パッケージの読み出し
pacman::p_load(tidyverse)現在のRでは、デフォルトのグラフ作成関数はデータの確認に用いられていることが多く、プレゼンテーションや論文など、人に見せるためのきれいなグラフを作成する場合には、ほとんどの場合ggplot2が用いられています。ggplot2を用いると、美しいグラフを統一感のある記法で簡単に描画することができます。
ggplot2には、その使い方についてのみ書かれた教科書が多数出ているぐらいに沢山の関数・引数が設定されています。この章での解説はggplot2の紹介に留めますが、興味のある方はリファレンスやチートシート、教科書(ggplot2: Elegant Graphics for Data Analysis、R graphic cookbook、R graphic cookbook 日本語版など)を読むことをお勧めします。
ggplot2はtidyverseに含まれるパッケージの一つですので、tidyverseを呼び出すことで使用することができます。他のtidyvereseの機能である、dplyrやtidyr、パイプ演算子などとも相性が良く、これらをggplot2と同時に用いるのが一般的です。
パッケージの読み出し
pacman::p_load(tidyverse)ggplot2では、まずggplot関数にデータフレームを引数として与えます。ggplot2では、データはほぼ常にデータフレームで与える必要があります。ggplot関数はデータの設定のための関数で、データフレームを引数にしてggplot関数だけを実行しても、空白が表示されるだけです。ggplot関数は第一引数にデータフレームを取るため、パイプ演算子を用いてデータフレームをggplot関数につなぐのが一般的です。
ggplot関数のみを用いる
# ggplot関数だけでは何も表示されない
p <- iris |> ggplot()
p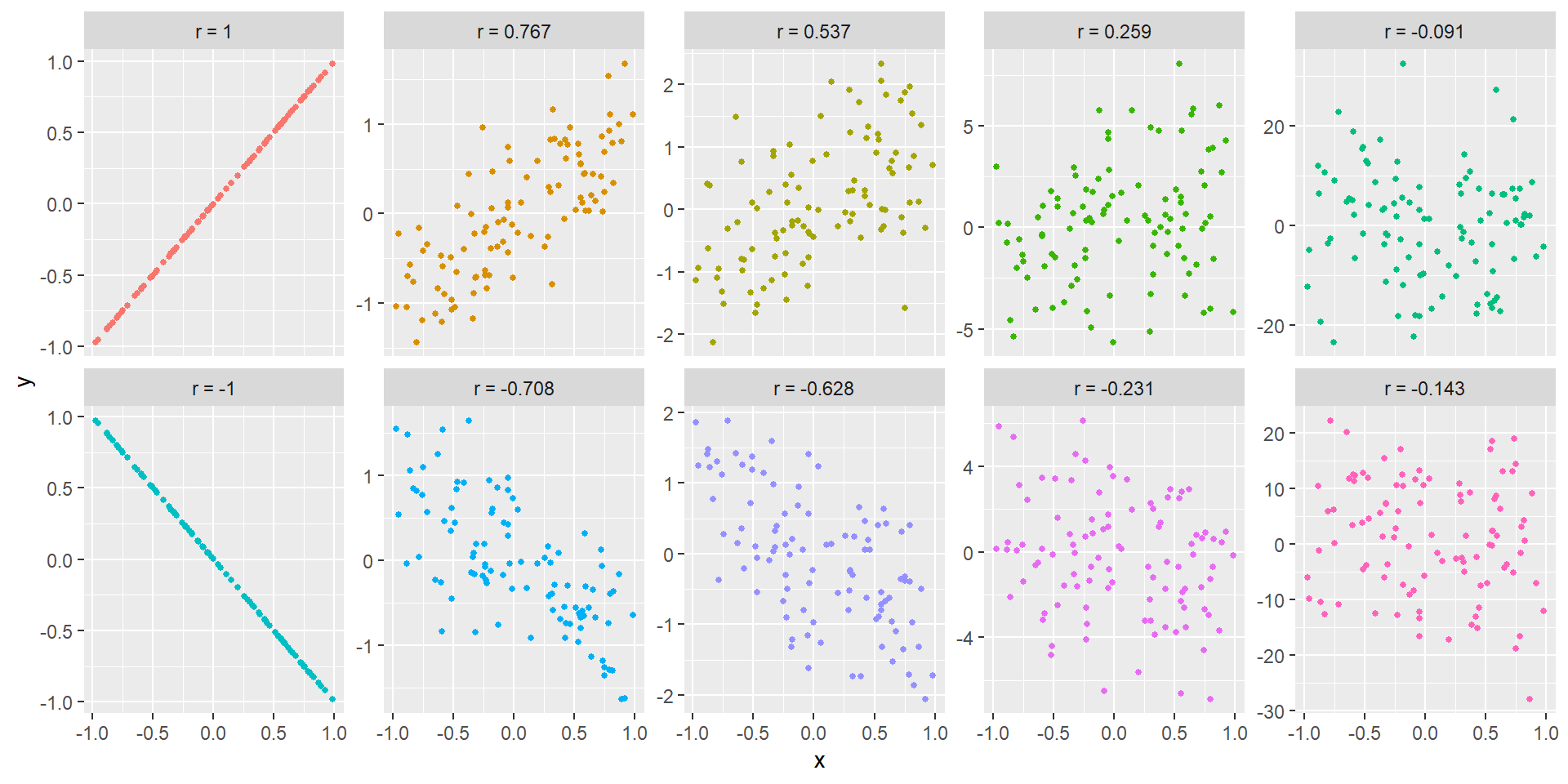
ggplot関数は、引数にaes関数を取ります。このaesはaesthetic(エステティック)mappingの略です。この「エステティック」というのは、美容のエステと同じ言葉で、「美的な」という意味を持ちます。ggplot2では、aes関数内でグラフのx軸、y軸の値などの要素、色や点のサイズ等を指定します。この指定には、ggplot関数の引数であるデータフレームの列名を文字列ではなく、そのまま使用することができます。
下の例では、データフレームであるirisの列から、Sepal.Lengthをxに、Sepal.Widthをyに設定したものです。aes関数を引数にしてggplot関数を実行すると、点や線などのグラフの要素は表示されませんが、縦と横の軸だけは表示されます。
aesでグラフの要素を指定
# 軸だけが表記される
iris |> ggplot(aes(x = Sepal.Length, y = Sepal.Width))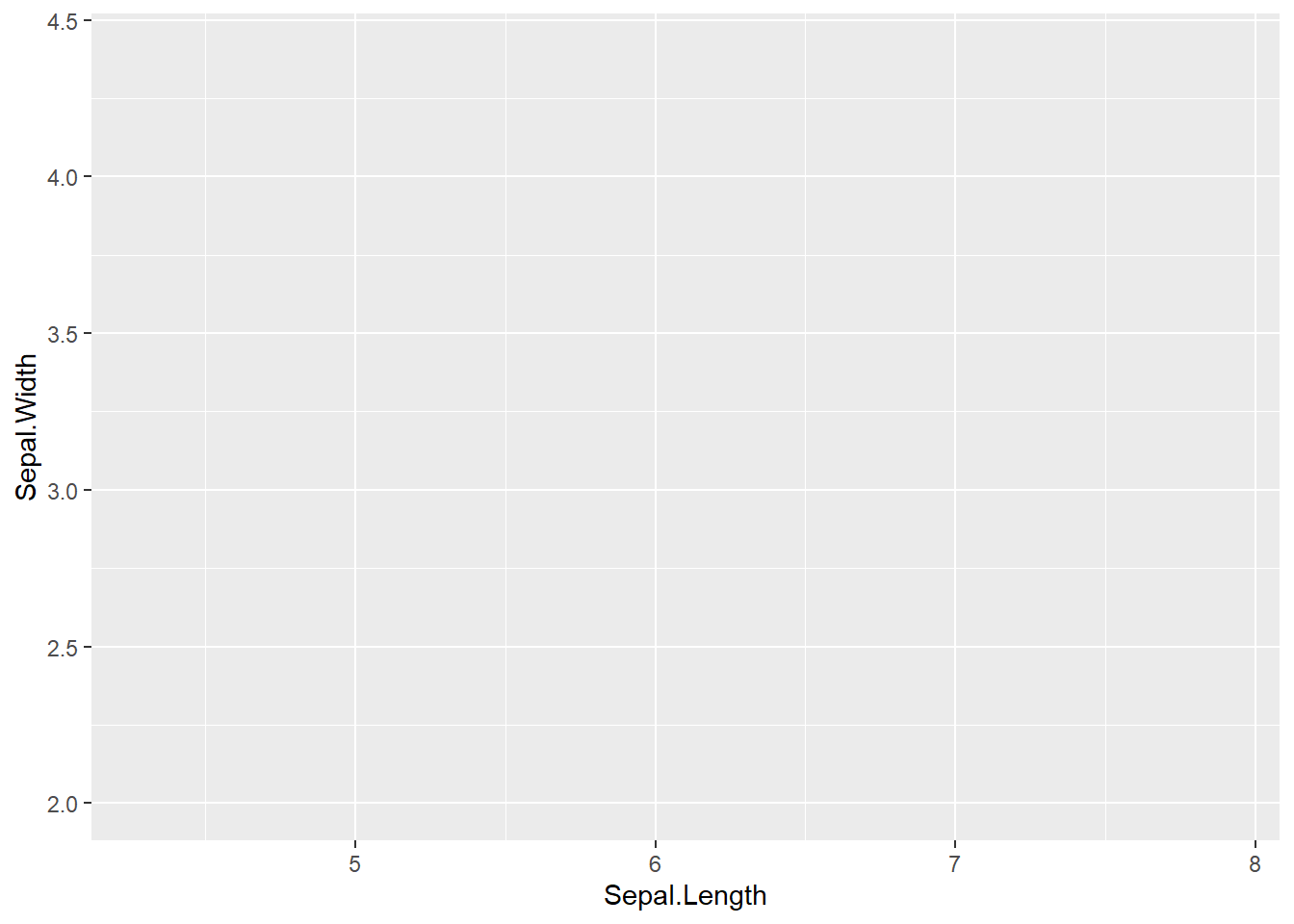
ggplot2でグラフを表示するためには、グラフの種類を指定する関数である、geom関数を用いる必要があります。例えば、散布図を描画するためのgeom関数は、geom_point関数です。このgeom関数の中でも、データフレームやaesを設定することができます。ただし、このgeom関数だけでは、グラフを表示することはできません。先程説明した、ggplot関数と組み合わせる必要があります。
geom関数
# geom関数だけではグラフを記述できない
geom_point(data = iris, aes(x = Sepal.Length, y = Sepal.Width))mapping: x = ~Sepal.Length, y = ~Sepal.Width
geom_point: na.rm = FALSE
stat_identity: na.rm = FALSE
position_identity geom関数は、ggplot関数に+でつなぐ必要があります。まず、データフレームを引数にしたggplot関数を準備し、その関数に足し算でgeom_point関数をつなぎ、ggplot関数内もしくはgeom_point関数内でaesを設定すると、グラフが表示されます。
ggplot関数とgeom関数を+でつなぐ
# geom関数内でaesを設定する
iris |>
ggplot() +
geom_point(aes(x = Sepal.Length, y = Sepal.Width))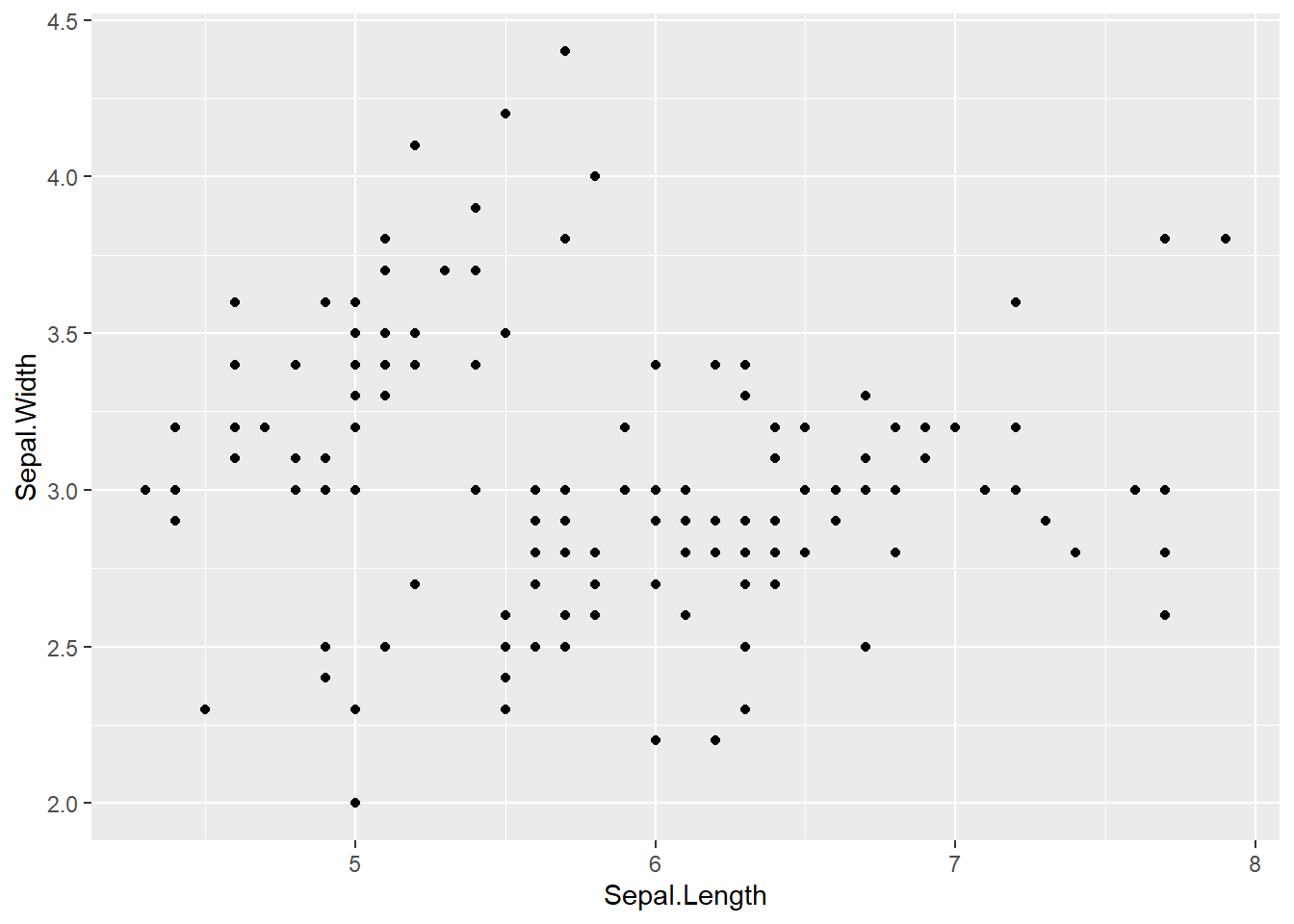
ggplot関数内でaesを指定する
# ggplot関数内でaesを設定する(上と同じ)
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point()
ggplot2では、ggplot関数とgeom関数をつなぐために、+の記号を用います。この+はジェネリック関数として設定されており、ggplot2内では足し算とは異なる機能を持ちます。詳しくはggplot2のリファレンスをご一読ください。
以下の表1に、代表的なgeom関数の一覧を示します。
| geom関数 | グラフの種類 | aesで必須となる引数 |
|---|---|---|
| geom_point | 散布図 | x, y |
| geom_text | 文字の散布図 | x, y, label |
| geom_line | 線グラフ(x軸の小さいものからつなぐ) | x, y |
| geom_ribbon | リボン | xmax, xmin, ymax, ymin(xかyのどちらか) |
| geom_path | 線グラフ(データフレームの行順につなぐ) | x, y |
| geom_step | ステップ関数 | x, y |
| geom_abline | 直線(傾きと切片で指定) | intercept, slope |
| geom_hline | 水平線(横線) | yintercept |
| geom_vline | 垂直の線(縦線) | xintercept |
| geom_bar | 棒グラフ | x, y |
| geom_dotplot | ドットプロット | x, y(片方のみ) |
| geom_function | 関数を線形で表記 | fun |
| geom_boxplot | 箱ひげ図 | x, y(片方でも可) |
| geom_histogram | ヒストグラム | x, y(片方のみ) |
| geom_density | 確率密度 | x, y(片方のみ) |
| geom_jitter | ジッタープロット | x, y(片方でも可) |
| geom_violin | バイオリンプロット | x, y(片方でも可) |
| geom_errorbar | エラーバー | xmax, xmin, ymax, ymin |
| geom_linerange | エラーバー(横棒無し) | xmax, xmin, ymax, ymin |
| geom_pointrange | フォレストプロット(点と線) | x, y, xmax, xmin, ymax, ymin |
| geom_bin_2d | ヒートマップ | x. y |
| geom_contour | 等高線 | x, y |
| geom_map | 地図表記 | map_id |
| geom_polygon | 多角形 | x, y |
ggplot2には、qplotという関数も準備されています。qplot関数は「Quick plot」の略で、plot関数のように1つの関数だけでグラフの作成が完了します。ただし、このqplot関数で凝ったグラフを作成することは難しいため、現在ではその使用は非推奨とされています。
qplot関数
# 上と同じグラフをqplotで描画
qplot(Sepal.Length, Sepal.Width, data = iris, geom="point")Warning: `qplot()` was deprecated in ggplot2 3.4.0.
