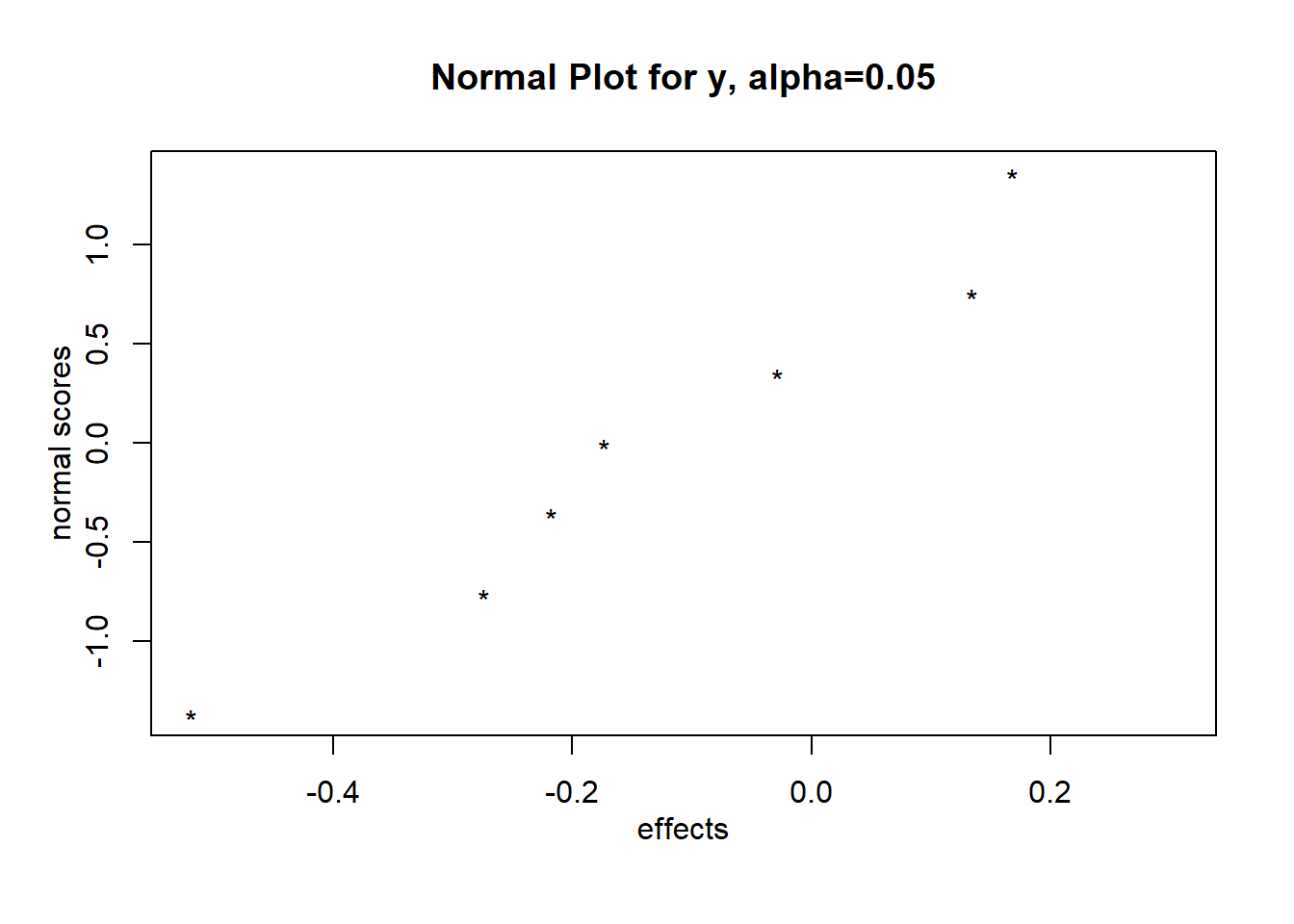
DanielPlot(lm_xy, half = TRUE) # 半正規分布を用いる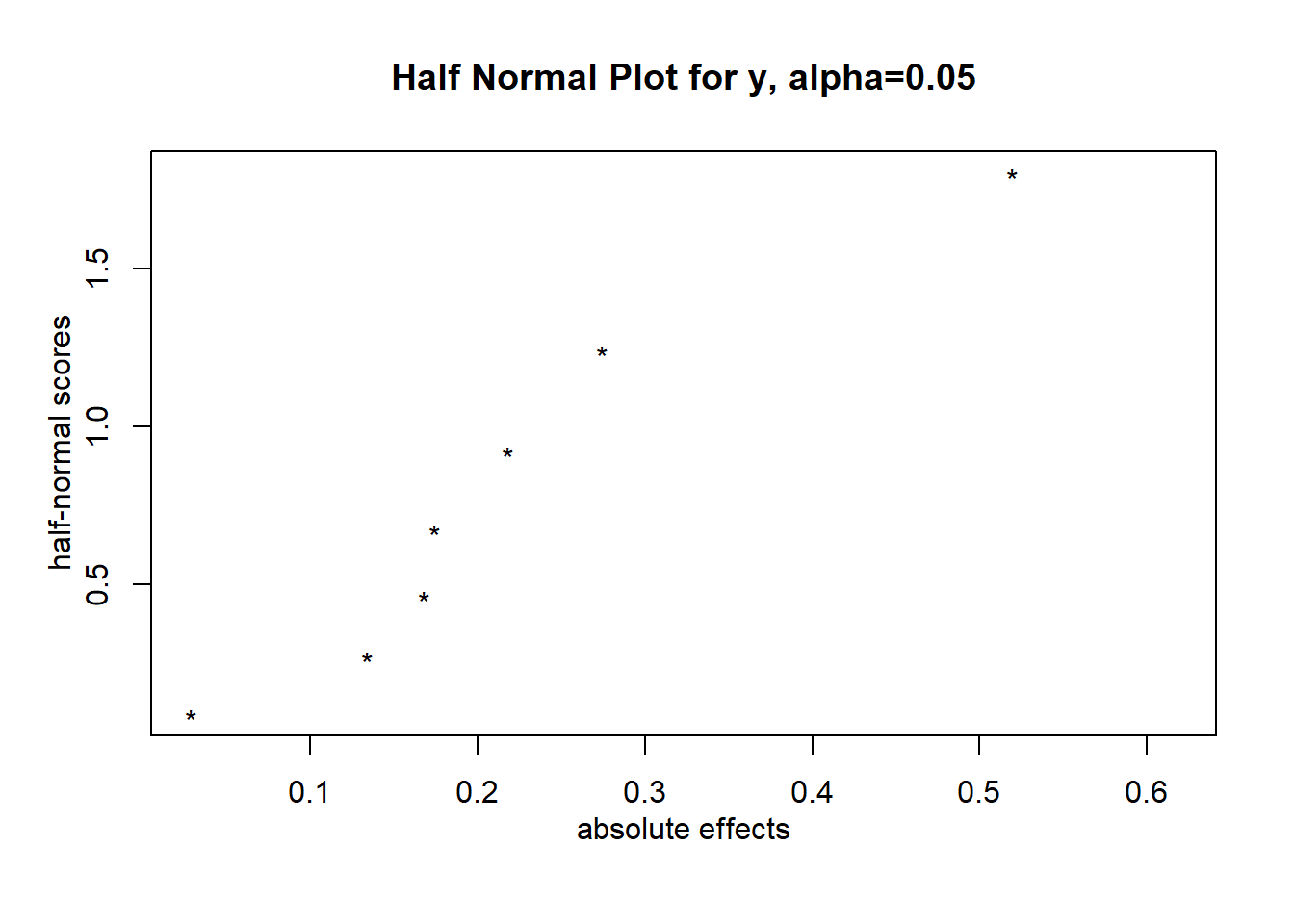
説明変数から3つを選び、それぞれの効果を図に示すのがcubePlotです。選択した各説明変数間の関係と並行性を数値から評価することができます。
cubePlot
# 3つの説明変数
cubePlot(lm_xy, "A", "B", "C")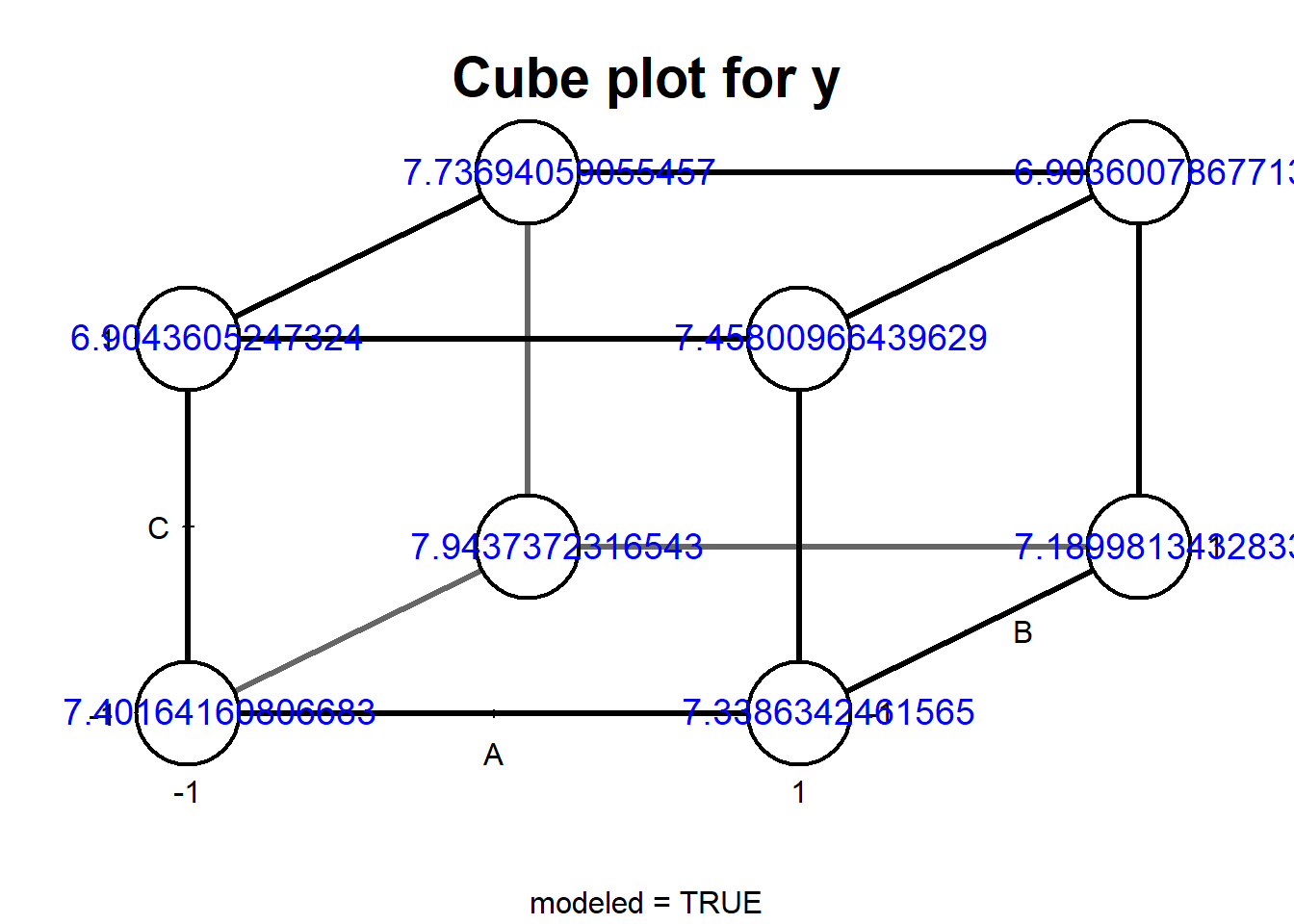
48.5 Optimal Design
説明変数がn個のとき、要因配置計画では2n、一部要因配置計画では2n-k(k<n)の実験を行うことになります。とはいえ、必ず2の倍数に従って実験を行うかというと、そういうわけではないでしょう。時間や予算によっては2nの実験を実施することは難しくても、2n-1よりは多く実験ができそう、という場合もあります。実験を増やせば結果の精度が上がっていきますから、わざわざ一部要因配置計画に合わせて少なく実験をするのでは結果の精度を下げることになります。また、FrF2では各説明変数に2条件を仮定していましたが、3条件以上で実験を行い、説明変数への応答が直線的なのか、曲線的なのか評価したい場合もあるでしょう。
交互作用についても、ある交互作用は注意が必要で、別の交互作用についてはそれほど注意しなくて良い場合もあります。例えば、作物の収量と肥料・水・日射量の関係を見ると、水をたくさん与えれば肥料は流れ出て効果が小さくなる、つまり交互作用がありそうですが、水と日射量には明確な交互作用はなさそうです。ですので、実験では肥料と水の交互作用に注意が必要そう、と想像することができます。
しかし、一部要因配置計画よりはたくさん実験をできそうであっても、どのような実験の組み合わせであれば求めたい交互作用が求まり、より実験の精度を高くできるかをパッと想像できる人はあまりいないでしょう。
このように、要因配置計画や一部要因配置計画よりも柔軟性が高く、求めたい交互作用を適切に評価し、結果のばらつきをできるだけ小さく最適化することを目的とした実験計画法がOptimal Designです。日本語では最適計画と呼ばれるようです。
Optimal Designには、以下の通り非常にたくさんの種類があります。
- A-Optimal Design
- C-Optimal Design
- D-Optimal Design
- E-Optimal Design
- S-Optimal Design
- T-Optimal Design
- G-Optimal Design
- I-Optimal Design
- V-Optimal Design
また、Optimal Designには以下のような想定での実験デザインを考慮したものもあります。
- ブロック(局所管理)を想定したもの
- ブロックを想定しているけどブロックの条件を変更しにくい場合(例えば、溶鉱炉の温度を変更したいけど変更するとコストがかさむ場合)を想定したもの
- 各説明変数の和は決まっていて、説明変数の割合を変える場合(例えばホットケーキミックス500g中の小麦粉やベーキングパウダーなどの原材料の量を変える場合)を想定したもの
- 実験を追加で行うことを想定したもの
すべてを説明するとページがいくらあっても足りないため、このテキストではD-Optimal DesignとI-Optimal Designのみを簡単に説明します。Optimal Designについて詳しく知りたい方は文献(Goos and Jones 2011)を参照下さい。また、Optimal Designを含めた実験計画についてはJMPの機能が充実しています。以下に説明する通りRでもOptimal Designを計画することはできますが、JMPではGUIを用いて実験計画を組むことができます。JMPはSAS Institute.incの製品ですので、利用にはお金はかかりますが、お金に余裕があれば試してみるのもよいでしょう。
48.5.1 D-optimal Design
D-optimal Designは、一般線形モデルの演算(Tip 48.1)で説明したデザイン行列の積(\(X^TX\))の行列式(\(|X^TX|\))を最大とするデザインを選択するOpitimal Designの方法の一つです。
各説明変数のパラメータ(傾き)のばらつき(分散・共分散行列、\(Cov(\hat{\beta})\))はデザイン行列を用いて以下の式で表されます。
\[Cov(\hat{\beta}) = \hat{\sigma}^2(X^TX)^{-1}\]
このばらつきのうち、実験デザインで小さくできるのは\((X^TX)^{-1}\)、\(X^TX\)の逆行列の部分になります。逆行列は行列式の逆数を行列にかけた形で表されるため(\(A^{-1}=\frac{1}{|A|}\cdot \tilde{A}\))、\(X^TX\)の行列式(\(|X^TX|\))が大きくなれば\((X^TX)^{-1}\)を小さく、つまりばらつきを小さくすることができます。ですので、\(|X^TX|\)を最大化するデザイン行列\(X\)を選択するのがD-Optimal Designです。Dはdeterminant(行列式)のDです。
