18 データセット
Rには、データ処理や統計の計算、関数などを試すために、データセットと呼ばれる、あらかじめ準備されているデータがあります。このデータセットの多くは、データセットを指定する変数名を用いればいつでも呼び出すことができます。また、多くのパッケージには、そのパッケージの機能を試すためのデータセットが備わっています。
Rにあらかじめ備わっているデータセットの一覧は、data関数を用いて確認することができます。data関数を引数なしで実行するとRのデフォルトのデータセットのリストが、package引数にパッケージ名を指定するとそのパッケージが持つデータセットのリストが表示されます。
data関数は、パッケージに含まれているデータセットを呼び出す際にも使用します。呼び出すときには、パッケージ名(パッケージをロードしているときは省略可)とそのデータセット名を引数に取ります。
以下の表1に、Rにあらかじめ備わっているデータセットの一覧とその簡単な説明を示します。
| データセット | データセットの説明 | データ型 |
|---|---|---|
| AirPassengers | 1949-1960年の国際線旅客数の推移 | 時系列 |
| BJsales | Box & Jenkins (1976)に記載されている売上データ | 時系列 |
| BJsales.lead | Box & Jenkins (1976)に記載されている売上の先行指標データ | 時系列 |
| BOD | 水中酸素要求量と水質の関係を示したデータ | データフレーム |
| CO2 | 低温馴化したイヌビエのCO2濃度と光合成速度に関するデータ | データフレーム |
| ChickWeight | ヒヨコの餌と体重増加の関係に関するデータ | データフレーム |
| DNase | DNA分解酵素を用いてELISA(Enzyme-Linked Immunosorbent Assay:酵素結合免疫吸着検定法)を開発した際のデータ | データフレーム |
| EuStockMarkets | 1991-1998年のヨーロッパ株式市場の終値 | 時系列 |
| Formaldehyde | クロモトープ酸と濃硫酸からホルムアルデヒドを生成した時の検量線データ | データフレーム |
| HairEyeColor | 592人の学生の髪と目の色 | 3次元アレイ |
| Harman23.cor | 7~17歳女性の体形データの相関係数 | リスト |
| Harman74.cor | 7-8グレードの学生の心理学テスト結果の相関係数 | リスト |
| Indometh | インドメタシンの薬物動態データ | データフレーム |
| InsectSprays | 殺虫剤で処理した昆虫の数 | データフレーム |
| JohnsonJohnson | J&Jの4半期の1株当たり売上 | 時系列 |
| LakeHuron | 1875-1972年のヒューロン湖の水位データ | 時系列 |
| LifeCycleSavings | 1960-1970年の各国の人口年齢構成と可処分所得 | データフレーム |
| Loblolly | テーダマツの成長データ | データフレーム |
| Nile | 1871-1970年のナイル川の年間流量 | 時系列 |
| Orange | オレンジの樹齢と幹の円周径の関係 | データフレーム |
| OrchardSprays | ラテン方角で行ったミツバチを退治するスプレーの評価 | データフレーム |
| PlantGrowth | 植物を2つの栽培条件で栽培した時の収量の違い | データフレーム |
| Puromycin | 細胞にPuromycinを与えた時の酵素の反応率 | データフレーム |
| Seatbelts | 1969-1984年のUKでの交通事故死者数とシートベルト義務化の関係 | 時系列 |
| Theoph | テオフィリンの薬物動態データ | データフレーム |
| Titanic | タイタニックの乗客データと死者数 | 4次元アレイ |
| ToothGrowth | モルモットへのビタミンC投与の象牙芽細胞の長さへの影響 | データフレーム |
| UCBAdmissions | UCバークレーの大学院進学データ | 3次元アレイ |
| UKDriverDeaths | 1969-1984年のUKでの交通事故死者数の推移 | 時系列 |