表1に示した通り、geom関数にはgeom_point以外にもたくさんの関数が設定されています。以下に各geom関数を用いて作成できるグラフを紹介します。
geom_textは、テキストをグラフ上に表示するための関数です。geom_textはaesにx、y、labelの3つの引数を設定し、そのx、yの位置にlabelで指定した文字列を表示します。
geom_text関数
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, label = Species)) +
geom_text()
geom_lineはaesのx、yに設定した点を結ぶ線、つまり線グラフを描画するための関数です。geom_lineでは、線は必ずxの小さい値から大きい値へと点を繋いでいく形で線が描画されます。
geom_line関数
economics |>
ggplot(aes(x = pop, y = pce)) +
geom_line()
geom_ribbonは、幅のあるグラフ(リボン)を描画するための関数です。geom_ribbonはx、ymin、ymaxの3つの引数を取り、xで指定した位置にymin-ymaxの間を幅とするリボンを描画します。引数として、y、xmin、xmaxの3つを取ることもできます。ymin、ymaxを指定した場合にはリボンは横向き、xmin、xmaxを指定した場合にはリボンは縦向きになります。
geom_ribbon関数
d <- data.frame(
time = time(Nile) |> as.numeric(),
Nile100 = Nile |> as.numeric(),
Nile90 = Nile |> as.numeric() * 0.9 ,
Nile110 = Nile |> as.numeric() * 1.1)
d |>
ggplot(aes(x = time, ymax = Nile110, ymin = Nile90)) +
geom_ribbon()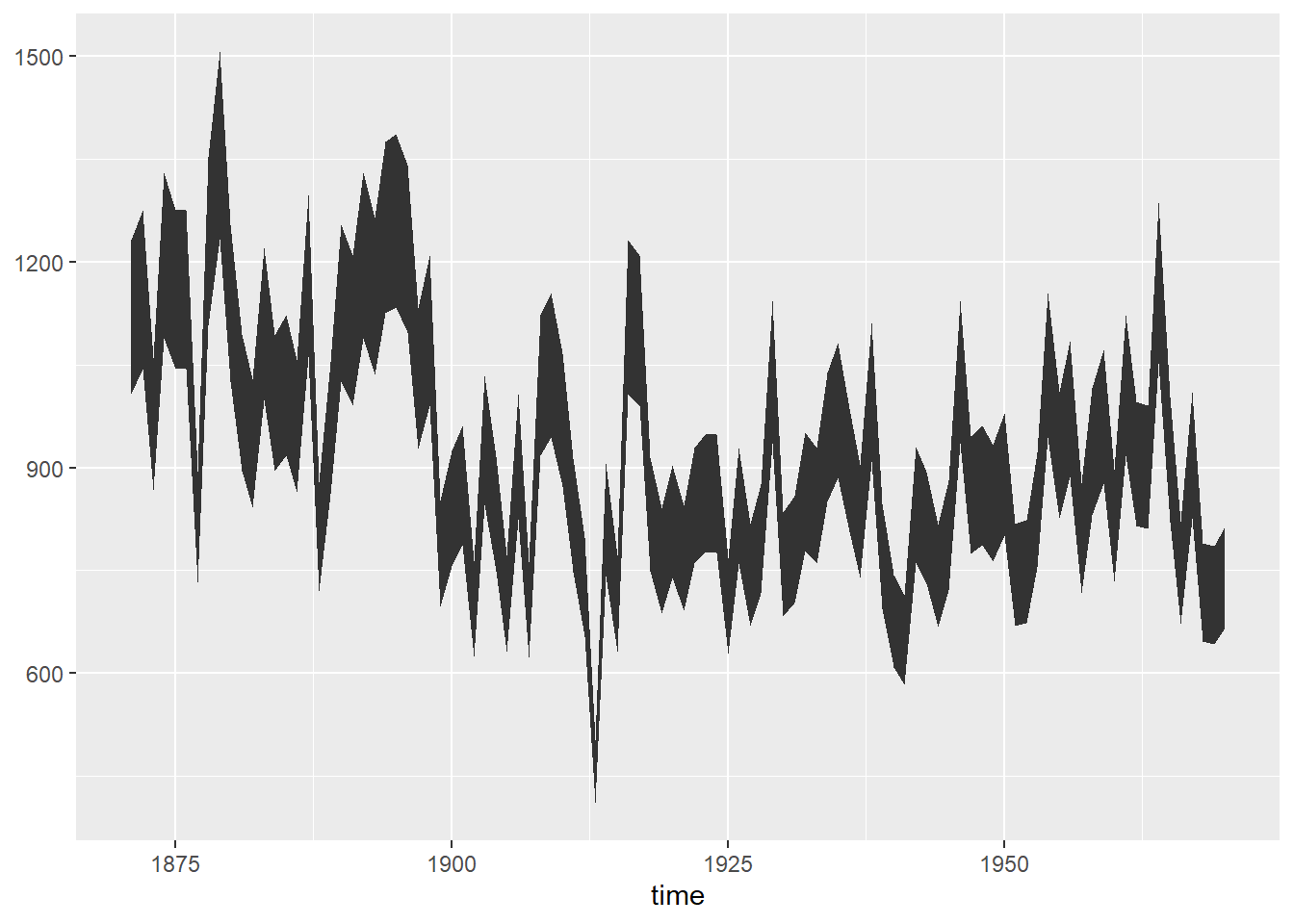
geom_smoothはgeom_point等で表示した点に対して、回帰の式をあてはめ、そのグラフを表示するための関数です。特に引数を指定していない場合、30章で説明するloess回帰をあてはめ、回帰を行った線を表示します。また、95%信頼区間をgeom_ribbonと同様の表記で示します。
geom_smooth関数
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(size = 2) +
geom_smooth()`geom_smooth()` using method = 'loess' and formula = 'y ~ x'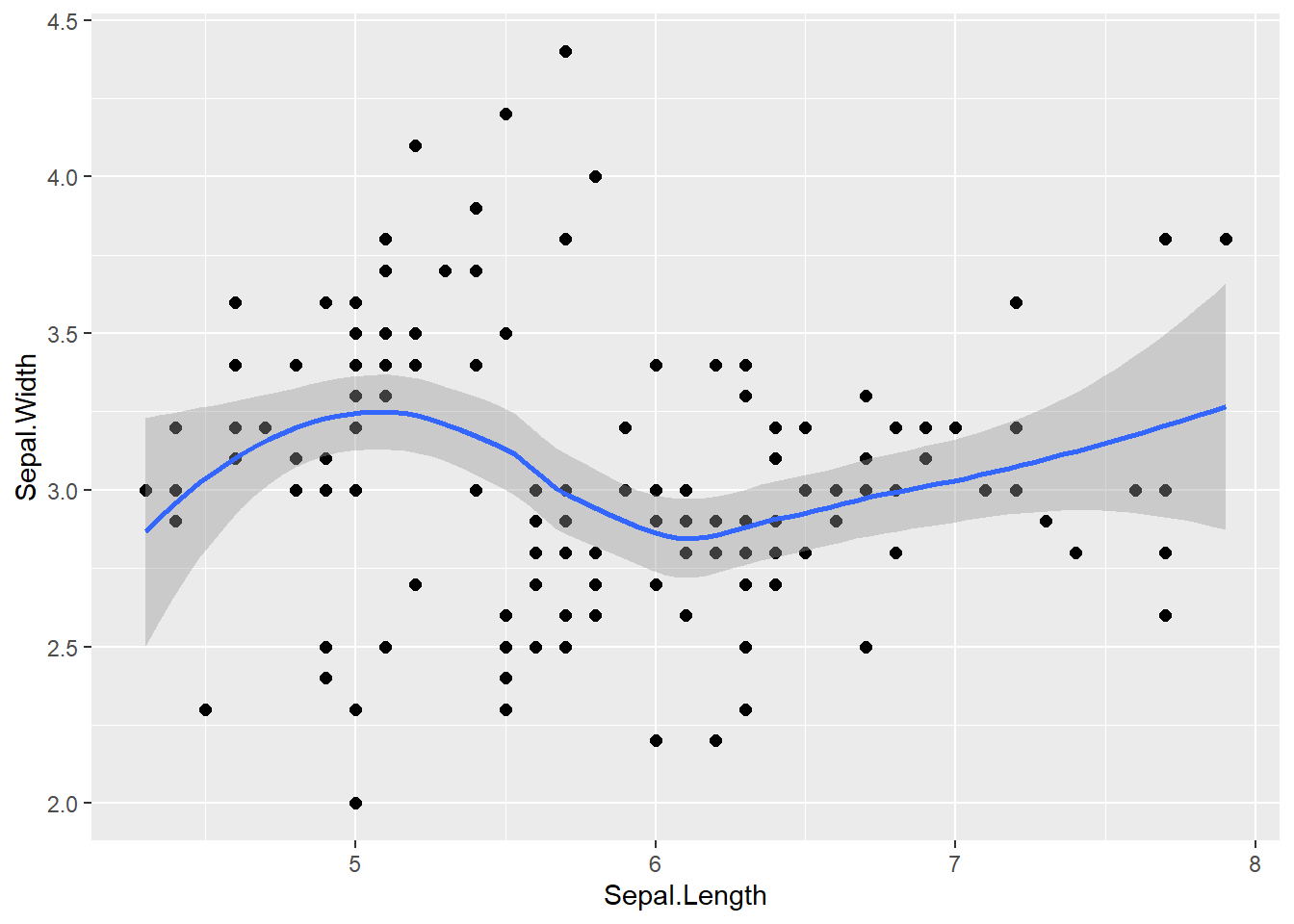
直線での回帰を行う場合には、引数にmethod="lm"を指定します。また、se引数をFALSEに指定すると、信頼区間の表示を消すことができます。
geom_smoothで直線回帰
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(size = 2) +
geom_smooth(method = "lm", se = FALSE)`geom_smooth()` using formula = 'y ~ x'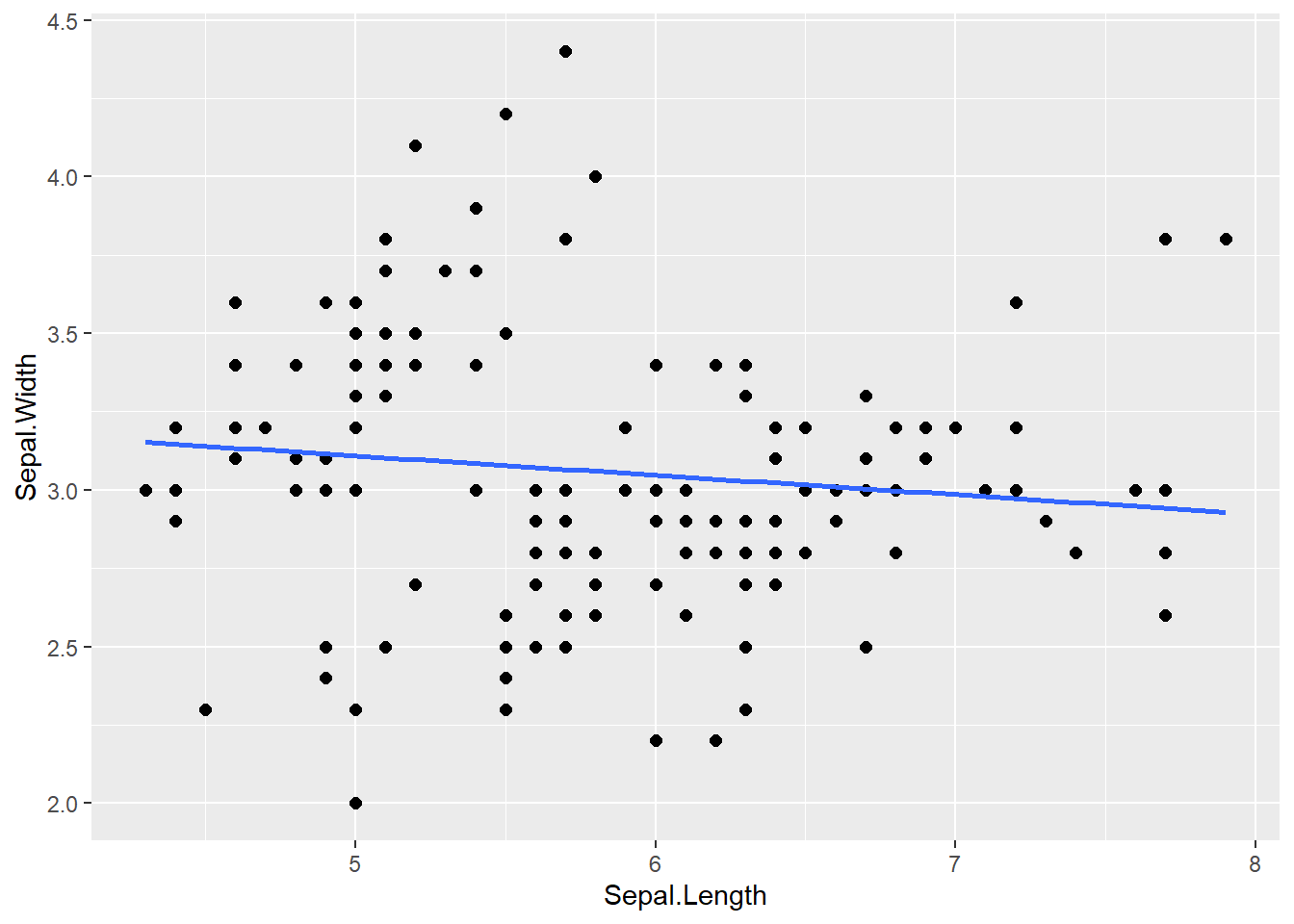
データフレームの因子の列に従ってグラフを分けて回帰したい場合には、aes関数内でgroup引数にその因子を設定します。以下の例ではirisのSpeciesをgroup引数に設定し、アヤメの種ごとに回帰を行っています。
group引数を設定する
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, group = Species)) +
geom_point(size = 2) +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'
aesにcolorやfillを設定することでも因子ごとに回帰を行うことができます。
color引数やfill引数を設定する
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species, fill = Species)) +
geom_point(size = 2) +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'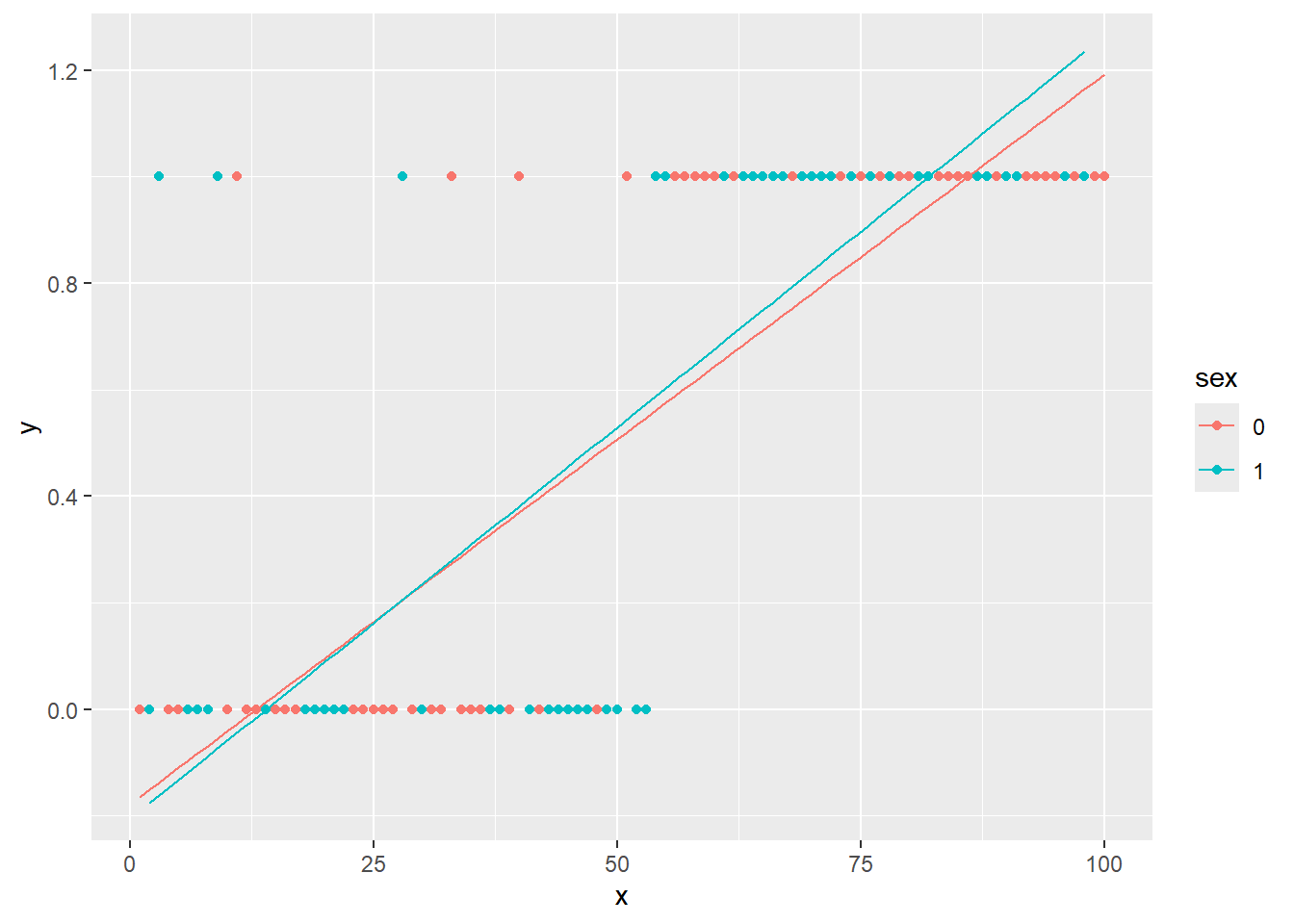
geom_pathは、xの大きさに関わらず、データフレームの上の行から線をつなぐ関数です。データフレームを時系列に並べておき、2変数の時間変化を追うような場合に利用します。
geom_pathを用いる場合には、一色の線では線のどちらの端が上の行で、どちらが下の行かわからないため、通常は行の順番にそって線の色を変えることになります。色を指定したい場合には、aesの引数にcolorを設定します。colorには、データフレームの列のうち、日時などを設定します。このように設定することで、日時と共に線の色が変わるようなグラフを作成することができます。
geom_path関数
economics |>
ggplot(aes(x = uempmed, y = pce, color = date)) +
geom_path()
Rのstep関数を用いた場合と同様のグラフを記述する場合には、geom_step関数を用います。
geom_step関数
iris |>
ggplot(aes(x = 1:150, y = Sepal.Length)) +