ばらつきが小さくなれば高い確度を持ってパラメータを推定できるので、D-Optimal Designは汎用的に使えるOptimal Designの一つとなります。
48.5.2 I-Optimal Design
I-Optimal DesignはD-Optimal Designと同様にばらつきを小さくするデザイン行列を見つける方法ですが、最適化するのは\(|X^TX|\)ではなく、平均のばらつき(mean prediction variance)と呼ばれるものです。このmean prediction varianceはFraction of Design Space Plotと呼ばれるプロットの中央値を指します。以下にFraction of Design Space Plotを示します。
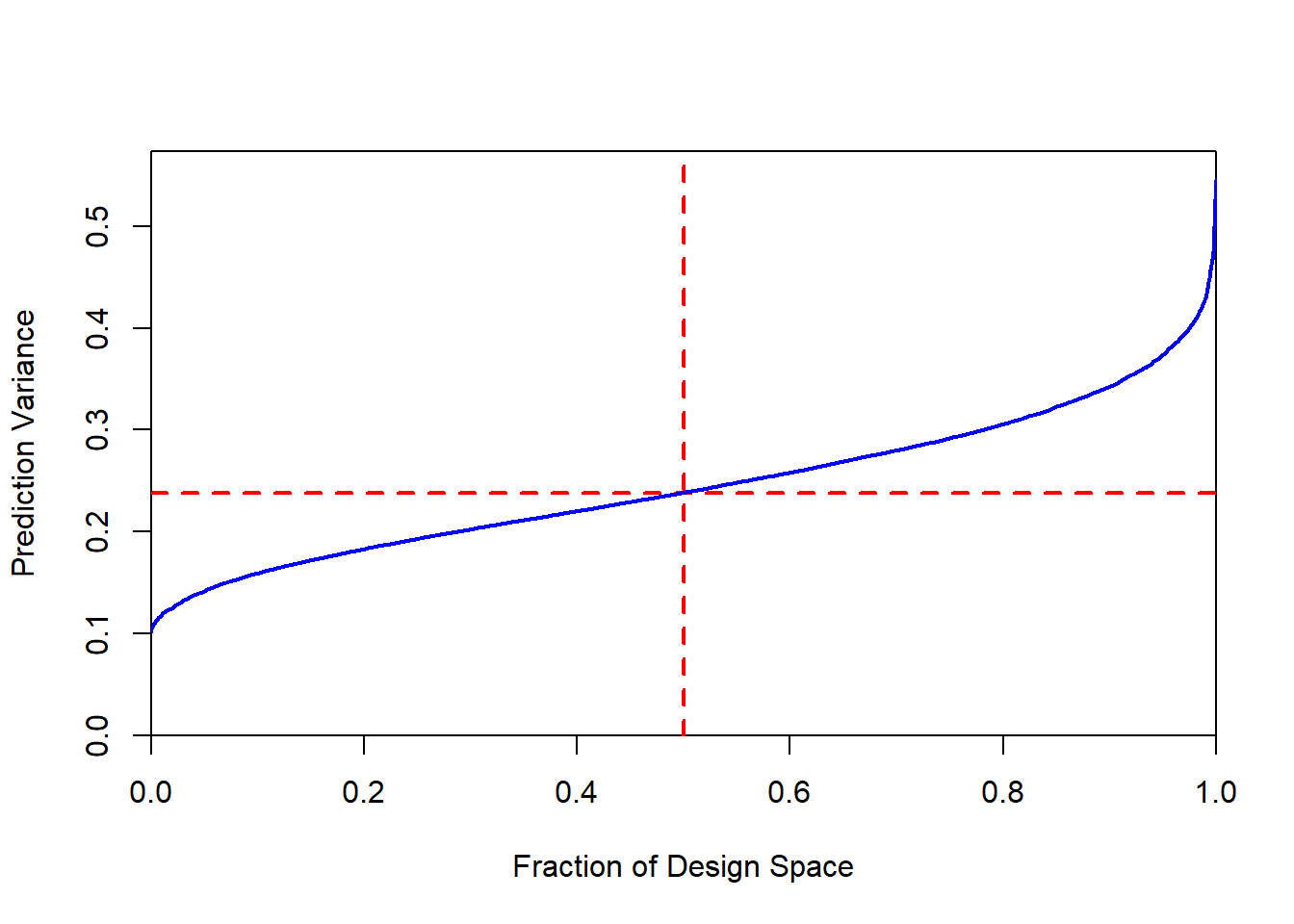
このグラフのFraction of Design Spaceが0.5の時のPrediction Variance(赤線が交わる点)を最小とするモデルを選択するのがI-Optimal Designです。I-Optimal Designは説明変数と目的変数の関係が多項式的(直線ではなく、曲線的)である場合に比較的適しているようです。
D-Optimal Design、I-Optimal Design共に最適なデザイン行列は乱数を使った繰り返し計算(Monte Carloアルゴリズム)で計算・作成されます。一部要因配置計画についてはコンピュータが発達する前から直交表を用いて作成されてきましたが、Opitimal Designではデザイン行列の作成に繰り返し計算を用いるため、デザインの作成にはコンピュータが必要です。
48.6 RでOptimal Design:skpr
RでOptimal Designを作成する場合には、様々なパッケージを利用可能ですが、比較的簡単にOptimal Designを作成・評価できるパッケージとして、以下ではskprパッケージ(Morgan-Wall and Khoury 2021)を紹介します。
48.6.1 実験計画を作成する
skprパッケージで実験計画を作成する場合、まずはexpand.grid関数を用いて要因配置計画を作成します。FrF2のように各説明変数の条件を2条件とする必要はなく、3条件以上であってもOptimal Designを作成することができます。
このexpand.grid関数で作成したデータフレームをgen_design関数の引数にすることで、実験計画を作成することができます。gen_design関数にはデータフレームの他に、回帰のモデル(model)と実験数(trial)を設定します。
skpr:gen_design関数
# 主効果だけ評価する場合、中間点は必要ないのでnutrient=0は採用されない
gen_design(cand, model = ~ nutrient + water + light + depth, trial = 10) nutrient water light depth
1 1 -1 -1 1
2 -1 -1 1 1
3 -1 -1 -1 -1
4 1 1 -1 -1
5 -1 1 1 -1
6 -1 1 -1 1
7 1 1 -1 -1
8 1 1 1 1
9 1 -1 1 -1
10 1 1 1 1gen_design関数のデフォルトのOptimalityはD-Optimalityですので、返り値はD-Optimal Designのデータフレームになります。また、モデルは以下のような形で設定することもできます。
skpr:modelの設定
# 上と同じ(すべての主効果を含める)
gen_design(cand, model = ~ ., trial = 10) nutrient water light depth
1 1 1 1 1
2 1 1 -1 -1
3 -1 1 1 1
4 -1 -1 -1 -1
5 -1 1 -1 1
6 -1 1 -1 -1
7 1 -1 -1 1
8 1 -1 1 -1
9 -1 -1 1 1
10 -1 1 1 -1# 全部の説明変数に対して2次の交互作用を設定
gen_design(cand, model = ~ (.)^2, trial = 12) nutrient water light depth
1 -1 -1 1 1
2 -1 1 -1 1
3 1 1 -1 -1
4 1 1 1 -1
5 -1 -1 -1 -1
6 -1 1 1 -1
7 1 1 -1 1
8 1 -1 1 1
9 1 1 1 1
10 -1 1 1 1
11 1 -1 -1 1
12 1 -1 1 -1# nutrientの2乗(多項式回帰)を設定:説明変数を3条件以上にする必要あり
gen_design(cand, model = ~ . + I(nutrient^2), trial = 12) nutrient water light depth
1 -1 1 -1 1
2 0 1 -1 -1
3 1 1 -1 -1
4 -1 -1 1 1
5 1 -1 1 -1
6 -1 1 1 -1
7 0 -1 1 -1
8 0 -1 -1 1
9 0 1 1 1
10 -1 -1 -1 -1
11 1 1 1 1
12 1 -1 -1 148.6.1.1 Optimalityの設定