| UKgas | 1960-1986年のUKでのガス消費量の推移 | 時系列 |
| USAccDeaths | 1973-1978年のUSでの事故死者数の推移 | 時系列 |
| USArrests | 1973年のUS各州での人口10万人あたりの暴力的犯罪の件数 | データフレーム |
| USJudgeRatings | US最高裁の弁護士レーティング | データフレーム |
| USPersonalExpenditure | 1940~1960年のUSでの個人消費額の推移 | 行列 |
| UScitiesD | US都市間の距離 | 距離行列 |
| VADeaths | ヴァージニア州での1000人当たりの死亡率 | 行列 |
| WWWusage | インターネットサーバーへのアクセス人数の推移 | 時系列 |
| WorldPhones | 1951-1961年の各地域の電話の設置件数(1000台単位) | 行列 |
| ability.cov | 112人の6つのテストのスコアの相関行列 | リスト |
| airmiles | 1937-1960年のUSの旅客マイル数の推移 | 時系列 |
| airquality | 1973年のNYの大気汚染の度合い | データフレーム |
| anscombe | Anscombe (1989)のデータ | データフレーム |
| attenu | カリフォルニアの地震の最大加速度を複数箇所で測定した結果 | データフレーム |
| attitude | 35従業員からアンケートを取ったときの好意的な回答の割合 | データフレーム |
| austres | 1971-1993年のオーストラリアの住民の数 | 時系列 |
| beaver1 | 北中央ウィスコンシンのビーバーの体温データ(114行) | データフレーム |
| beaver2 | 北中央ウィスコンシンのビーバーの体温データ(100行) | データフレーム |
| cars | 車の速度とブレーキで止まるまでの距離 | データフレーム |
| chickwts | 鶏のエサの種類と体重 | データフレーム |
| co2 | 1959-1997のマウナロア山頂での大気CO2濃度 | 時系列 |
| crimtab | UKの犯罪者3000人の身長と指の長さ | 行列 |
| discoveries | 1860-1959年の偉大な発見の件数 | 時系列 |
| esoph | 食道がんの発生とたばこ・飲酒の関係 | データフレーム |
| euro | ヨーロッパ通貨間の為替レート | ベクター |
| euro.cross | ヨーロッパ通貨間の為替レート | マトリックス |
| eurodist | ヨーロッパ通貨間の為替レート都市間の距離 | 距離行列 |
| faithful | イエローストーン国立公園の間欠泉のデータ | データフレーム |
| freeny | Freenyの4半期収支のデータ | データフレーム |
| freeny.x | Freenyの4半期収支のデータ | 行列 |
| freeny.y | Freenyの4半期収支のデータ | 時系列 |
| infert | 中絶に関するデータ | データフレーム |
| iris | アヤメの花のデータ | データフレーム |
| iris3 | アヤメの花のデータ | 3次元アレイ |
| islands | 10000平方マイルを超える面積の島の数 | ベクター |
| ldeaths | 1974-1979年のUKにおける気管支炎等での死亡者数 | 時系列 |
| fdeaths | 1974-1979年のUKにおける気管支炎等での死亡者数(女性) | 時系列 |
| mdeaths | 1974-1979年のUKにおける気管支炎等での死亡者数(男性) | 時系列 |
| lh | 黄体形成ホルモンの血中濃度の変化 | 時系列 |
| longley | 1947-1962年のマクロ経済データ | データフレーム |
| lynx | 1821–1934年にカナダで捕らえられたリンクスの数 | 時系列 |
| morley | ミケルソンが測定した光の速度のデータ | データフレーム |
| mtcars | 車種と燃料消費のデータ | データフレーム |
| nhtemp | 1912-1971年のコネチカット州ニューヘブンの年平均気温 | 時系列 |