geom_step()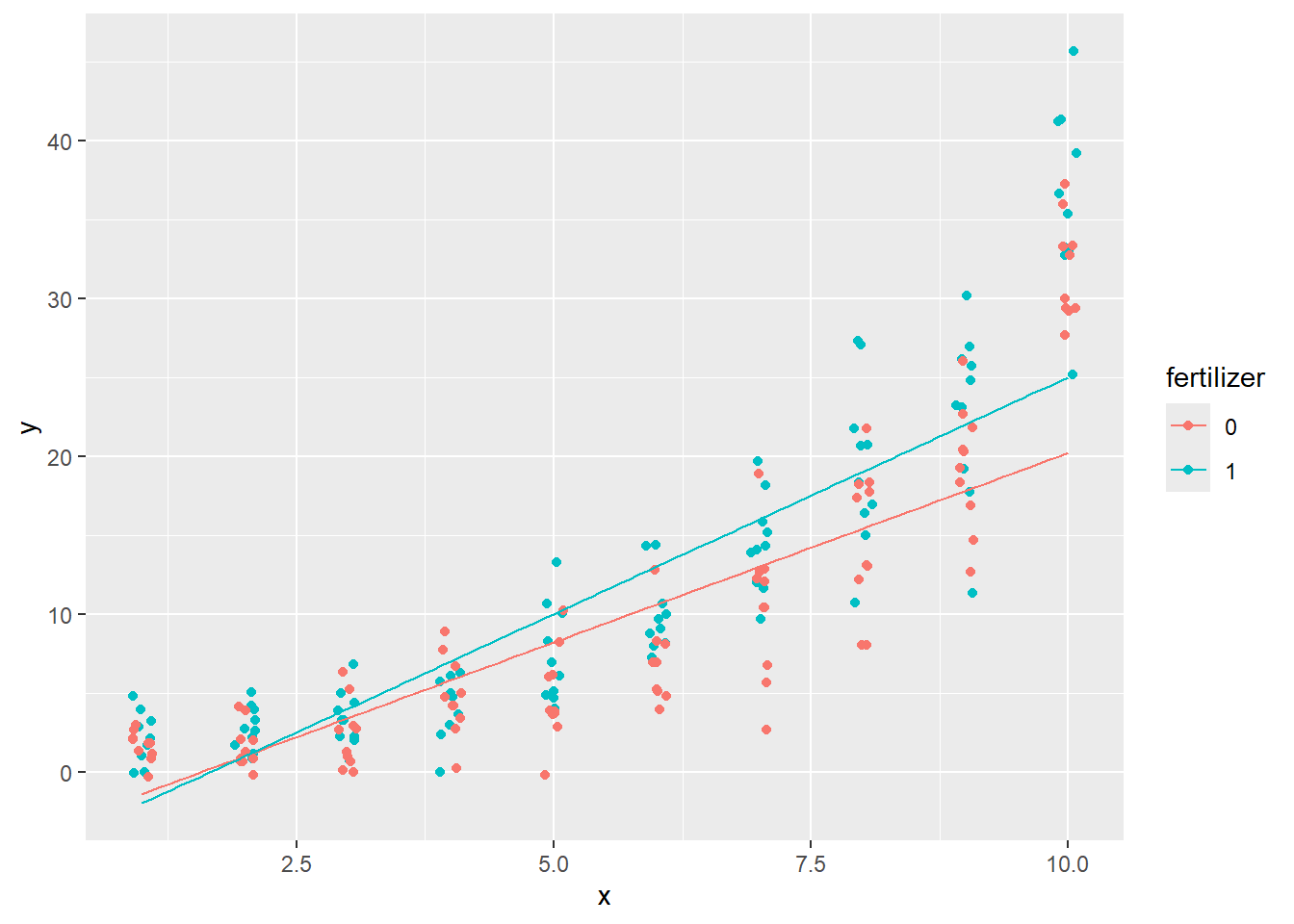
グラフ上に直線を描く場合には、geom_abline、geom_vline、geom_hlineを用います。geom_ablineは切片(intercept)と傾き(slope)を指定し、その切片・傾きを持つ直線を引くものです。geom_vlineは垂直な線(vertical line)、geom_hlineは水平な線(horizontal line)を描画します。geom_vlineはx軸と交わるため、x軸の切片(xintercept)の設定が必要です。同様にgeom_hlineはy軸と交わるため、y軸の切片(yintercept)を設定します。
geom_abline関数など
ggplot()+
geom_abline(intercept = 10, slope = -1) +
geom_vline(xintercept = 10, color = "red") +
geom_hline(yintercept = 10, color = "blue") +
xlim(0, 15) +
ylim(0, 15)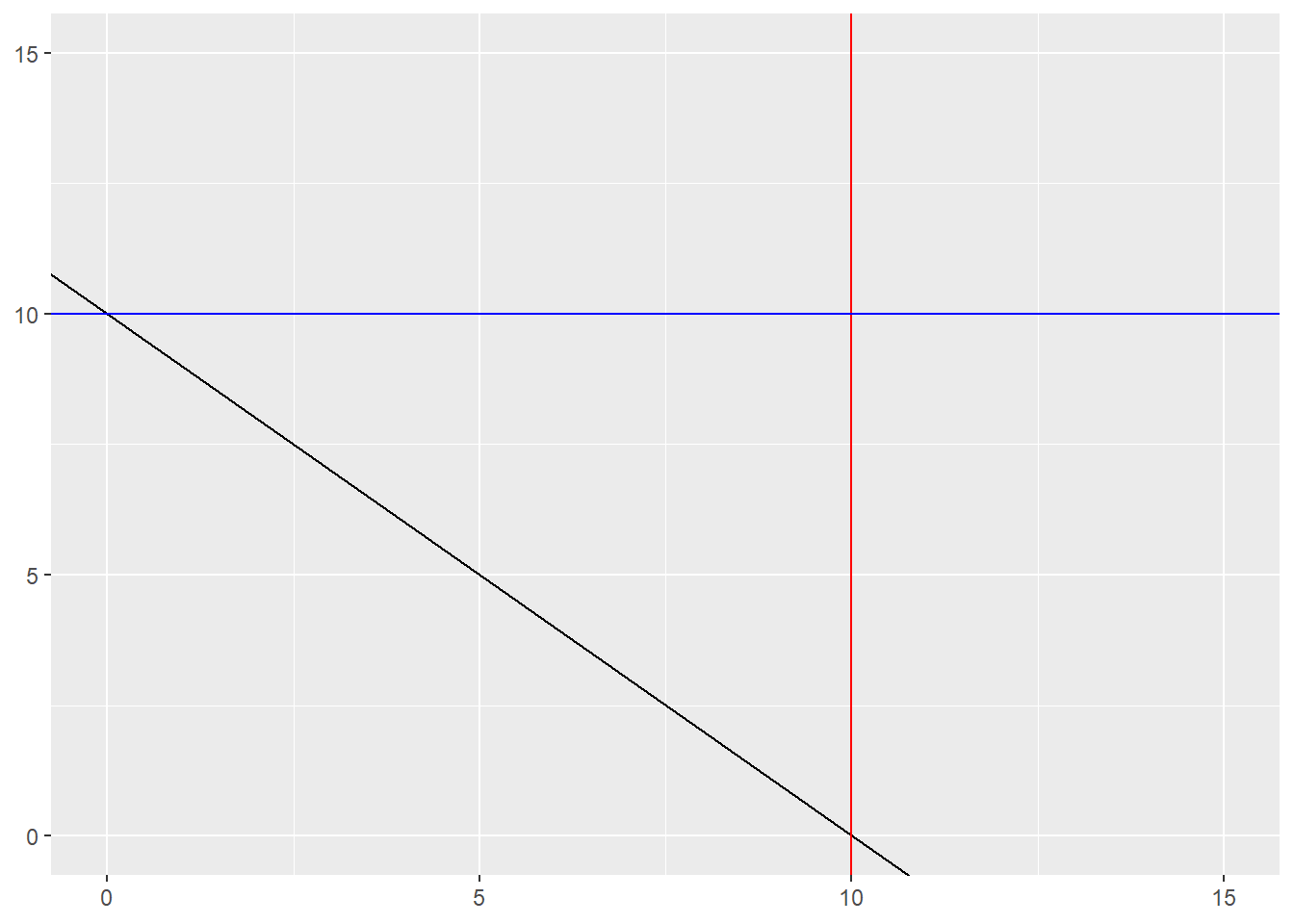
geom_barは、棒グラフを作成するための関数です。geom_barを引数なしで実行すると、ヒストグラムが描画されます。これは、geom_barの引数のうち、stat引数が"count"に設定されているためです。このstat引数は、グラフを記述する際に実施する統計的な処理を指定するための引数です。
geom_bar関数
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_bar() # ヒストグラムを表示(stat="count")
ggplot2には、ヒストグラムを描画するための専用の関数である、geom_histogramもあります。ヒストグラムを描くのが目的であれば、こちらのgeom_histogramの方が名前と目的が一致しており、使いやすいかと思います。
geom_histogram関数
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
ヒストグラムの棒の幅は、binsもしくはbinwidthのどちらかで指定します。binsで指定する場合には棒の数を、binwidthで指定する場合には棒の幅のサイズをそれぞれ数値で指定します。
geom_histogram:棒の幅を指定する
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_histogram(bins = 15) # 棒を15本にする(binsのデフォルト値は30)
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_histogram(binwidth = 0.5) # 棒の幅を0.5にする
geom_bar関数で1つの値に対して1つの棒グラフを描画する、要は通常の棒グラフを描画する場合には、stat="identity"を指定します。棒グラフを描画するときには、まずx軸とy軸の数値・ラベルを含むデータフレームを作成します。
tidyr、dplyrでデータフレームの前準備
# A tibble: 3 × 3
Species mSepal.Length sSepal.Length
<fct> <dbl> <dbl>
1 setosa 5.01 0.352
2 versicolor 5.94 0.516
3 virginica 6.59 0.636後は、aesでx軸に配置する値、y軸に配置する値を指定し、geom_bar関数内でstat="identity”を指定します。
stat="identity"を指定
d |>
ggplot(aes(x = Species, y = mSepal.Length)) +
geom_bar(stat = "identity")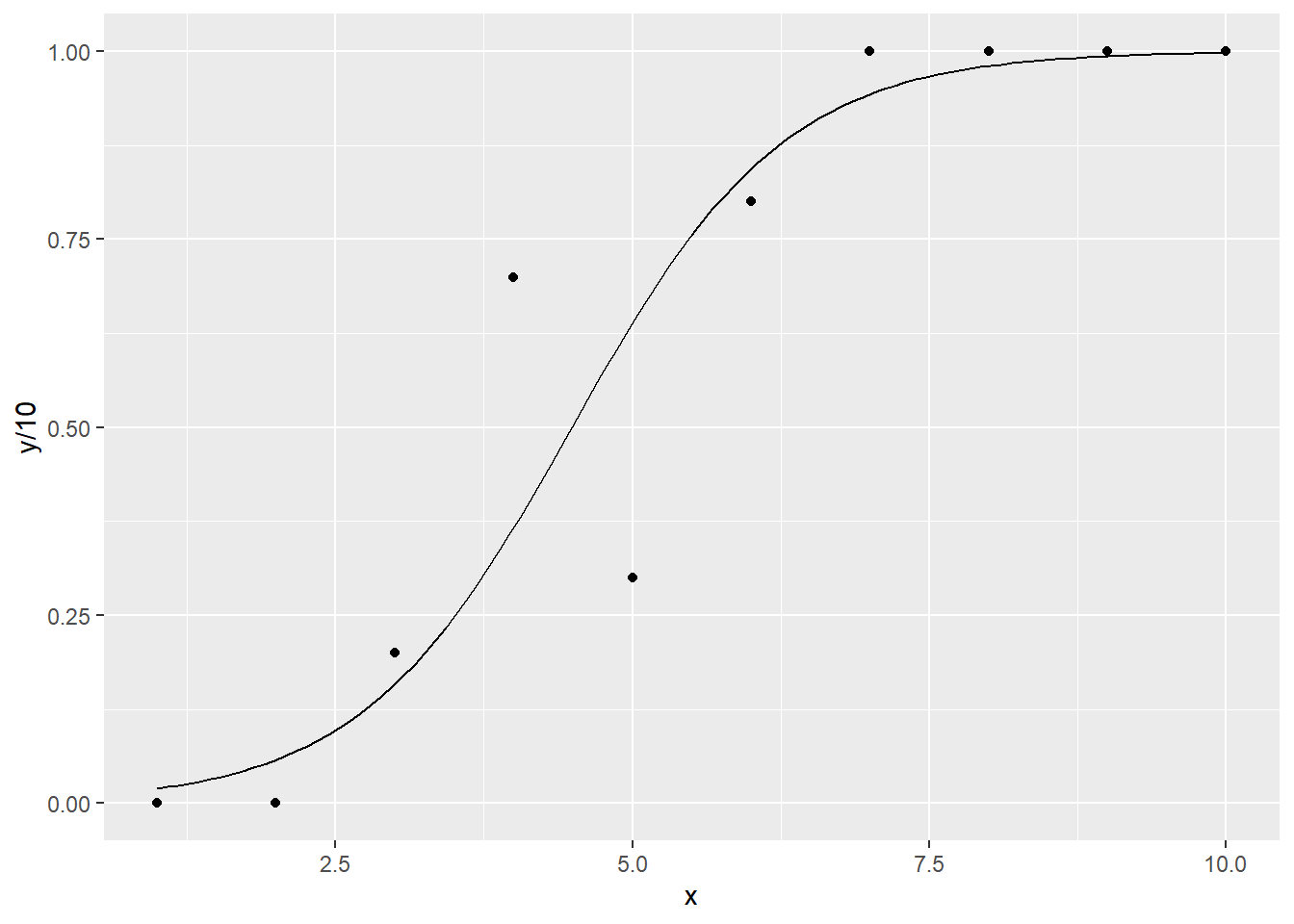
ggplot2には、直接棒グラフ(column plot)を描画するための専用の関数である、geom_colもあります。名前から直感的に理解できるなら、こちらを用いてもよいでしょう。
geom_col関数
d |>
ggplot(aes(x = Species, y = mSepal.Length)) +
geom_col()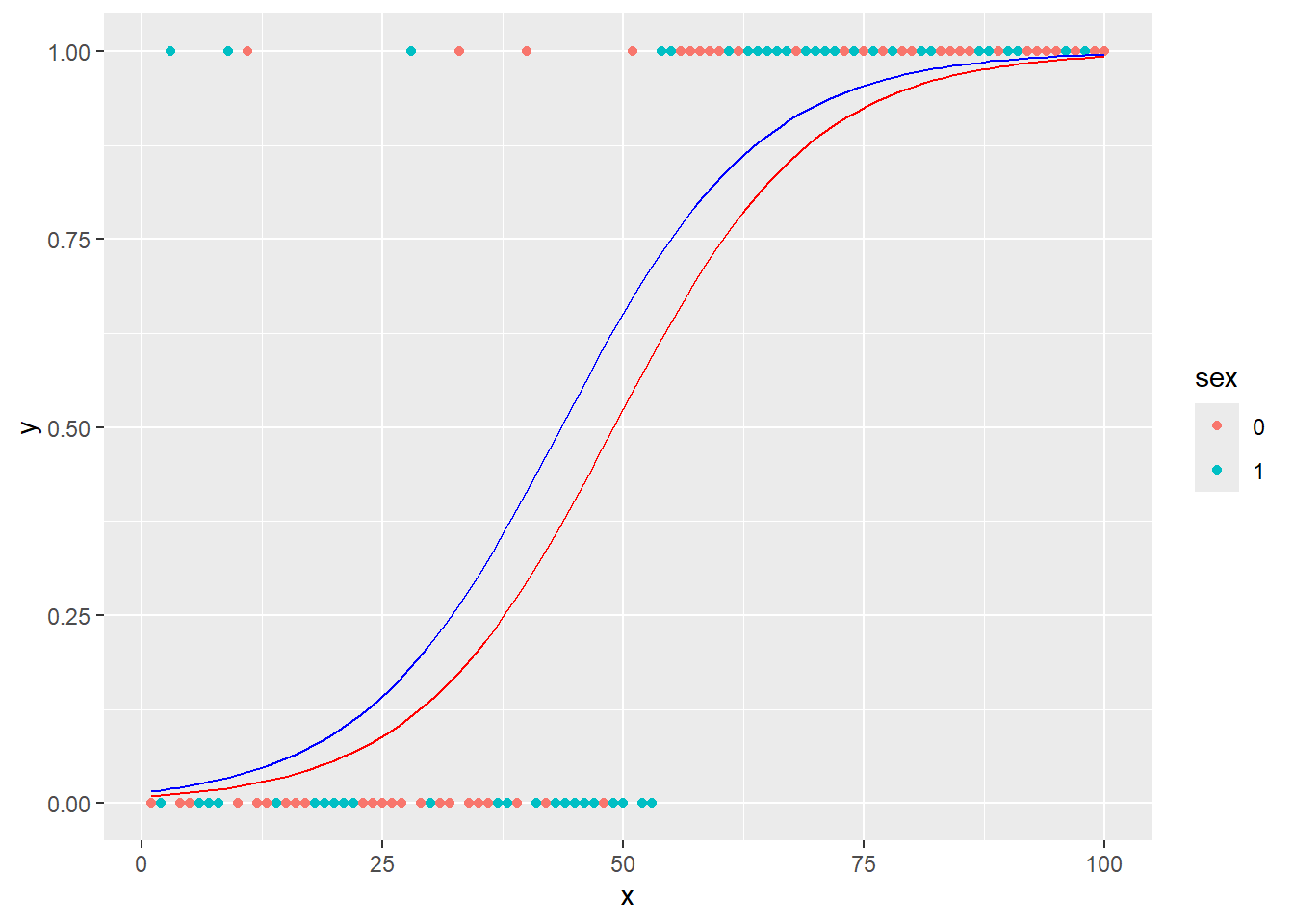
geom_bar関数は積み上げ式棒グラフを作成する際にも用いることができます。積み上げ式棒グラフを描画するときには、特に引数を指定する必要はありませんが、色分けをしないと積み上げたグラフを見分けることができません。積み上げ式グラフを記述するときには、colorとともに、棒の中身の色を設定するfillという引数で、色を指定するのが良いでしょう。
geom_barで積み上げ式グラフが記述されるのは、geom_barのposition引数のデフォルトがposition="stack"だからです。position="dodge"を指定すると、横並びにしたグラフが表示されます。
geom_bar関数で積み上げ式棒グラフ
d |>
ggplot(aes(x = "1", y = mSepal.Length, color = Species, fill = Species)) +
geom_bar(stat = "identity")
position="dodge"で横並びの棒グラフ
d |>
ggplot(aes(x = "1", y = mSepal.Length, color = Species, fill = Species)) +
geom_bar(stat = "identity", position = "dodge")