Optimalityはoptimality引数で設定することができます。optimalityは文字列で設定し、"D", "I", "A", "ALIAS", "G", "T", "E", "CUSTOM"のいずれかを選択します。これらのうち、"ALIAS"は近年の論文(Jones and Nachtsheim 2011)に記載された最適化の手法で、"CUSTOM"は自分で設定した最適化アルゴリズムを利用する方法です。以下では、I-Optimal Designの計画を作成しています。
skpr:optimalityを選択する
# I-Optimal Designの計画を作成する
gen_design(candidateset = cand, model = ~ nutrient + water + light + depth, trial = 10, optimality = "I") nutrient water light depth
1 1 1 -1 -1
2 1 1 1 1
3 1 -1 1 -1
4 -1 -1 1 1
5 1 -1 -1 1
6 -1 1 1 -1
7 -1 -1 -1 -1
8 1 1 -1 -1
9 -1 1 -1 1
10 -1 -1 1 148.6.1.2 ブロックの設定
gen_design関数の引数にblocksizesを設定すると、ブロックを設定した実験を計画することができます。以下の例では、blocksizesを4、つまり4実験ずつのブロックを3つ作成し、12実験の計画としています。add_blocking_column=TRUEを設定すると、ブロックの列を追加することができます。
blockを設定する
gen_design(cand, ~., 12, blocksizes = 4, add_blocking_column = TRUE) Block1 nutrient water light depth
1 1 -1 -1 -1 1
2 1 1 1 -1 1
3 1 1 1 1 -1
4 1 -1 -1 1 -1
5 2 1 -1 1 1
6 2 -1 1 -1 1
7 2 1 1 -1 -1
8 2 -1 -1 1 -1
9 3 1 -1 1 1
10 3 -1 1 -1 -1
11 3 -1 1 1 1
12 3 1 -1 -1 -148.6.1.3 Split-plot design
実験を計画する場合、説明変数はいつも自由に変更できる、というわけではありません。例えば、高温で溶かした素材を用いて製品を作成する場合、温度の影響を調べるために窯の温度をランダムに上げたり下げたりすると燃料のコストも時間もかかってしまいます。したがって、説明変数の一部はあまり頻繁に変更せず、実験を行った方がよい場合もあります。
このような場合に用いるのがsplit-plot designです。skprはsplit-plot designにも対応しています。split-plot designでは、選択した変更しにくい説明変数をなるべく同じ値で繰り返すように実験を設計してくれます。
以下にsplit-plot designの作成方法を示します。split-plot designを作成する場合、まずは変更しにくい説明変数のみをmodelに設定した計画をgen_design関数で作成します。この計画のオブジェクトを再びgen_design関数のsplitplotdesign引数に設定します。実験はsplitplotdesignに指定した計画のtrialsの整数倍とします。Split-plot designの結果として、以下のように変えにくい変数(下の例ではnutrient)の値に比較的変更が少ない実験を計画することができます。
split-plot designの作成
# 変更しにくい説明変数のみをモデルに含めた計画を作成する
spdesign =
gen_design(
cand,
model = ~nutrient,
trials = 12,
repeats = 10)
# 上で示した計画をsplitplotdesign引数に設定する
gen_design(cand, ~., splitplotdesign = spdesign, trials = 24) nutrient water light depth
1.1 1 -1 -1 1
1.2 1 1 1 -1
2.3 1 1 -1 -1
2.4 1 -1 1 1
3.5 -1 1 -1 -1
3.6 -1 -1 1 1
4.7 1 -1 -1 -1
4.8 1 1 1 1
5.9 1 -1 1 -1
5.10 1 1 -1 1
6.11 -1 1 1 -1
6.12 -1 -1 -1 1
7.13 -1 -1 -1 -1
7.14 -1 1 1 1
8.15 1 -1 1 1
8.16 1 1 -1 -1
9.17 -1 1 1 -1
9.18 -1 -1 -1 1
10.19 1 -1 1 -1
10.20 1 1 -1 1
11.21 -1 -1 1 -1
11.22 -1 1 -1 1
12.23 -1 -1 -1 -1
12.24 -1 1 1 148.6.1.4 Shinyアプリで実験計画を作成する
skprにはShinyアプリを起動するための関数(skprGUI)があり、この関数を用いるとブラウザ上でインタラクティブに実験計画を作成することもできます。
Shinyアプリケーションを起動し実験計画を作成する