| nottem | 1920-1939念のノッティンガム城の月平均気温 | 時系列 |
| npk | 窒素・リン・カリウム肥料とエンドウ豆の収量の関係 | データフレーム |
| occupationalStatus | UKの父子のステータスの関連表 | 行列 |
| precip | アメリカの各都市の降雨量 | ベクター |
| presidents | 1945-1974年のアメリカ大統領の支持率 | 時系列 |
| pressure | 温度と水銀の蒸気圧の関係 | データフレーム |
| quakes | フィジー周辺のM4以上の地震の位置と深さ | データフレーム |
| randu | FortranのRANDU関数で作った3次元乱数 | データフレーム |
| rivers | 北米の主な河川の長さ | ベクター |
| rock | 油田から採取した石のデータ | データフレーム |
| sleep | 睡眠薬2種を摂取した学生の睡眠量のデータ | データフレーム |
| stackloss | アンモニアをニトリル酸に酸化する工場のデータ | データフレーム |
| stack.loss | アンモニアをニトリル酸に酸化する工場のデータ | ベクター |
| stack.x | アンモニアをニトリル酸に酸化する工場のデータ | 行列 |
| state.abb | US州名の略称 | ベクター |
| state.area | US州の面積 | ベクター |
| state.center | US州の中心の緯度・経度 | リスト |
| state.division | US州の地域区分 | ベクター |
| state.name | US州名 | ベクター |
| state.region | US州の位置分類 | ベクター |
| state.x77 | US州の人口・収入等のデータ | データフレーム |
| sunspot.month | 1749年以降に観察された太陽黒点の数 | 時系列 |
| sunspot.year | 1749–1983年に観察された太陽黒点の数(年別) | 時系列 |
| sunspots | 1749–1983年に観察された太陽黒点の数 | 時系列 |
| swiss | スイス・フランス語圏の地域の農業等のデータ | データフレーム |
| treering | 樹木の年輪幅のデータ | 時系列 |
| trees | ブラックチェリーの木の高さ・直径・体積のデータ | データフレーム |
| uspop | 1790-1970年のUS人口 | 時系列 |
| volcano | マウンガファウ火山の位置と標高のデータ | 行列 |
| warpbreaks | 布織の際の経糸切れの数のデータ | データフレーム |
| women | 30-39歳の女性の体重と身長のデータ | データフレーム |
Rの各データセットについては、中央大学理工学部の酒折先生のページに詳しく記載されています。
18.1 代表的なデータセット
18.1.1 iris
irisは3種のアヤメ(ヒオウギアヤメ(Iris setosa)、blue flag(Iris versicolor)、Virginia blueflag(Iris virginica))の花弁とがく片の長さと幅を記録したデータです。Ronald Fisherがこのデータを利用したことで有名で、Rでは最も見かけることが多いデータセットです。irisは150行のデータフレームで、左の列から、Sepal.Length(がく片の長さ)、Sepal.Width(がく片の幅)、Petal.Length(花弁の長さ)、Petal.Width(花弁の幅)、Species(種小名)の5列が登録されています。irisの初めの6行は以下の通りです。
iris
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa18.1.2 Nile
Nileはナイル川の水量を1871~1970年にかけて、年次で測定したデータです(単位は108 m3)。ナイル川では1902年にアスワン・ダムが、1970年にアスワン・ハイ・ダムが完成しています。このNileのデータセットでは、1898年頃(イギリスによるアスワン・ダムの建設開始時期)から水量が減っていることで有名で、非連続的な時系列データを取り扱うときの参考にされています。Nileは時系列型(ts)のデータセットです。