geom_dotplotはドットプロットという、ヒストグラムを点で描いたようなグラフを作成するときに用いる関数です。ドットの数がその値の範囲に存在する値の個数を示します。縦軸の単位がよくわからないものになりますので、通常はヒストグラムの方が使い勝手が良いでしょう。
geom_dotplot関数
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_dotplot()Bin width defaults to 1/30 of the range of the data. Pick better value with
`binwidth`.
geom_densityはヒストグラムと類似していますが、単に度数を返すのではなく、カーネル密度に変換した度数分布を示してくれる関数です。geom_densityでは、縦軸の値は確率密度となり、実際のデータが少ない部分にも実際の頻度より高めの確率密度が与えられるため、かなりデータが多い場合以外は正確性に欠くことになります。データが少ない場合にはヒストグラムの方が使い勝手が良いでしょう。
geom_density関数
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_density()
ヒストグラムを棒グラフではなく、線で表記するのがgeom_freqpolyです。こちらもヒストグラムほど使い勝手は良くないように思います。
geom_freqpoly関数
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_freqpoly()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
データの分布は単に散布図でも表示できます。ただし、geom_pointで単に表記すると、点が重なってしまって正しいデータ分布を示すことはできません。
geom_point関数で点が重なる場合
# geom_pointでは点が重なる
iris |>
ggplot(aes(x = Species, y = Sepal.Length, color = Species)) +
geom_point()
このような場合に、点の重なりを抑えるため、データの表示にランダムな幅を持たせるのがgeom_jitterです。xとyの方向にランダムに点をばらつかせることができます。xとyの両方が数値の場合にはx軸・y軸方向に幅を持たせることになります。ですので、x、yの両方が数値の場合には、点は正確な位置には配置されません。
geom_jitter関数で点をバラつかせる
iris |>
ggplot(aes(x = Species, y = Sepal.Length, color = Species)) +
geom_jitter()
geom_jitterでは、widthとheightの2つの引数でばらつかせる幅と高さを指定することができます。y方向の値に注目する場合であれば、height=0を指定することでy軸方向のばらつきを0にすることができるため、y軸方向には正確な値を表示させることができます。
geom_jitter:widthとheightを指定する
iris |>
ggplot(aes(x = Species, y = Sepal.Length, color = Species)) +
geom_jitter(width = 0.2, height = 0)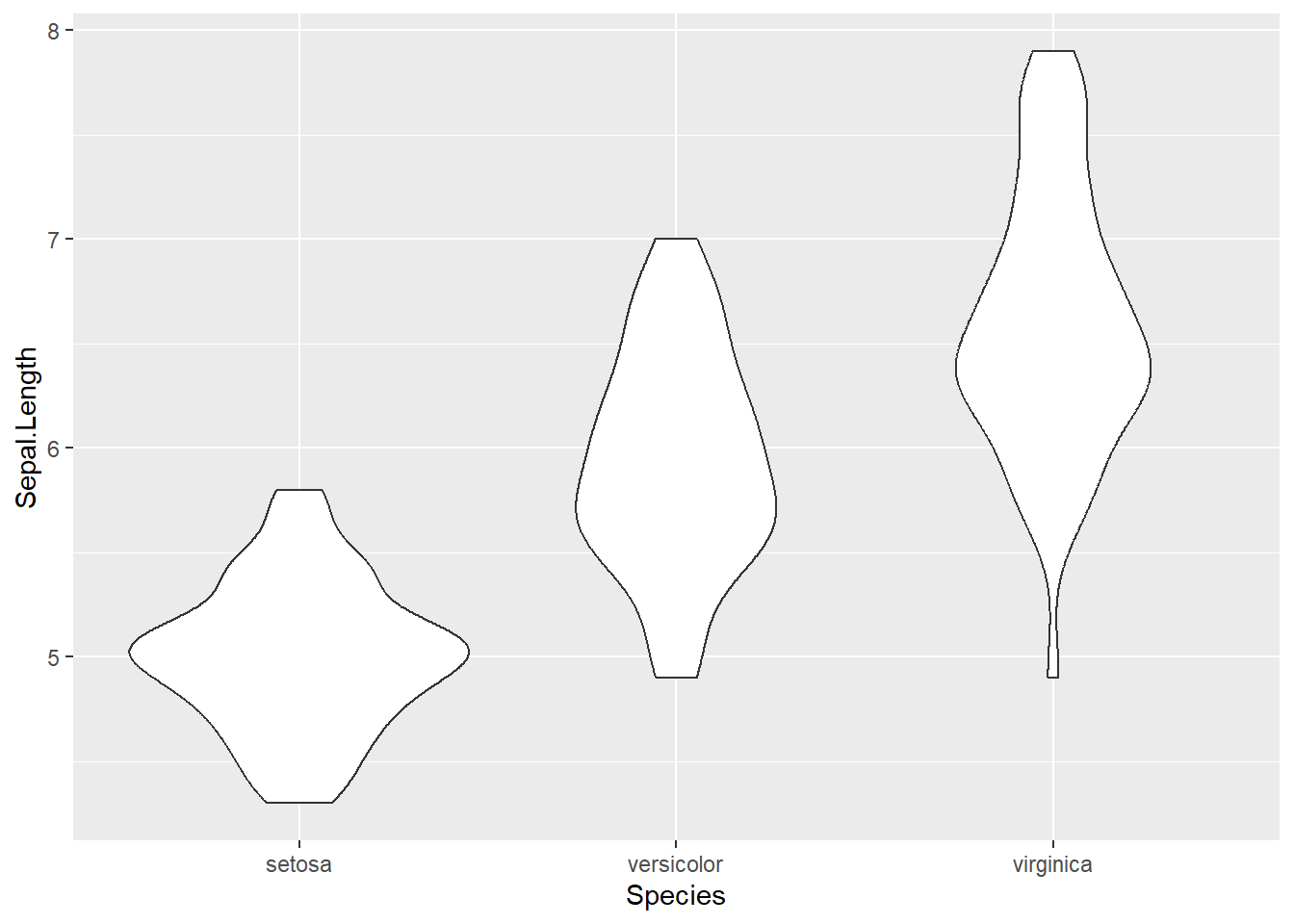
データが十分に多い場合には、箱ひげ図を用いてデータの分布を表示することもできます。ggplot2では、geom_boxplotを用いて箱ひげ図を描画することができます。geom_boxplotに数値ベクターを与えれば、自動的に箱ひげ図を描画してくれます。また、lower、upper、middle、 min、maxという引数を与えると、その引数に設定した数値に従い箱ひげ図を描画することもできます。
geom_boxplot関数
iris |>
ggplot(aes(x = Species, y = Sepal.Length)) +
geom_boxplot()
確率密度を90度回転させ、左右対称に配置した形のグラフのことを、バイオリンプロットと呼びます。ggplot2では、このバイオリンプロットをgeom_violinで描画することができます。描画の仕組みはgeom_densityによく似ています。
geom_violin関数
iris |>
ggplot(aes(x = Species, y = Sepal.Length)) +
geom_violin()
ggplot2で結果にエラーバーを付ける時には、geom_errorbarを用います。geom_errorbarでは、aesの引数として、yminとymax、もしくはxminとxmaxを設定します。yminとymaxはy軸方向の、xminとxmaxはx軸方向のエラーバーを設定する際に用います。また、geom_errorbarにはwidthという引数もあり、エラーバーの横棒のサイズを設定することができます。
geom_errorbarは通常、geom_pointで描画した点グラフや、geom_barで描画した棒グラフに重ねて表示することで用います。重ね書きする際には、ggplotに+でgeom_pointをつないだ後に、さらに+でgeom_errorbarをつなぐことになります。このように+でつなぐと、ggplot2ではgeom_pointの点グラフの上に、geom_errorbarが重ね描きされます。
エラーバーを表示する
p <- d |>
ggplot(
aes(
x = Species,
y = mSepal.Length,
ymax = mSepal.Length + sSepal.Length,