skprGUI()48.6.2 gen_designの返り値と計画の評価
gen_design関数の返り値はデータフレームです。ただし、このデータフレームにはattributeが設定されています。skprパッケージにはデザインを評価する関数がいくつか設定されていますが、これらの関数にはこのattributeが必要となります。
skpr:デザインの返り値
od_d <- gen_design(cand, model = ~ ., trial = 10)
od_i <- gen_design(cand, model = ~ ., trial = 10, optimality = "I")
od_d |> class() # クラスはデータフレーム[1] "data.frame"od_d |> attributes() |> names() # attributeが設定されている [1] "names" "row.names" "class"
[4] "blocking" "D" "A"
[7] "model_matrix" "generating_model" "generating.criterion"
[10] "generating.contrast" "variance.matrix" "candidate_set"
[13] "moments.matrix" "varianceratios" "correlation.matrix"
[16] "alias.matrix" "trA" "G"
[19] "T" "E" "I"
[22] "optimalsearchvalues" "bestiterations" "splitplot"
[25] "augmented" "model_matrix_cor" attributeはget_attribute関数でも取得することができます。
get_attribute関数でattributeを取得する
get_attribute(od_d) |> names()[1] "model_matrix" "moments.matrix" "variance.matrix"
[4] "alias.matrix" "correlation.matrix" "model" 48.6.2.1 最適化パラメータを評価する
Optimal Designでは、何らかの最適化パラメータを最大化・最小化するデザインを選択しています。この最適化パラメータを評価するための関数がget_optimalityです。get_optimality関数の引数にgen_design関数の返り値を取ると、最適化パラメータが表示されます。最適化パラメータはD、I、A、G、T、E、Aliasの7つです。D-Optimal DesignではDを最大化、I-Optimal DesignではIを最小化しています。
get_optimality関数
get_optimality(od_d) # D-OptimalではD(D efficiencyというパラメータ)が大きい D I A G T E Alias
1 97.03219 NA 94.38202 Not Computed 50 8 4.344671get_optimality(od_i) # I-optimalではI(average prediction variance)が小さい D I A G T E Alias
1 96.08995 0.2458333 93.02326 Not Computed 50 8 4.2448.6.2.2 Power(検出力)を計算する
実験計画において、29章で説明したPower(検出力)の評価は重要です。検出力が80%(場合によっては90%)以上となるよう実験数(例数)を設計するのがよいとされています。実験計画においても同様に検出力を80%以上とするため、skprには検出力を計算するための関数(eval_design)も備わっています。eval_design関数はそれぞれのパラメータについてPowerを計算します。
Powerの計算
eval_design(od_d) parameter type power
1 (Intercept) effect.power 0.6874107
2 nutrient effect.power 0.6874107
3 water effect.power 0.6874107
4 light effect.power 0.6991716
5 depth effect.power 0.6991716
6 (Intercept) parameter.power 0.6874107
7 nutrient parameter.power 0.6874107
8 water parameter.power 0.6874107
9 light parameter.power 0.6991716
10 depth parameter.power 0.6991716
============Evaluation Info=============
* Alpha = 0.05 * Trials = 10 * Blocked = FALSE
* Evaluating Model = ~nutrient + water + light + depth
* Anticipated Coefficients = c(1, 1, 1, 1, 1)
* Contrasts = `contr.sum`