Nile
Nile
## Time Series:
## Start = 1871
## End = 1970
## Frequency = 1
## [1] 1120 1160 963 1210 1160 1160 813 1230 1370 1140 995 935 1110 994 1020
## [16] 960 1180 799 958 1140 1100 1210 1150 1250 1260 1220 1030 1100 774 840
## [31] 874 694 940 833 701 916 692 1020 1050 969 831 726 456 824 702
## [46] 1120 1100 832 764 821 768 845 864 862 698 845 744 796 1040 759
## [61] 781 865 845 944 984 897 822 1010 771 676 649 846 812 742 801
## [76] 1040 860 874 848 890 744 749 838 1050 918 986 797 923 975 815
## [91] 1020 906 901 1170 912 746 919 718 714 740
plot(Nile)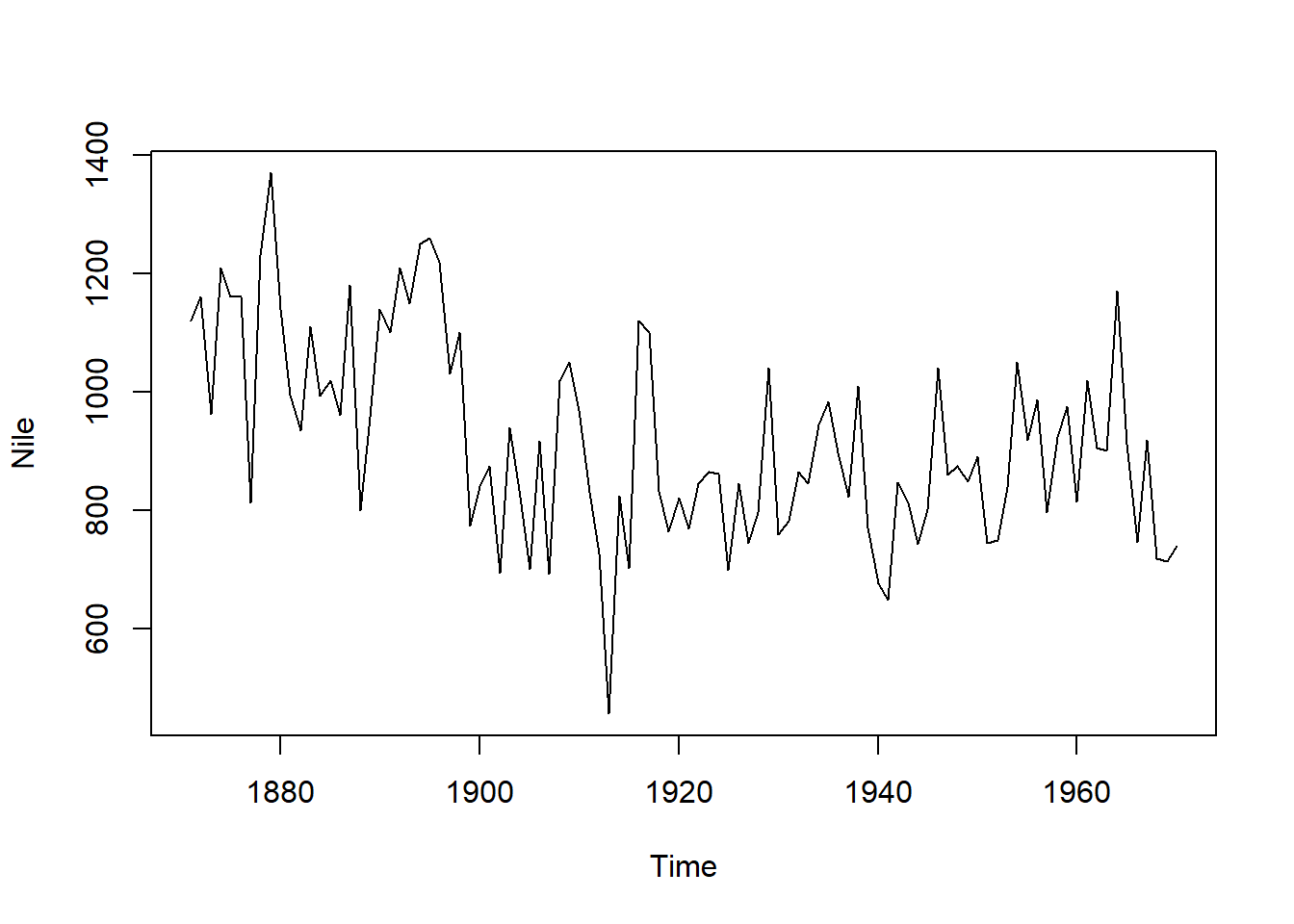
18.1.3 Titanic
Titanicは、タイタニック号に乗船していた旅客とクルーの性別・船室(一等船室、二等船室、三等船室、クルー)・年齢区分(大人・子供)・生死に関する人数を4次元のarrayとしたものです。RではTitanicを用いることはそれほどありませんが、kaggleという、機械学習の性能コンテストサイトでは機械学習の手習いとしてこのデータを用い、どのような性質の旅客であれば生存率が高いか、といった予測を行うモデルを作成するのによく用いられています。
Titanic
Titanic
## , , Age = Child, Survived = No
##
## Sex
## Class Male Female
## 1st 0 0
## 2nd 0 0
## 3rd 35 17
## Crew 0 0
##
## , , Age = Adult, Survived = No
##
## Sex
## Class Male Female
## 1st 118 4
## 2nd 154 13
## 3rd 387 89
## Crew 670 3
##
## , , Age = Child, Survived = Yes
##
## Sex
## Class Male Female
## 1st 5 1
## 2nd 11 13
## 3rd 13 14
## Crew 0 0
##
## , , Age = Adult, Survived = Yes
##
## Sex
## Class Male Female
## 1st 57 140
## 2nd 14 80
## 3rd 75 76
## Crew 192 2018.1.4 BostonHousing
BostonHousingも、Rでというよりは機械学習の分野で、家賃の予測モデル作成の手習いとしてよく用いられています。BostonHousingは、その名の通りボストンの住宅価格と地域周辺の犯罪率・住宅の部屋数・税率・高速道路へのアクセスなどを、1970年のセンサス(国勢調査)から収集してまとめたものです。Rでは、mlbenchパッケージ (Leisch and Dimitriadou 2021; Newman et al. 1998)(機械学習のベンチマークデータセットを集めたもの)に含まれており、使用するためにはmlbenchパッケージをインストール・ロードする必要があります。BostonHousingのデータ型はデータフレームです。
BostonHousing
pacman::p_load(mlbench)
data("BostonHousing")
head(BostonHousing)
## crim zn indus chas nox rm age dis rad tax ptratio b lstat
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