ymin = mSepal.Length - sSepal.Length))
p + geom_point() + geom_errorbar()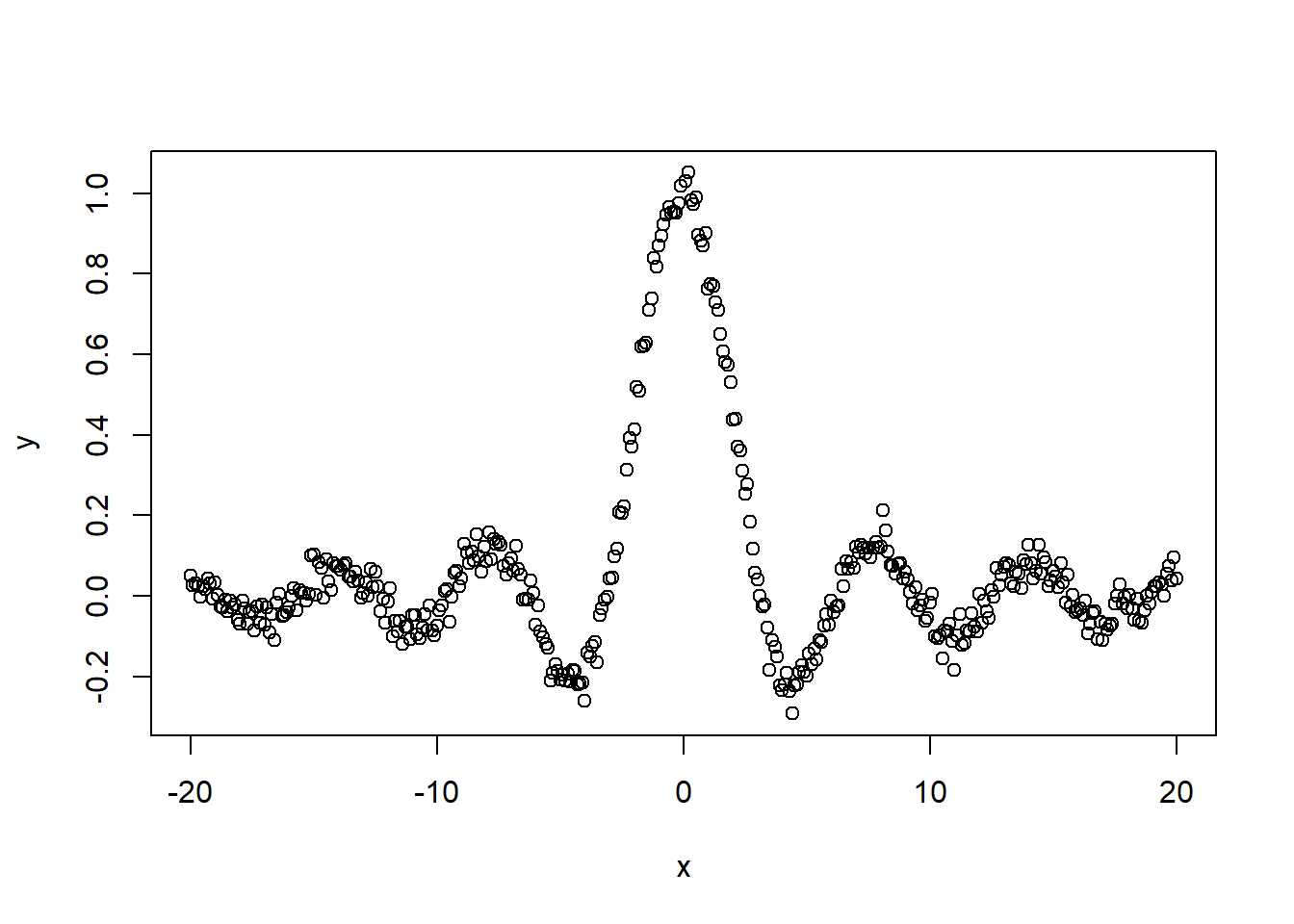
geom_errorbarではエラーバーに横線が付き、よく見るエラーバーの形となります。ただし、この横線は必ずしも必要なものではありません。横線のないエラーバーを付けたいときには、geom_linerangeを用います。
geom_linerange関数でエラーバーをつける
p + geom_point() + geom_linerange()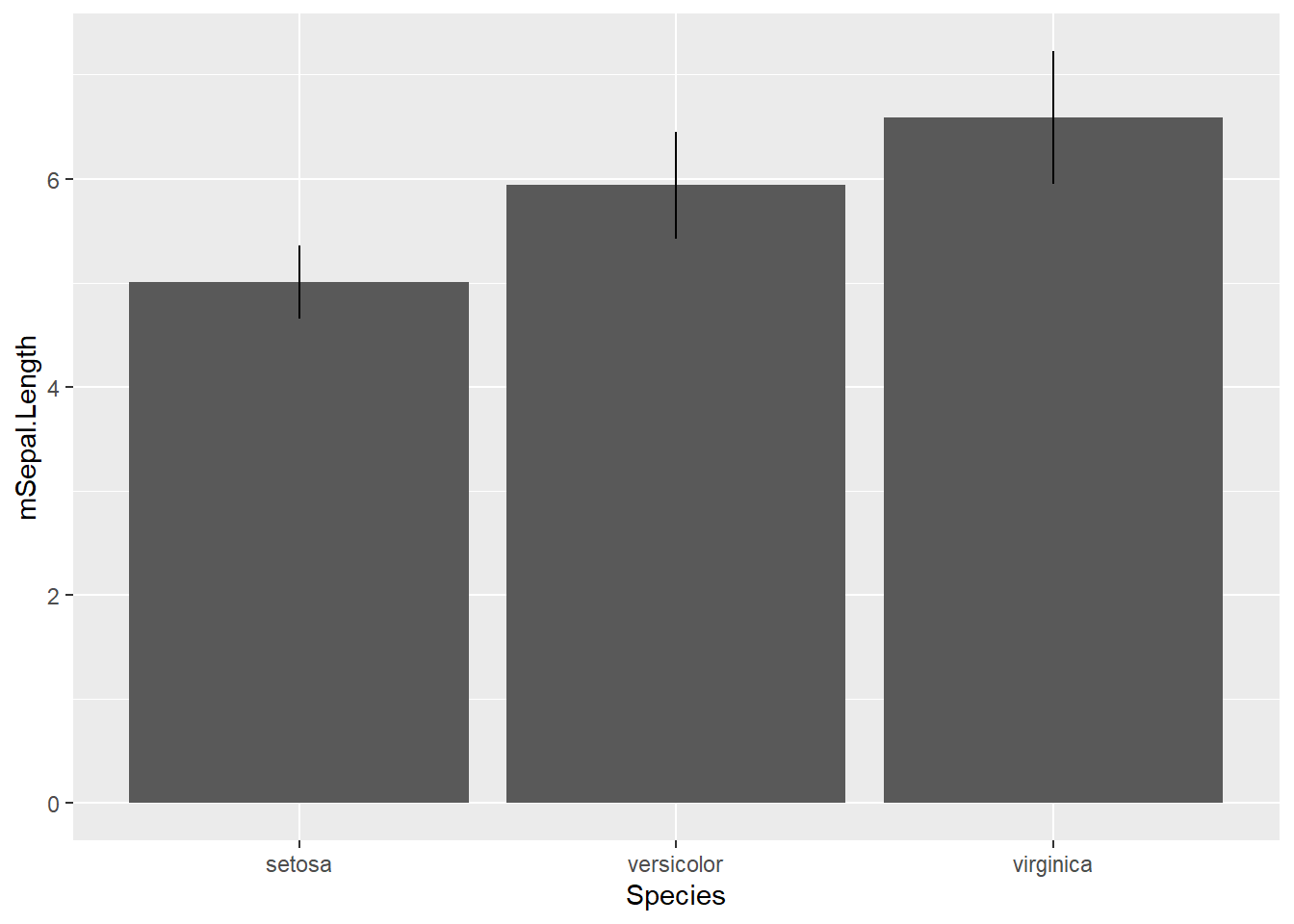
geom_errorbarやgeom_linerangeは点が備わっておらず、別途geom_pointで点を書く必要があります。この点と線を同時に描画するのが、geom_pointrangeです。geom_pointrangeを用いると、geom_pointを別途描画しなくても、点とエラーバーが付いたグラフを作成することができます。このような、点と線のみで記述するグラフのことをフォレストプロットと呼び、メタ解析などでよく用いられています。
geom_pointrange関数でフォレストプロット
p + geom_pointrange()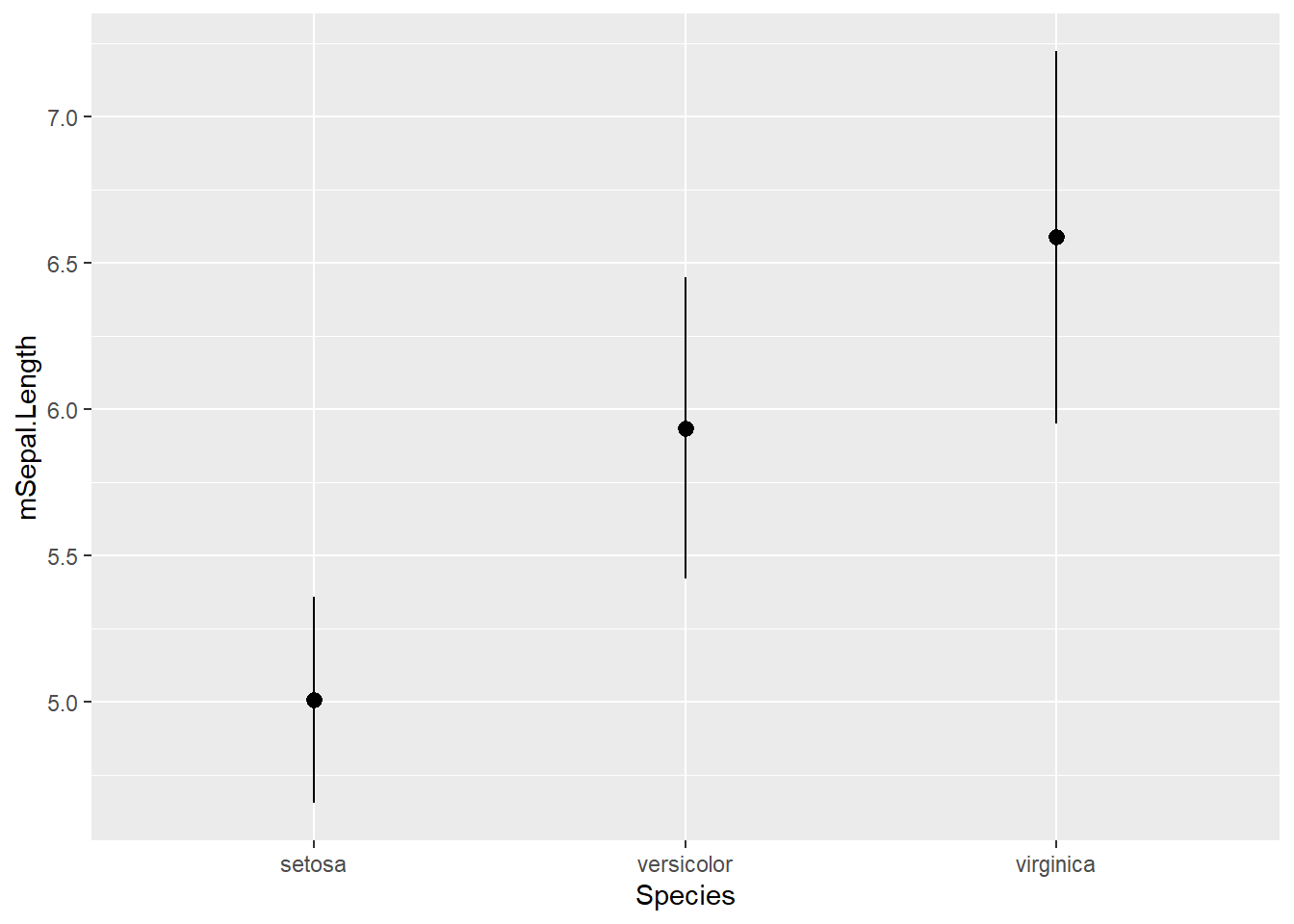
棒グラフにもエラーバーを付けることはできます。棒グラフにエラーバーを付ける時には、stat="identity"で指定したgeom_barに、+でgeom_errorbarやgeom_linerangeをつなげます。
棒グラフにエラーバーをつける
p +
geom_bar(stat = "identity") +
geom_linerange()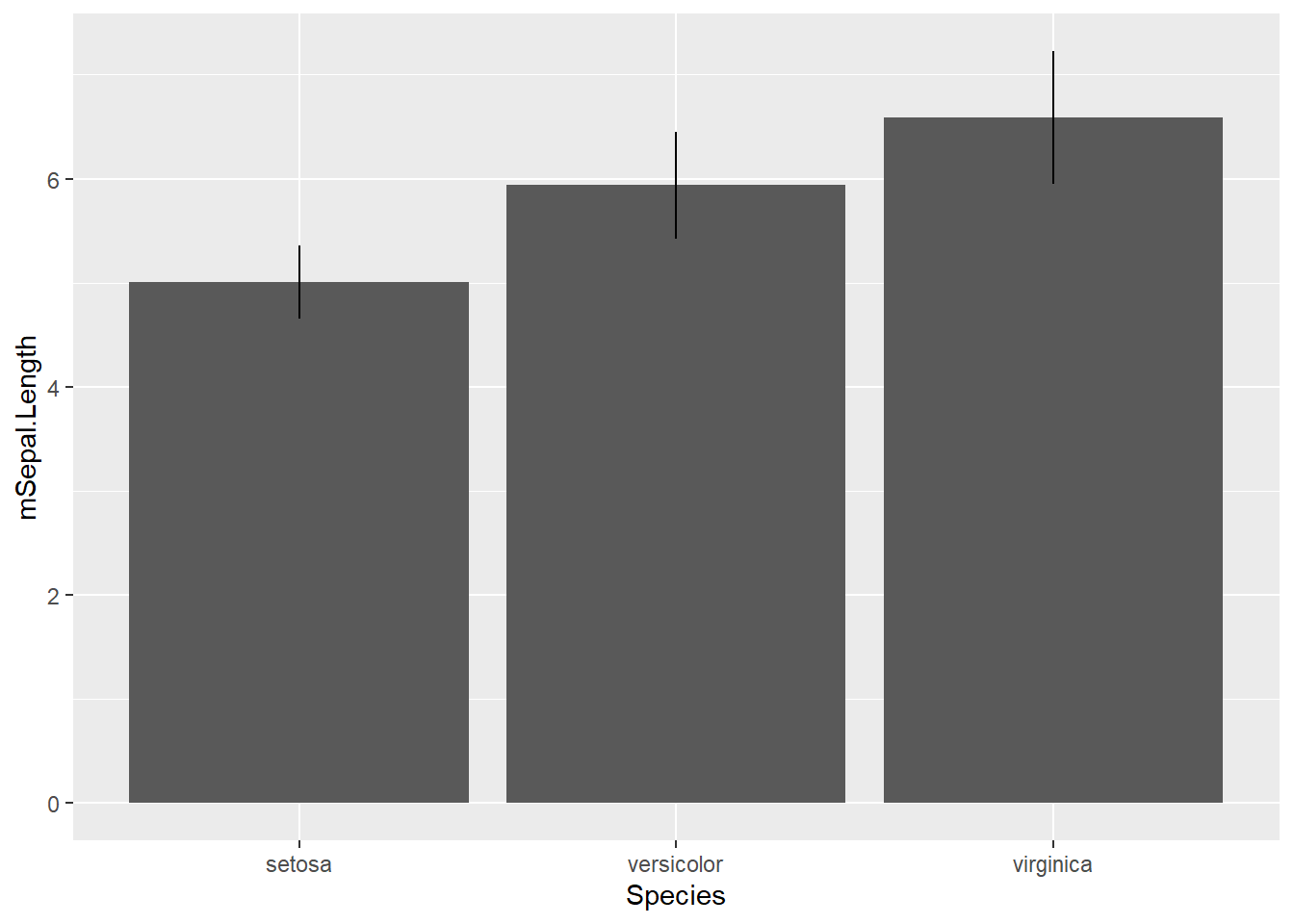
複数のタイプのデータに対して棒グラフを横に並べて描画し、その棒グラフにエラーバーを付けたい、という場合もあります。geom_barのデフォルトはposition="stack"ですので、複数のタイプのデータを表示するときには積み上げ式の棒グラフが描画されます。横に棒グラフを並べる場合には、position="dodge"を指定する必要があります。
では、具体的にposition="dodge"の棒グラフにエラーバーを付与する手順を見ていきましょう。まずは、データフレームでデータを準備する必要があります。dplyrやtidyrを用いることで、データの準備を比較的簡単に行うことができます。
下の例では、irisのSpecies以外のデータ(Sepal.Length、Sepal.Width、Petal.Length、Petal.Width)をpivot_longerを用いて縦持ちに変換し、データ名とSpeciesでグループ化した後、それぞれの平均値と標準偏差を求めています。棒グラフやフォレストプロットの描画の準備では、pivot_longer、group_by、summariseを用いることが多く、データの要約を求める際にも便利な組み合わせです。
具体的にどのように変換しているのか分かりにくければ、pivot_longerまでと、それ以降を切り離して実行してみると良いでしょう。
要約したデータの準備
# A tibble: 12 × 4
# Groups: name [4]
name Species mvalue svalue
<chr> <fct> <dbl> <dbl>
1 Petal.Length setosa 1.46 0.174
2 Petal.Length versicolor 4.26 0.470
3 Petal.Length virginica 5.55 0.552
4 Petal.Width setosa 0.246 0.105
5 Petal.Width versicolor 1.33 0.198
6 Petal.Width virginica 2.03 0.275
7 Sepal.Length setosa 5.01 0.352
8 Sepal.Length versicolor 5.94 0.516
9 Sepal.Length virginica 6.59 0.636
10 Sepal.Width setosa 3.43 0.379
11 Sepal.Width versicolor 2.77 0.314
12 Sepal.Width virginica 2.97 0.322上で作成したデータフレームを用いて、ggplot2でグラフを描画します。まずはggplot関数でaesを設定していきます。x軸にSpecies、y軸に平均値とエラーバーの要素に平均値±標準偏差(ymin、ymax)、棒の枠の色(color)と棒の中身の色(fill)にデータ名を設定しておきます。
ggplot関数の準備
p1 <- d1 |>
ggplot(
aes(
x = Species,
y =mvalue,
ymax = mvalue + svalue,
ymin = mvalue - svalue,
color = name,
fill = name
)
)このggplot関数に、geom_barとgeom_linerangeを+でつなげると、下の図のように、積み上げ式棒グラフの下の方にエラーバーが重なって表示される、変なグラフが作成されます。これは、geom_barの引数の設定がposition="stack"であるため積み上げ式棒グラフとなる一方で、geom_linerangeなどのエラーバーを指定するgeom関数には積み上げ式の設定がないためです。
positionを指定しない場合
# positionを指定しないと、積み上げ式棒グラフになる
p1 +
geom_bar(stat = "identity") +