* Parameter Analysis Method = `lm(...)`
* Effect Analysis Method = `car::Anova(fit, type = "III")` eval_design(od_i) parameter type power
1 (Intercept) effect.power 0.7161172
2 nutrient effect.power 0.6787784
3 water effect.power 0.6787784
4 light effect.power 0.6787784
5 depth effect.power 0.6787784
6 (Intercept) parameter.power 0.7161172
7 nutrient parameter.power 0.6787784
8 water parameter.power 0.6787784
9 light parameter.power 0.6787784
10 depth parameter.power 0.6787784
============Evaluation Info=============
* Alpha = 0.05 * Trials = 10 * Blocked = FALSE
* Evaluating Model = ~nutrient + water + light + depth
* Anticipated Coefficients = c(1, 1, 1, 1, 1)
* Contrasts = `contr.sum`
* Parameter Analysis Method = `lm(...)`
* Effect Analysis Method = `car::Anova(fit, type = "III")` また、より精度の高いPowerを求める場合には、乱数計算(モンテカルロ法)を用いた関数(eval_design_mc)を用いることもできます。
繰り返し計算でより正確なPowerを求める
eval_design_mc(od_d) parameter type power
1 (Intercept) effect.power.mc 0.679
2 nutrient effect.power.mc 0.664
3 water effect.power.mc 0.675
4 light effect.power.mc 0.707
5 depth effect.power.mc 0.698
6 (Intercept) parameter.power.mc 0.679
7 nutrient parameter.power.mc 0.664
8 water parameter.power.mc 0.675
9 light parameter.power.mc 0.707
10 depth parameter.power.mc 0.698
============Evaluation Info============
* Alpha = 0.05 * Trials = 10 * Blocked = FALSE
* Evaluating Model = ~nutrient + water + light + depth
* Anticipated Coefficients = c(1, 1, 1, 1, 1)
* Contrasts = `contr.sum`
* Parameter Analysis Method = `lm(...)`
* Effect Analysis Method = `car::Anova(fit, type = "III")` また、実験数(例数)とPowerの関係を調べるグラフを作成する場合には、calculate_power_curves関数を用います。calculate_power_curves関数の返り値はPowerを計算したデータフレームとグラフで、グラフの結果はgen_design関数のtrialの設定の参考に用いることができます。
Power curveを表示する
# trialが10~60まで10置きの場合のPowerを計算する
calculate_power_curves(
trials = seq(10, 60, by = 10),
candidateset = cand,
model = ~ nutrient + water + light + depth)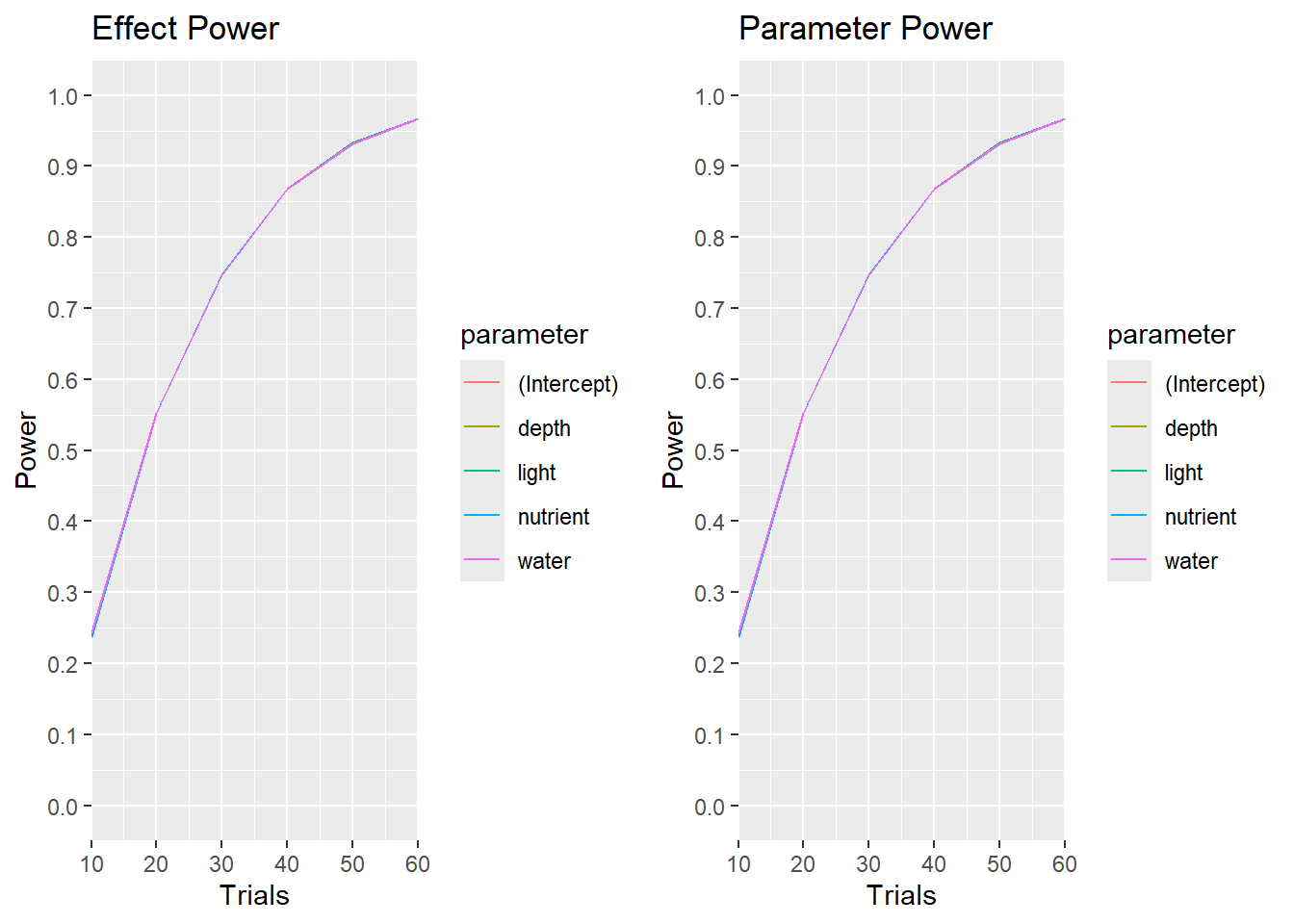
parameter type power trials effectsize random_seed
1 (Intercept) effect.power 0.2383684 10 1 123
2 nutrient effect.power 0.2383684 10 1 123
3 water effect.power 0.2437324 10 1 123
4 light effect.power 0.2383684 10 1 123
5 depth effect.power 0.2437324 10 1 123
6 (Intercept) parameter.power 0.2383684 10 1 123
7 nutrient parameter.power 0.2383684 10 1 123
8 water parameter.power 0.2437324 10 1 123