## medv
## 1 24.0
## 2 21.6
## 3 34.7
## 4 33.4
## 5 36.2
## 6 28.718.1.5 diamonds
diamondsはグラフ作成パッケージである、ggplot2に含まれるデータセットです。ggplot2 (Wickham 2016)を用いたグラフ作成例ではよく用いられています。diamondsはダイヤモンドのカラット数、透明性、カット、価格などをまとめたデータフレームです。
diamonds
head(ggplot2::diamonds)
## # A tibble: 6 × 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.4818.1.6 palmerpenguins
penguinsはirisの代わりになるデータセットとして、QuartoのGallaryなどで利用されているデータです。Rでは、palmerpenguinsパッケージ(Horst et al. 2020)で提供されています。penguinsは344行8列のデータセットで、ペンギンの種類(Adelie:アデリーペンギン、Chinstrap:ヒゲペンギン、Gentoo:ジェンツーペンギン)、生息地(Biscoe:ビスコー諸島、Dream:ドリーム島、Torgersen:トージャーセン島)、クチバシの長さ(Bill length)、クチバシの高さ(Bill depth)、前ビレの長さ(Flipper length)、体重(Body mass)、性別、測定年を記録したものです。
このパッケージの作者であるDr. Allison HorstのホームページにはRに関わるイラストがたくさん記載されていますので、一読してみると良いでしょう。また、このpenguinsデータセットについて詳しく書かれたプレゼンテーションも公開されています。近い将来には若いRユーザーはirisではなくpenguinsを用いるようになるのかもしれません。
palmerpenguins
pacman::p_load(palmerpenguins)
summary(penguins)
## species island bill_length_mm bill_depth_mm
## Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
## Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
## Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
## Mean :43.92 Mean :17.15
## 3rd Qu.:48.50 3rd Qu.:18.70
## Max. :59.60 Max. :21.50
## NAs :2 NAs :2
## flipper_length_mm body_mass_g sex year
## Min. :172.0 Min. :2700 female:165 Min. :2007
## 1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
## Median :197.0 Median :4050 NAs : 11 Median :2008
## Mean :200.9 Mean :4202 Mean :2008
## 3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
## Max. :231.0 Max. :6300 Max. :2009
## NAs :2 NAs :2
18.1.7 Gapminder
Gapminderは1952~2007年の各国のGDP、一人当たりGDP、寿命、人口をデータフレームとしてまとめたものです。このデータは、Gapminder Foundation(スウェーデンのNPO、所得格差の認知を推進する活動を行っている)が提供しているデータです。このデータも、Rでのグラフ作成の例でよく用いられているものです。Rでは、gapminderパッケージ (Bryan 2023)にデータセットが含まれています。
gapminder
pacman::p_load(gapminder)
head(gapminder::gapminder)
## # A tibble: 6 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.