geom_linerange()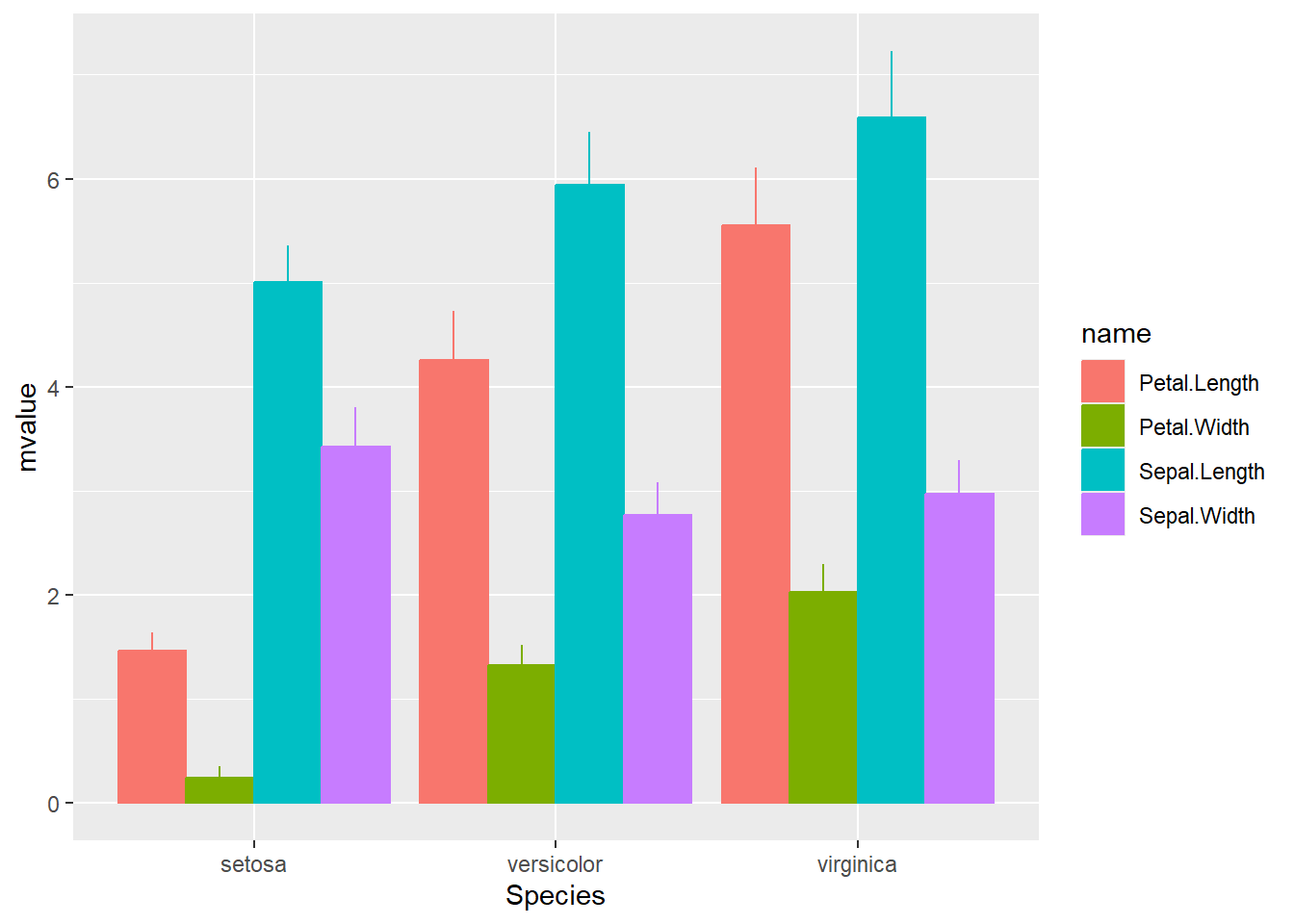
positionに"dodge"を指定すると、棒グラフは積み上げ式ではなく、横に並べる形となります。このとき、エラーバーは棒グラフの真ん中に配置されてしまい、どの棒グラフのエラーバーなのかわからなくなります。これは、geom_linerangeのpositionの設定が正しく行われていないためです。
positionをdodgeに指定した場合
p1 +
geom_bar(stat = "identity", position="dodge") +
geom_linerange()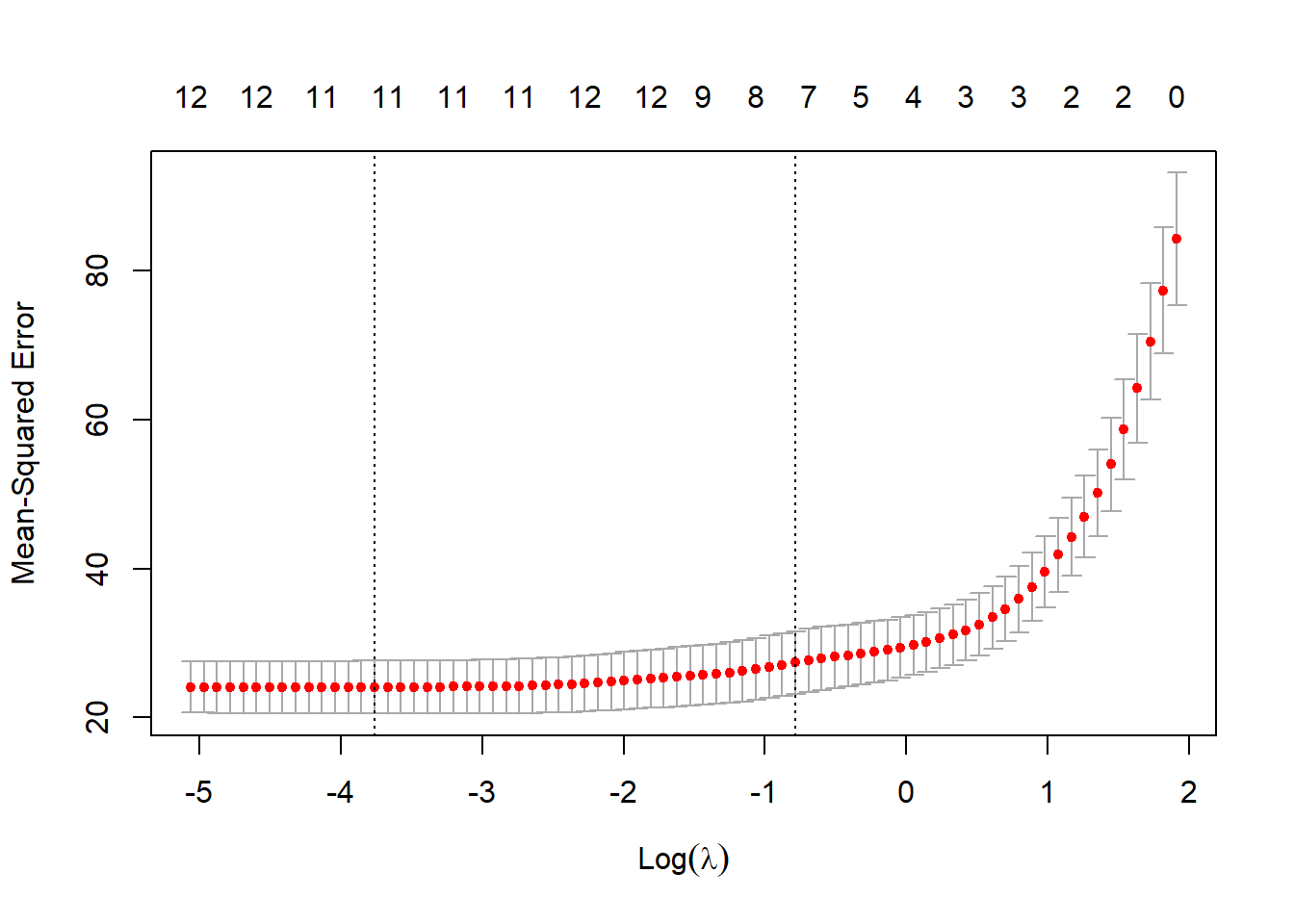
geom_linerangeを含む、エラーバーを描画するためのgeom関数のpositionの指定には、position_dodge関数を用います。position=position_dodge(width=0.9)という形でgeom_linerangeのpositionを指定すると、エラーバーが正しい位置(棒グラフの真ん中)に配置されます。やや複雑ですし、width=0.9の意味はよくわからないのですが、この方法はggplot2のReferenceにも記載されています。
position_dodge(width=0.9)を指定
p1 +
geom_bar(stat = "identity", position = "dodge") +
geom_linerange(position = position_dodge(width = 0.9))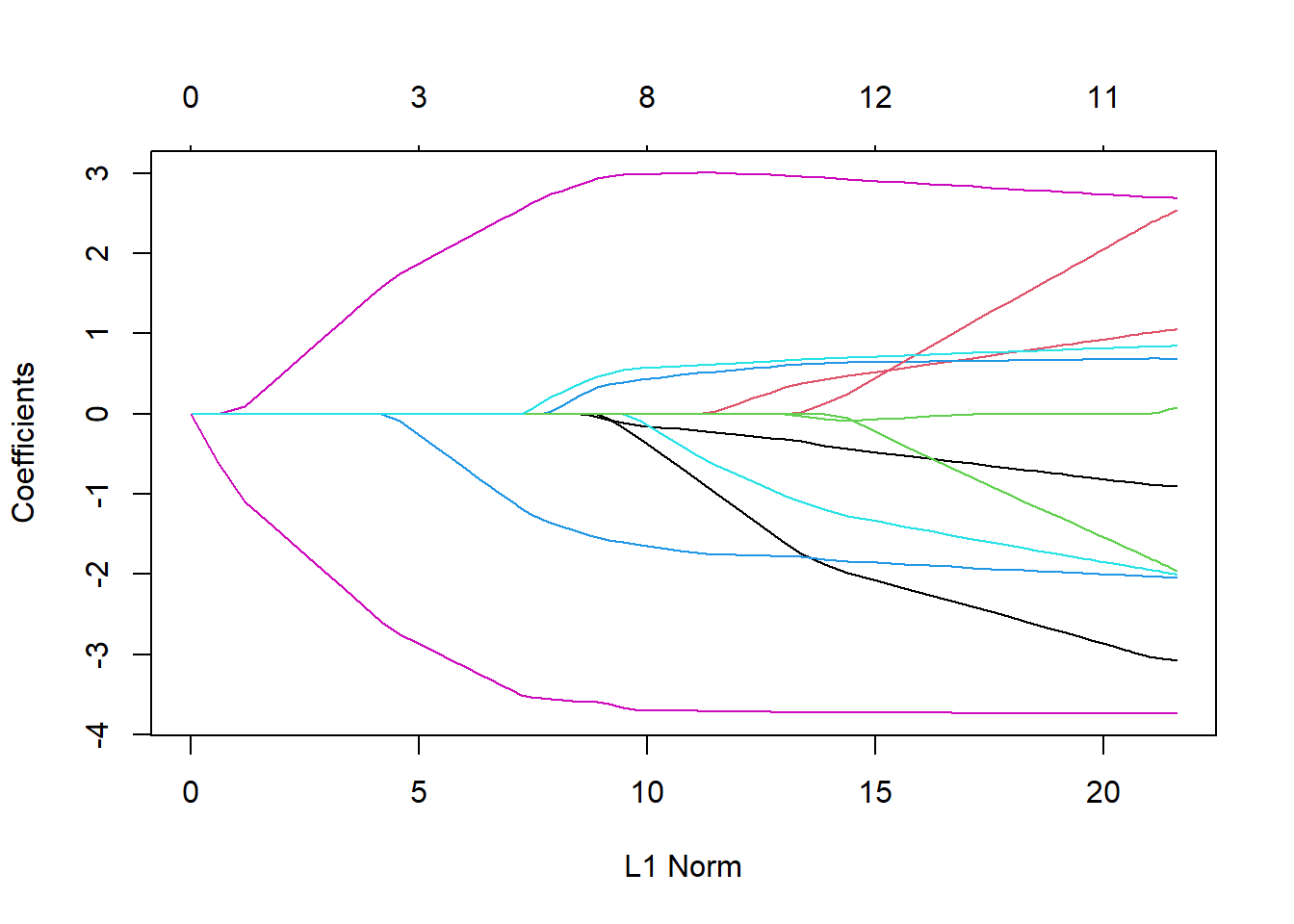
上記のように、棒グラフとエラーバーの色を同じにすると、エラーバーの下側が見えなくなります。このようなグラフ(ダイナマイトっぽい形をしているので、ダイナマイトプロットと呼ばれます)では、エラーバーで示したい範囲が不明瞭となるため、データ表示の方法としては良くないとされています。点と線で表すフォレストプロット(geom_pointrange)を用いたほうが、棒グラフとエラーバーを用いるより、データの表示方法としては優れています。
geom_bin2dはx軸、y軸に値を設定し、x・yそれぞれの値のデータを度数分布に変換した上で、度数を2次元グラフ上に色で示すものです。2次元で表示するヒストグラムにあたります。ただし、下の図のようにデータが多く、分布が薄く広がっている場合には度数の差が分かりにくくなってしまいます。
geom_bin2dで二次元ヒストグラム
diamonds |>
ggplot(aes(x=carat, y=price)) +
geom_bin2d()`stat_bin2d()` using `bins = 30`. Pick better value `binwidth`.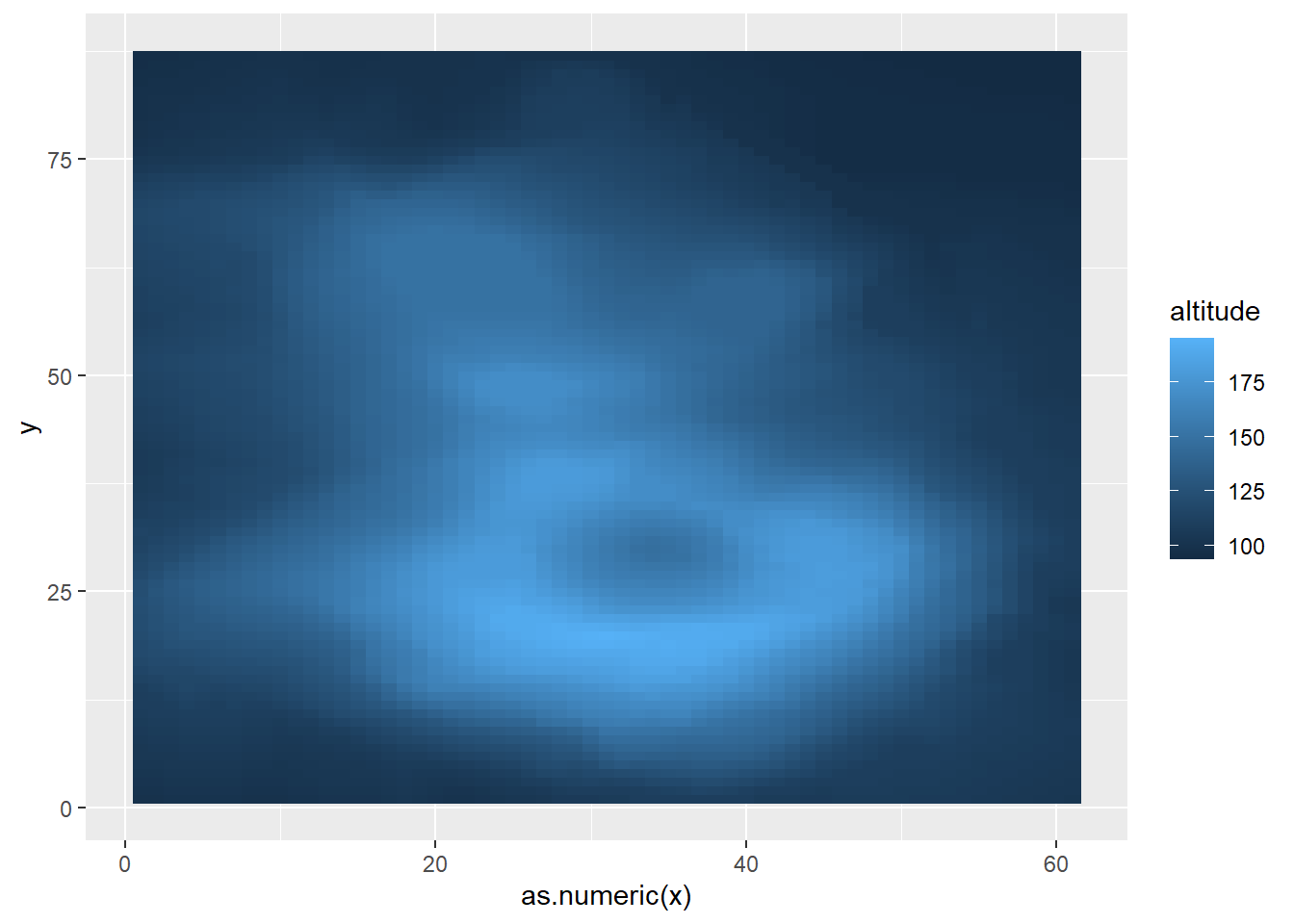
このようなデータで度数を調べる場合には、geom_pointと透明化を指定する引数であるalphaを用いるのが良いでしょう。alphaを小さい値に指定すると、度数の多いところは濃い色で、度数が小さいところは薄い色で表示されます。下のグラフは上のgeom_bin2dと同じものを表現していますが、こちらの方がデータの分布としては理解しやすいことがわかるかと思います。
alphaで半透明化
diamonds |>
ggplot(aes(x=carat, y=price)) +
geom_point(alpha=0.004)
棒グラフと同様に、geom_bin2dもstat="identity"と指定することで、数値をそのまま色とするグラフを作成することができます。下の例では、volcanoデータセット(マウンガファウの南北・東西の位置と標高のデータ)を変形し、geom_bin2dで描画したものです。このようにstat="identity"を用いれば、geom_bin2dを用いてヒートマップを作成することもできます。
geom_bin2dでヒートマップを描画
volcano |>
as.data.frame() |>
cbind(y = 1:nrow(volcano)) |>
pivot_longer(1:ncol(volcano), values_to = "altitude", names_to = "x") |>
mutate(x = as.numeric(str_remove_all(x, "V"))) |>
ggplot(aes(x = as.numeric(x), y = y, color = altitude, fill = altitude)) +
geom_bin2d(stat = "identity")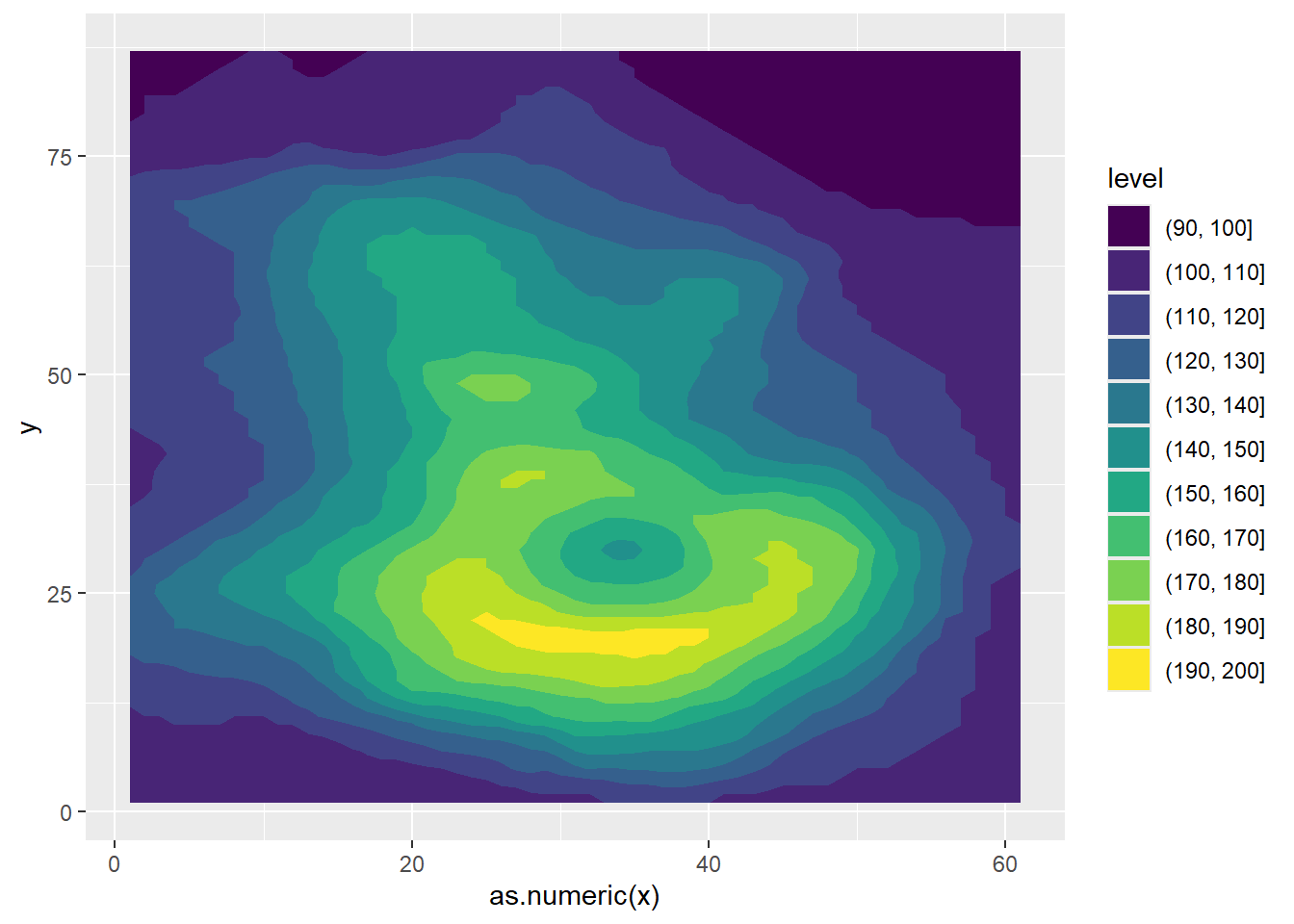
geom_contourはRのcontour関数と同じく、標高線で示された図を表記するのに用いる関数です。geom_bin2dとは異なり、aesには3つの値(x、y、z)を指定する必要があります。
geom_contourで等高線グラフを作成
volcano |>
as.data.frame() |>
cbind(y = 1:nrow(volcano)) |>
pivot_longer(1:ncol(volcano), values_to = "altitude", names_to = "x") |>
mutate(x = as.numeric(str_remove_all(x, "V"))) |>
ggplot(aes(x = as.numeric(x), y = y, z = altitude)) +
geom_contour()
Rデフォルトのfilled.contour関数と同様に、等高線に色を合わせて表示するようなグラフを作成する場合には、geom_contour_filledを用います。geom_contour_filledを用いることで、zの値に従い色分けされたグラフを描画することができます。