9 light parameter.power 0.2383684 10 1 123
10 depth parameter.power 0.2437324 10 1 123
11 (Intercept) effect.power 0.5524946 20 1 123
12 nutrient effect.power 0.5524946 20 1 123
13 water effect.power 0.5524946 20 1 123
14 light effect.power 0.5524946 20 1 123
15 depth effect.power 0.5524946 20 1 123
16 (Intercept) parameter.power 0.5524946 20 1 123
17 nutrient parameter.power 0.5524946 20 1 123
18 water parameter.power 0.5524946 20 1 123
19 light parameter.power 0.5524946 20 1 123
20 depth parameter.power 0.5524946 20 1 123
21 (Intercept) effect.power 0.7474109 30 1 123
22 nutrient effect.power 0.7474109 30 1 123
23 water effect.power 0.7457698 30 1 123
24 light effect.power 0.7457698 30 1 123
25 depth effect.power 0.7457698 30 1 123
26 (Intercept) parameter.power 0.7474109 30 1 123
27 nutrient parameter.power 0.7474109 30 1 123
28 water parameter.power 0.7457698 30 1 123
29 light parameter.power 0.7457698 30 1 123
30 depth parameter.power 0.7457698 30 1 123
31 (Intercept) effect.power 0.8674559 40 1 123
32 nutrient effect.power 0.8674559 40 1 123
33 water effect.power 0.8674559 40 1 123
34 light effect.power 0.8674559 40 1 123
35 depth effect.power 0.8674559 40 1 123
36 (Intercept) parameter.power 0.8674559 40 1 123
37 nutrient parameter.power 0.8674559 40 1 123
38 water parameter.power 0.8674559 40 1 123
39 light parameter.power 0.8674559 40 1 123
40 depth parameter.power 0.8674559 40 1 123
41 (Intercept) effect.power 0.9323907 50 1 123
42 nutrient effect.power 0.9323907 50 1 123
43 water effect.power 0.9323907 50 1 123
44 light effect.power 0.9327242 50 1 123
45 depth effect.power 0.9327242 50 1 123
46 (Intercept) parameter.power 0.9323907 50 1 123
47 nutrient parameter.power 0.9323907 50 1 123
48 water parameter.power 0.9323907 50 1 123
49 light parameter.power 0.9327242 50 1 123
50 depth parameter.power 0.9327242 50 1 123
51 (Intercept) effect.power 0.9674484 60 1 123
52 nutrient effect.power 0.9674484 60 1 123
53 water effect.power 0.9674484 60 1 123
54 light effect.power 0.9674484 60 1 123
55 depth effect.power 0.9674484 60 1 123
56 (Intercept) parameter.power 0.9674484 60 1 123
57 nutrient parameter.power 0.9674484 60 1 123
58 water parameter.power 0.9674484 60 1 123
59 light parameter.power 0.9674484 60 1 123
60 depth parameter.power 0.9674484 60 1 123
No errors or warnings encountered during power curve generation!48.6.2.3 Fraction of Design Space Plot
上に示した通り、I-Optimal Designでは平均のばらつき(mean prediction variance)を最小とするデザインを選択します。Fraction of Design Space Plotはこのmean prediction varianceを評価する場合に有用です。
skprには、Fraction of Design Space Plotを表示するための関数、plot_fds関数があります。plot_fds関数の引数にgen_designの返り値を指定することでFraction of Design Space Plotが表示されます。plot_fds関数で描画される線の位置が低く、中央値が小さいほどI-Optimal Designではよいデザインとなります。
Fraction of Design Space Plot
plot_fds(od_i)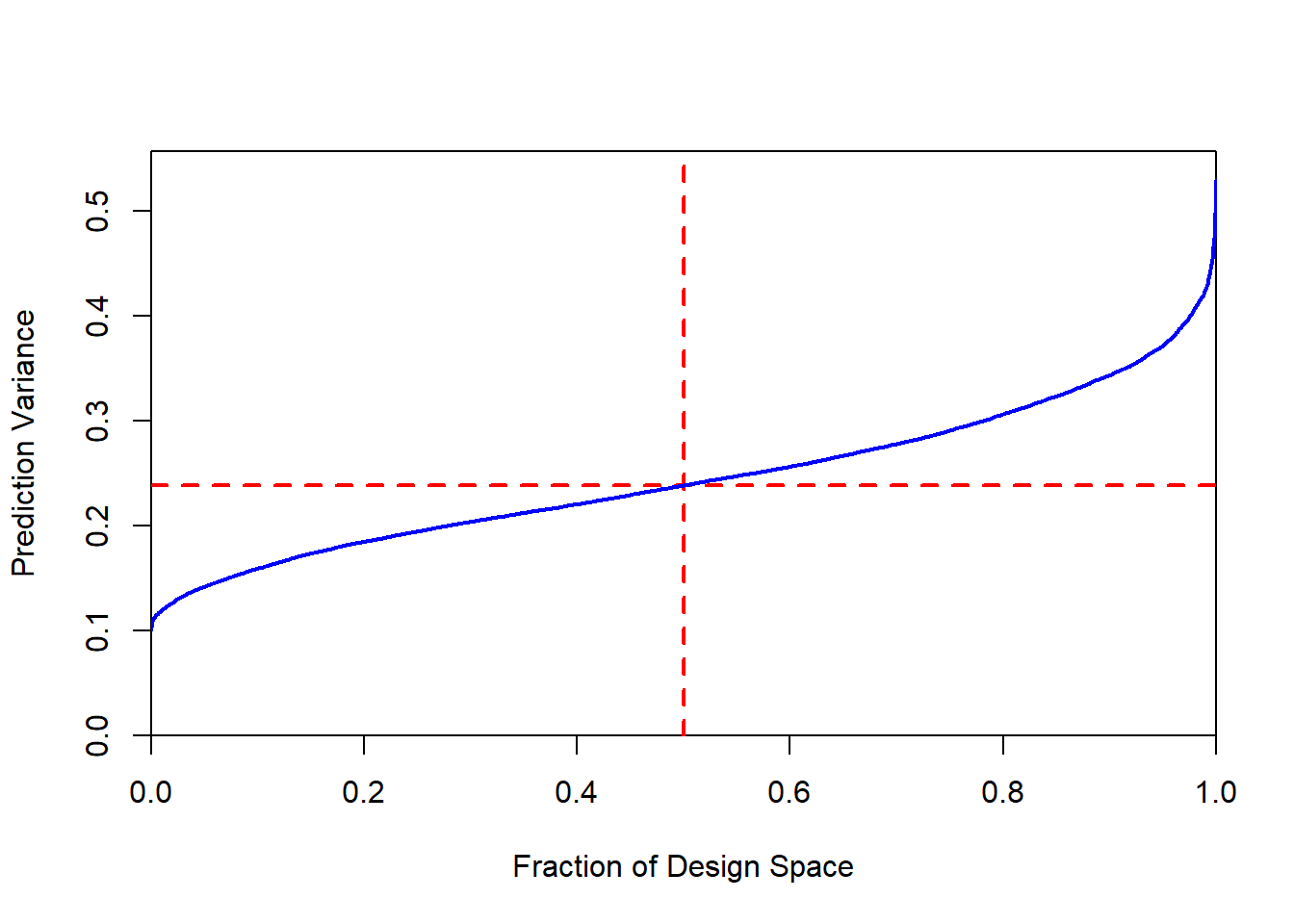
48.6.2.4 説明変数間の相関を評価する
説明変数間に相関があると、30章で説明した通り多重共線性の問題が起こりやすくなります。実験計画を作成した段階で相関があるかどうか評価することで、多重共線性が避けられるかどうかを評価できます。
plot_correlations関数はこの説明変数同士の相関を評価するための関数です。gen_design関数の返り値をplot_correlations関数の引数に取ることで、交互作用を含めた説明変数同士の相関をヒートマップとして示すことができます。
plot_correlation関数
plot_correlations(od_d)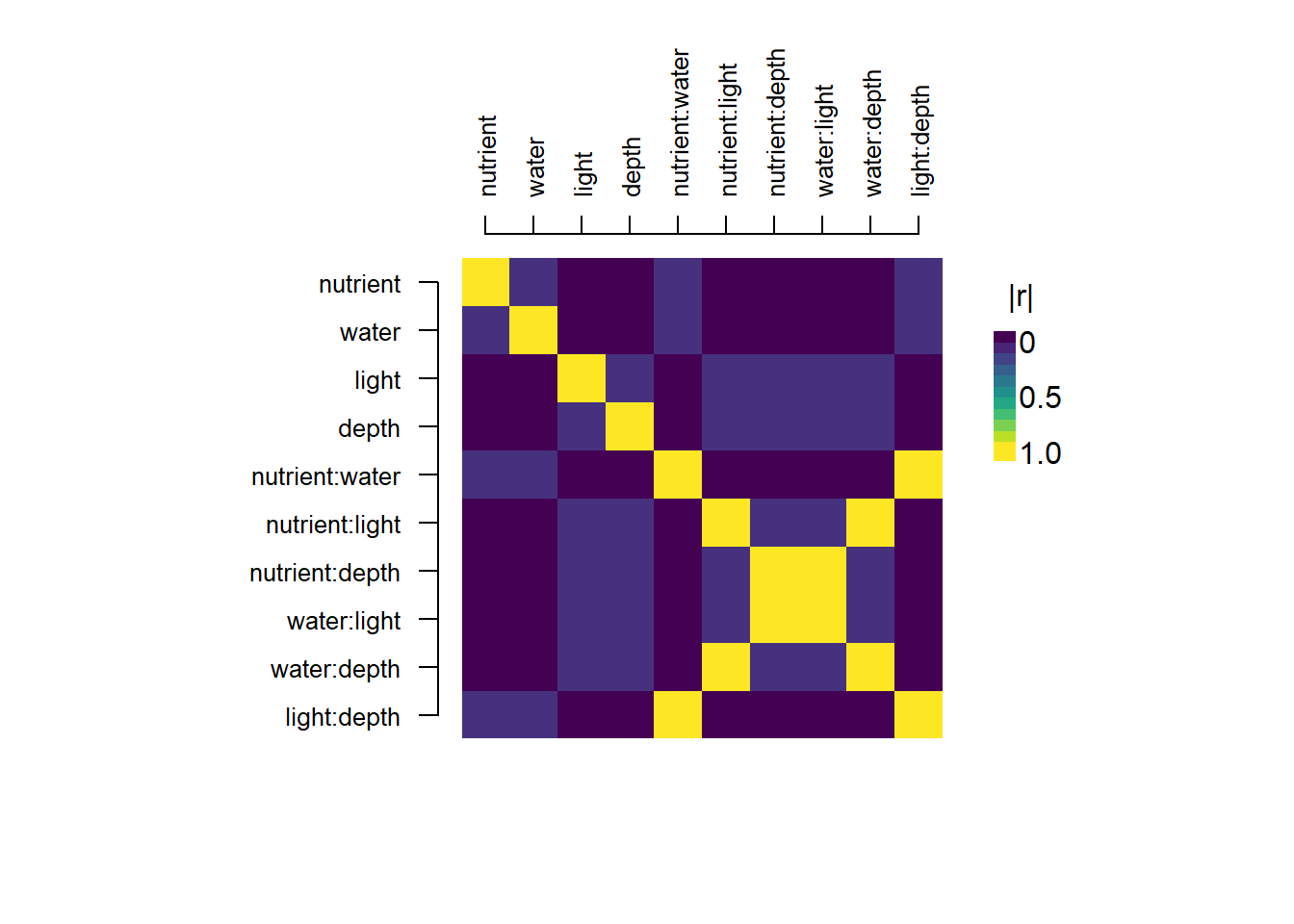
# 要因配置計画では説明変数同士の相関は0となる
gen_design(
candidateset = cand,
model = ~ nutrient * water * light * depth, trial = 16
) |>
plot_correlations()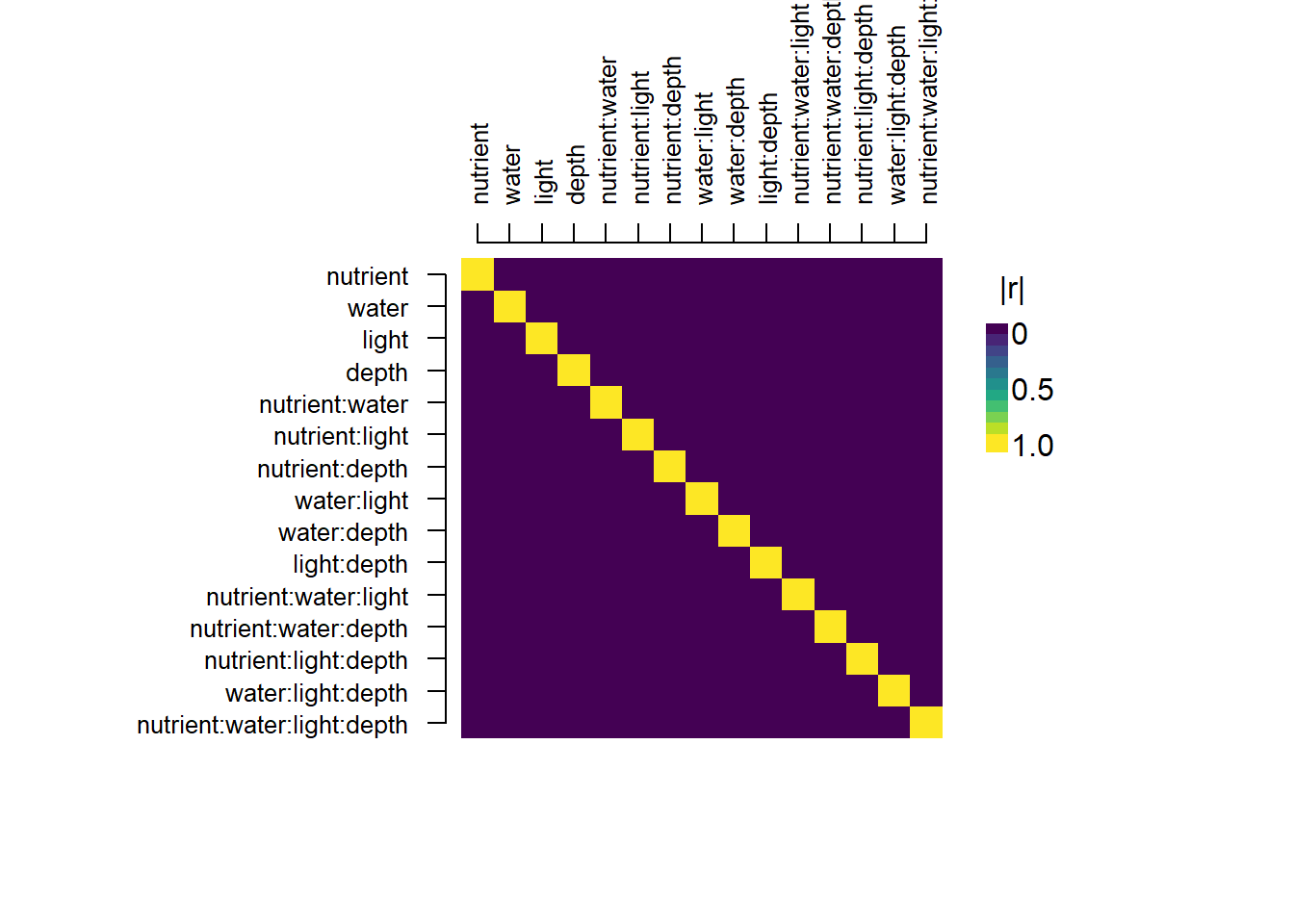
48.7 mixture experiment
説明変数全体の量は決まっていて、説明変数の割合を変える場合(例えばホットケーキミックス500g中の小麦粉やベーキングパウダーなどの原材料の量の割合を変える場合)の実験のことをmixture experimentと呼びます。mixture experimentでは、各説明変数の和が常に1となるよう実験計画が作成されます。
mixture experimentの実験計画にはskprは対応していないので、別のパッケージ(mixexp(Lawson and Willden 2016)、AlgDesign(Wheeler 2025))を用います。
Tipmixexpのインストールについて
mixexpは2026年4月にCRANから取り除かれています(removed)。インストールする際にはアーカイブからダウンロードするか、githubのレポジトリからインストールする(pak::pak("cran/mixexp"))必要があります。
48.7.1 mixexpパッケージ
mixexpはmixture experimentの実験計画作成のためのパッケージです。このパッケージではOptimal Designではなく、Simplex-Lattice Design (Scheffé 1958)に従い計画を作成します。
mixexpでの実験計画の作成はシンプルで、2つの関数を用います。一つは説明変数の数だけ設定するSCD関数、もう一つは説明変数の数と各説明変数の条件の数を指定するSLD関数です。SCD関数では各説明変数の条件の数を6とすることになります。
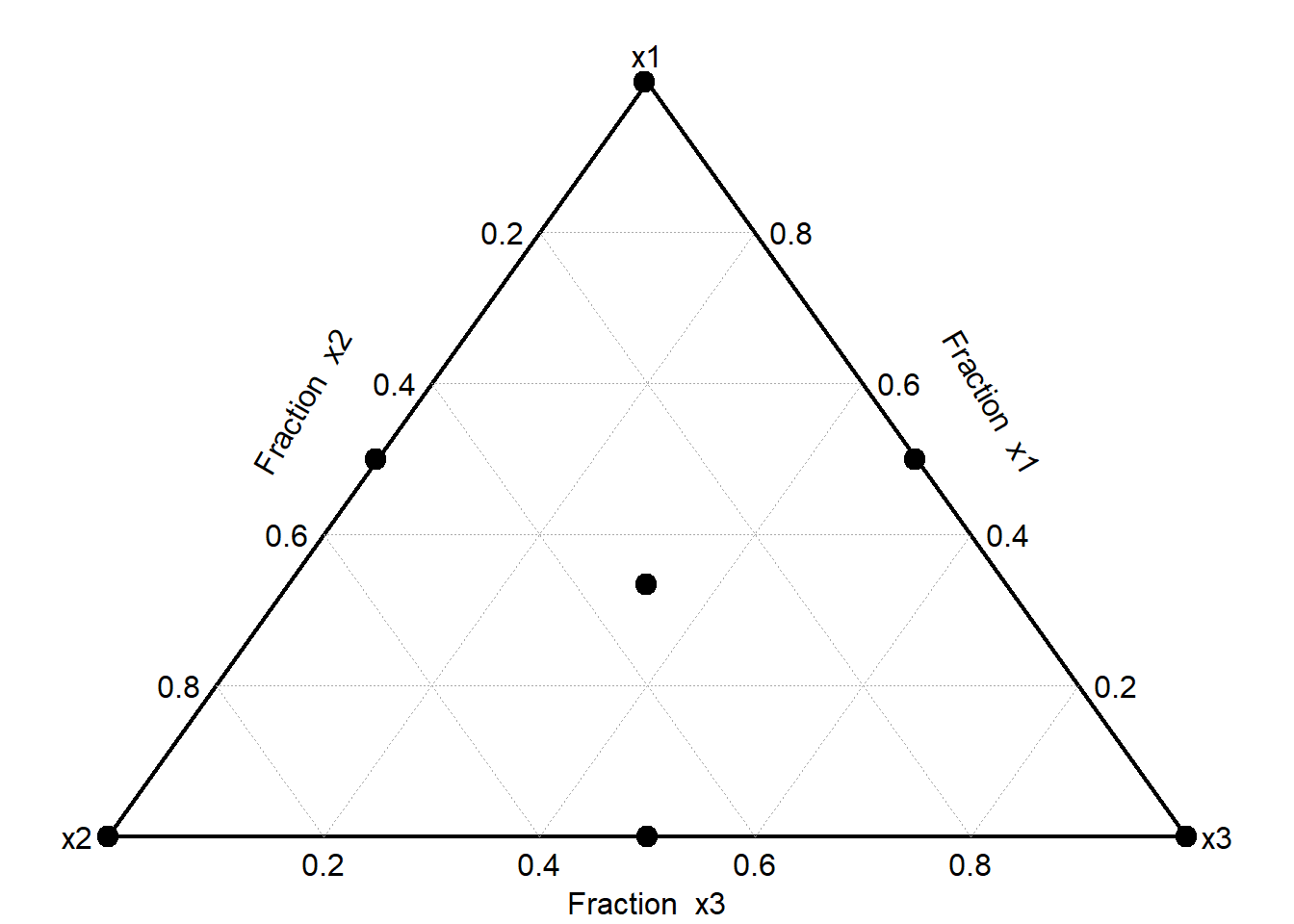
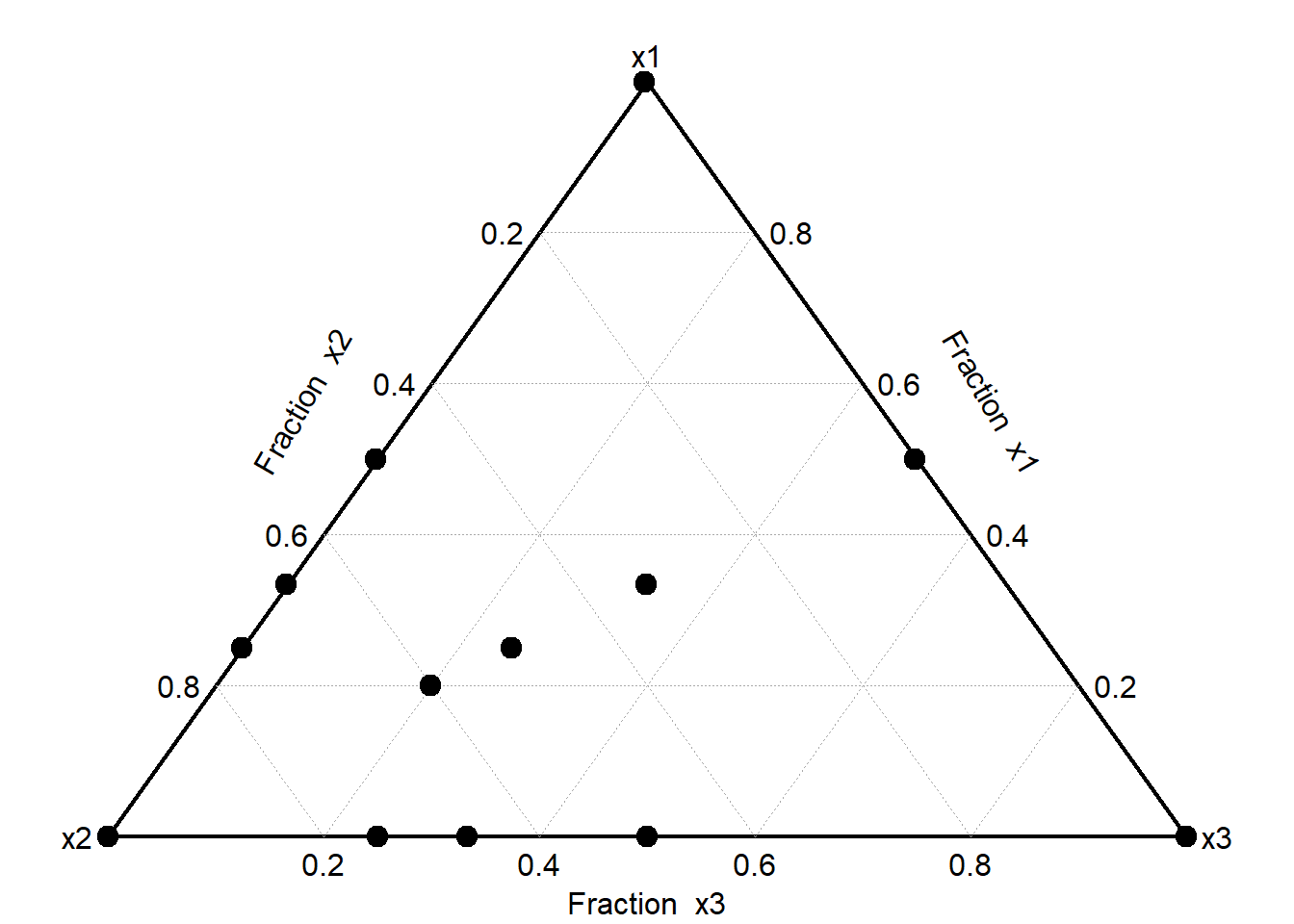
mixexpパッケージ:SCD関数とSLD関数
library(mixexp)Loading required package: latticeLoading required package: daewr x1 x2 x3 x4 x5
1 1.0 0.0 0 0 0
2 0.0 1.0 0 0 0
3 0.0 0.0 1 0 0
4 0.0 0.0 0 1 0
5 0.0 0.0 0 0 1
6 0.5 0.5 0 0 0 x1 x2 x3 x4 x5
1 1.0 0.0 0 0 0
2 0.8 0.2 0 0 0
3 0.6 0.4 0 0 0
4 0.4 0.6 0 0 0
5 0.2 0.8 0 0 0
6 0.0 1.0 0 0 0mixexpには実験計画を図で示してくれる、DesignPoints関数があります。SCD・SLD関数の返り値をDesignPoints関数の引数に取ると、実験計画に設定した量を三角形の図上の点(三角グラフ)で示してくれます。
48.7.1.1 量の最大・最小値を設定する:Xvert関数