geom_contour_filledで色付き等高線グラフを作成
volcano |>
as.data.frame() |>
cbind(y = 1:nrow(volcano)) |>
pivot_longer(1:ncol(volcano), values_to = "altitude", names_to = "x") |>
mutate(x = as.numeric(str_remove_all(x, "V"))) |>
ggplot(aes(x = as.numeric(x), y = y, z = altitude)) +
geom_contour_filled()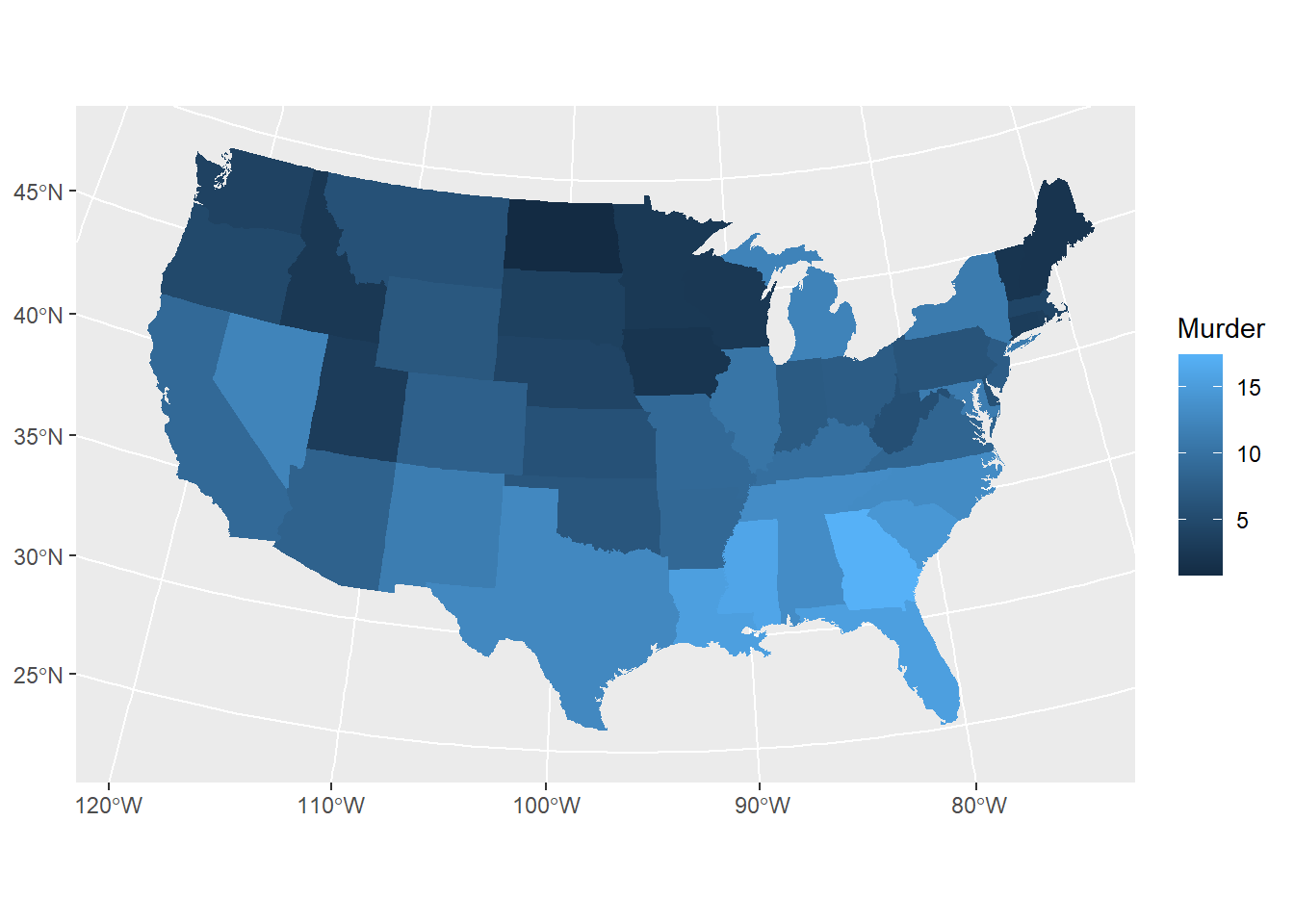
geom_mapは地図を表示するための関数です。地図を表記するためには、地図データ、つまり緯度、経度とその場所のIDを記録したもの、を準備する必要があります。
Rで地図データを用いる場合には、mapsパッケージ(Richard A. Becker et al. 2023)を利用するのが比較的簡単です。mapsパッケージには世界地図、アメリカの州の地図、フランスやイタリア、ニュージーランドなどの地図が登録されています。mapsパッケージの地図をggplot2で用いる場合には、ggplot2で使用できるデータフレームに変換してくれるmapsパッケージの関数である、map_dataを用います。
mapパッケージで地図データの読み込み
long lat group order region subregion
1 -87.46201 30.38968 1 1 alabama <NA>
2 -87.48493 30.37249 1 2 alabama <NA>
3 -87.52503 30.37249 1 3 alabama <NA>
4 -87.53076 30.33239 1 4 alabama <NA>
5 -87.57087 30.32665 1 5 alabama <NA>
6 -87.58806 30.32665 1 6 alabama <NA>ggplot2では、map_dataで変換したデータフレームをggplot関数の引数にするのではなく、map_dataでregionに指定されているラベル(地域)を含むデータフレームを用います。
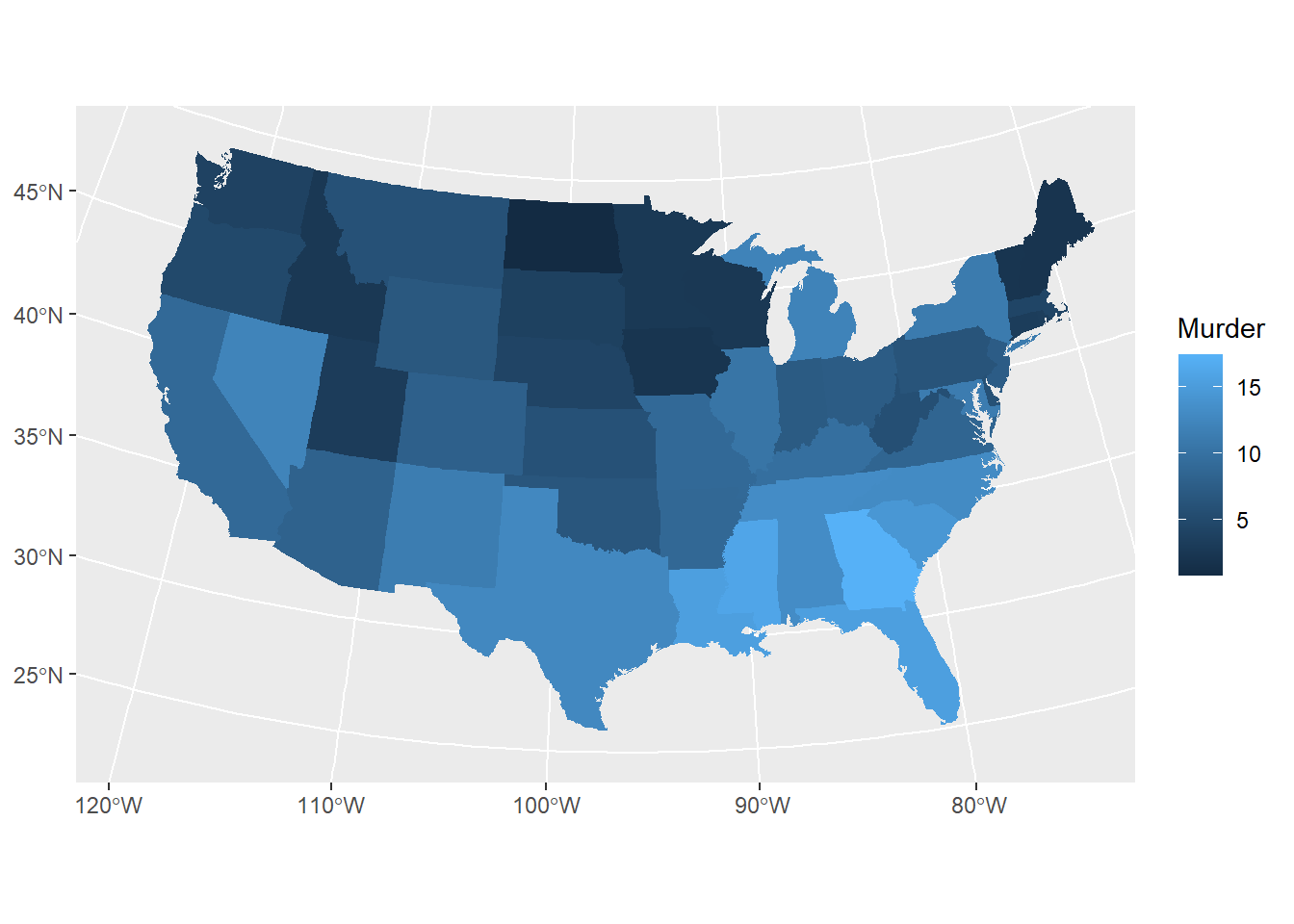
USArrestsはアメリカの州別の10万人あたりの犯罪件数を記録したデータフレームです。このデータフレームの行名が州名になっているので、これをデータフレームの列に追加し、stateと表記を合わせるために小文字に変換します。
aesでは、map_id=stateとし、地図IDを指定します。さらに、fillにはUSArrestsの列名であるMurder(殺人の件数)を指定します。この形で指定することで、Murderの値が色で示されることになります。
geom_mapでは、さらにmapという引数に、map_dataの返り値(state)を指定する必要があります。こうすることで、geom_mapはstateを基準に地図を描画し、地図の色にfillで指定したMurderの値を適用します。
上記のようにすれば、地図を表記することはできますが、やや煩雑です。近年のRでは、地図データを扱う際には、地図データ取り扱いの専用クラスであるsf(simple features)を用いるのが一般的になっています。このsfを用いれば、グラフをより簡単に作成することができます。
sfクラスは、sfパッケージ(Pebesma and Bivand 2023; Pebesma 2018)で定義されているクラスです。sfを使用する際には、まずsfパッケージを読み込みます。
sfパッケージをインストールすると、sfパッケージ内にある地図データにアクセスできます。下の例では、sfパッケージのフォルダ内にある地図データ(North Carolinaのsfデータ)を読み込んでいます。
sfパッケージのデータを読み込み
# system.fileはパッケージからフルパスを読み込む関数
fname <- system.file("shape/nc.shp", package="sf")
nc <- st_read(fname) # North CarolinaのsfデータReading layer `nc' from data source
`C:\Program Files\R\R-4.6.0\library\sf\shape\nc.shp' using driver `ESRI Shapefile'
Simple feature collection with 100 features and 14 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27sfは基本的にデータフレームで、geometryという列を持っています。この列は、sfcクラスのデータです。sfcクラスはその行に対応する緯度・経度のセットを専用の表記法で示したものとなります。sfを用いる場合には、このgeometryが地図データを表現する列になります。
sfのデータ
class(nc) # sfはデータフレームの一種[1] "sf" "data.frame"nc # geometryという列に地図データが格納されているSimple feature collection with 100 features and 14 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27
First 10 features:
AREA PERIMETER CNTY_ CNTY_ID NAME FIPS FIPSNO CRESS_ID BIR74 SID74