上記のSCD、SLD関数では、すべての説明変数が0~1の条件を取ります。割合として考えれば不自然ではありませんが、ホットケーキミックスのレシピを調べる場合にはあまり使えません。ホットケーキミックスには小麦粉、砂糖、でんぷん、油脂、ベーキングパウダーなどが含まれます。最適なホットケーキミックスのレシピを考える時、砂糖100%や油脂100%、ベーキングパウダー100%のレシピを考える意味はほとんどありませんし、小麦粉が10%以下のレシピを考えてもあまりうまくいかないでしょう。
このように、成分(説明変数)ごとに最小、最大の量を指定しておきたい場合に用いるmixexpの関数がXvert関数です。Xvert関数では、説明変数の数(nfac)、各説明変数の最小割合(lc)、最大割合(uc)を指定することでmixture experimentsの計画を作成することができます。
x1 x2 x3 x4 x5 dimen
1 0.30 0.50 0.20 0.00000000 0.00000000 0
2 0.30 0.30 0.05 0.34999996 0.00000000 0
3 0.30 0.30 0.05 0.00000000 0.34999996 0
4 0.65 0.30 0.05 0.00000000 0.00000000 0
5 0.30 0.50 0.05 0.14999999 0.00000000 0
6 0.30 0.50 0.05 0.00000000 0.14999999 0
7 0.45 0.50 0.05 0.00000000 0.00000000 0
8 0.30 0.30 0.20 0.19999997 0.00000000 0
9 0.30 0.30 0.20 0.00000000 0.19999997 0
10 0.50 0.30 0.20 0.00000000 0.00000000 0
11 0.37 0.38 0.11 0.06999999 0.06999999 4 [1] 1 1 1 1 1 1 1 1 1 1 5 x1 x2 x3 x4 x5 dimen
1 0.9000000 0.03000000 0.02000000 0.04000000 0.01000003 0
2 0.8000001 0.10000001 0.02000000 0.04000000 0.04000000 0
3 0.8000000 0.03000000 0.10000001 0.04000000 0.03000000 0
4 0.8000000 0.03000000 0.02000000 0.09999999 0.05000000 0
5 0.8000001 0.10000001 0.02000000 0.07000000 0.01000000 0
6 0.8000001 0.03000000 0.10000001 0.06000000 0.01000000 0
7 0.8000001 0.10000001 0.04999999 0.04000000 0.01000000 0
8 0.8000001 0.05000000 0.10000001 0.04000000 0.01000000 0
9 0.8300000 0.10000002 0.02000000 0.04000000 0.01000000 0
10 0.8200001 0.03000000 0.10000001 0.04000000 0.01000000 0
11 0.8400000 0.03000000 0.02000000 0.09999999 0.01000000 0
12 0.8000000 0.07000000 0.02000000 0.10000000 0.01000000 0
13 0.8000000 0.03000000 0.06000001 0.10000000 0.01000000 0
14 0.8100001 0.03000000 0.02000000 0.04000000 0.10000000 0
15 0.8000000 0.04000001 0.02000000 0.04000000 0.10000000 0
16 0.8000000 0.03000000 0.03000000 0.04000000 0.10000000 0
17 0.8000000 0.03000000 0.02000000 0.05000000 0.10000000 0
18 0.8117647 0.05058825 0.04352941 0.05764706 0.03647059 448.7.2 AlgDesignパッケージ
AlgDesignはskprと同様にOptimal Designの実験計画を作成するためのパッケージです。AlgDesignにはmixture experimentの実験計画を作成するための関数である、gen.mixture関数があります。gen.mixtureはmixexpのSLDとほぼ同じ使い方の、説明変数の数と各説明変数の条件の数を指定して用いる関数です。
AlgDesign:gen.mixture関数
library(AlgDesign)
gen.mixture(5,5) |> head() # 5説明変数、各説明変数5段階の実験 X1 X2 X3 X4 X5
1 1.00 0.00 0.00 0 0
2 0.75 0.25 0.00 0 0
3 0.50 0.50 0.00 0 0
4 0.25 0.75 0.00 0 0
5 0.00 1.00 0.00 0 0
6 0.75 0.00 0.25 0 0