1 0.114 1.442 1825 1825 Ashe 37009 37009 5 1091 1
2 0.061 1.231 1827 1827 Alleghany 37005 37005 3 487 0
3 0.143 1.630 1828 1828 Surry 37171 37171 86 3188 5
4 0.070 2.968 1831 1831 Currituck 37053 37053 27 508 1
5 0.153 2.206 1832 1832 Northampton 37131 37131 66 1421 9
6 0.097 1.670 1833 1833 Hertford 37091 37091 46 1452 7
7 0.062 1.547 1834 1834 Camden 37029 37029 15 286 0
8 0.091 1.284 1835 1835 Gates 37073 37073 37 420 0
9 0.118 1.421 1836 1836 Warren 37185 37185 93 968 4
10 0.124 1.428 1837 1837 Stokes 37169 37169 85 1612 1
NWBIR74 BIR79 SID79 NWBIR79 geometry
1 10 1364 0 19 MULTIPOLYGON (((-81.47276 3...
2 10 542 3 12 MULTIPOLYGON (((-81.23989 3...
3 208 3616 6 260 MULTIPOLYGON (((-80.45634 3...
4 123 830 2 145 MULTIPOLYGON (((-76.00897 3...
5 1066 1606 3 1197 MULTIPOLYGON (((-77.21767 3...
6 954 1838 5 1237 MULTIPOLYGON (((-76.74506 3...
7 115 350 2 139 MULTIPOLYGON (((-76.00897 3...
8 254 594 2 371 MULTIPOLYGON (((-76.56251 3...
9 748 1190 2 844 MULTIPOLYGON (((-78.30876 3...
10 160 2038 5 176 MULTIPOLYGON (((-80.02567 3...ggplot2でsfを用いてグラフを描画する場合には、geom_sf関数を用います。geom_sf関数を用いてグラフを作成する場合には、ggplot関数の引数となるデータフレームにsf、aesにsfに含まれる列を指定します。sfを用いれば、このようなシンプルな表記法でgeom_mapよりも簡単に地図を表記することができます。
geom_sf関数でsfデータを描画
# sfを用いたグラフの表記
nc |>
ggplot() +
geom_sf(aes(fill = AREA))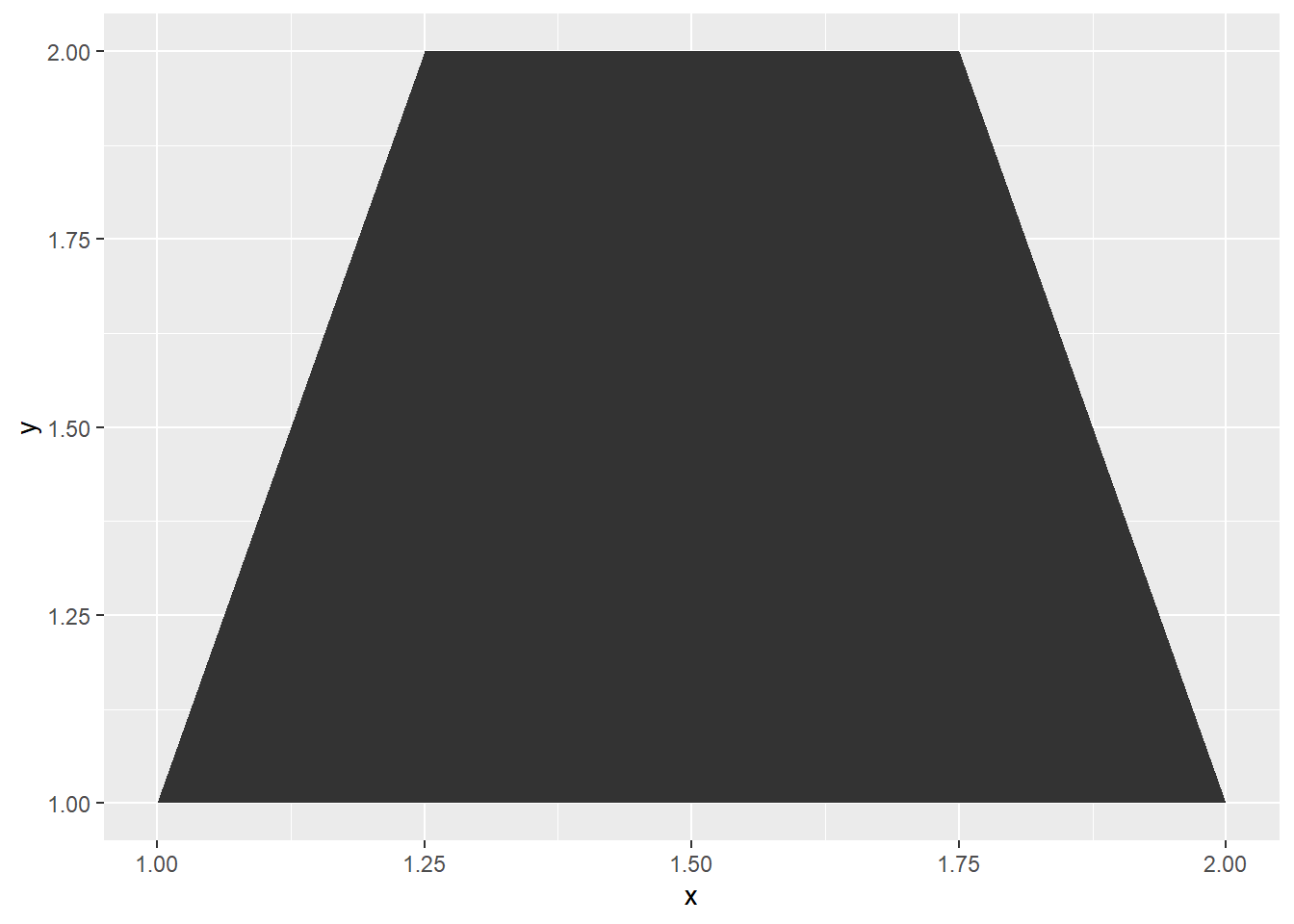
sfは2018年に発表された、比較的新しいパッケージです。sfが出てくるまでは、Rで地図データを取り扱う方法は様々で、統一されているという感はありませんでしたが、今後はsfがデフォルトの地図データ取り扱い方法になっていくのではないかと思います。地図データの取扱いに関してはオンラインの英語の教科書(Geocomputation with R)があり、日本語訳(Geocomputation with R (日本語版))も公開されています。
地図表示のためのパッケージにはggplot2だけでなく、Leaflet for RというJavascriptの地図ライブラリをRで利用できるようにしたものや、ggplot2風の記法で色々なデザインのグラフを描画できるtmapなどもあります。sf、leaflet、tmapについては45章で説明します。
geom_polygonは多角形を描画するための関数です。データフレームには、多角形の各頂点に当たるxとyの座標を指定します。
geom_polygon関数
# 頂点のx、y座標を指定する
d2 <- data.frame(x = c(1, 1.25, 1.75, 2), y = c(1, 2, 2, 1))
d2 x y
1 1.00 1
2 1.25 2
3 1.75 2
4 2.00 1aesで頂点のx、y座標を指定すると、多角形を描画することができます。低レベルグラフィック関数であるpolygon関数と類似した描画の方法になっています。
geom_polygonで多角形を描画
d2 |>
ggplot(aes(x = x, y = y)) +
geom_polygon()
上で説明したように、ggplot2で色を指定するときには、aes中でcolor、fillの引数を指定します。color、fillは数値または因子を指定することができ、点や面を数値・因子に対応した色で表示することができます。
geom_pointなどの点を描画する場合では、colorのみを指定します。
colorに因子を指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point()
color引数に数値を指定すると、数値に従い色の濃度が変わります。
colorに数値を指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Petal.Length)) +
geom_point()
geom_barでは、colorだけを指定すると、棒グラフの枠だけに色がつきます。
geom_barでcolorだけを指定した場合
d1 |>
ggplot(aes(x = Species, y = mvalue, color = name)) +
geom_bar(stat = "identity", position = "dodge")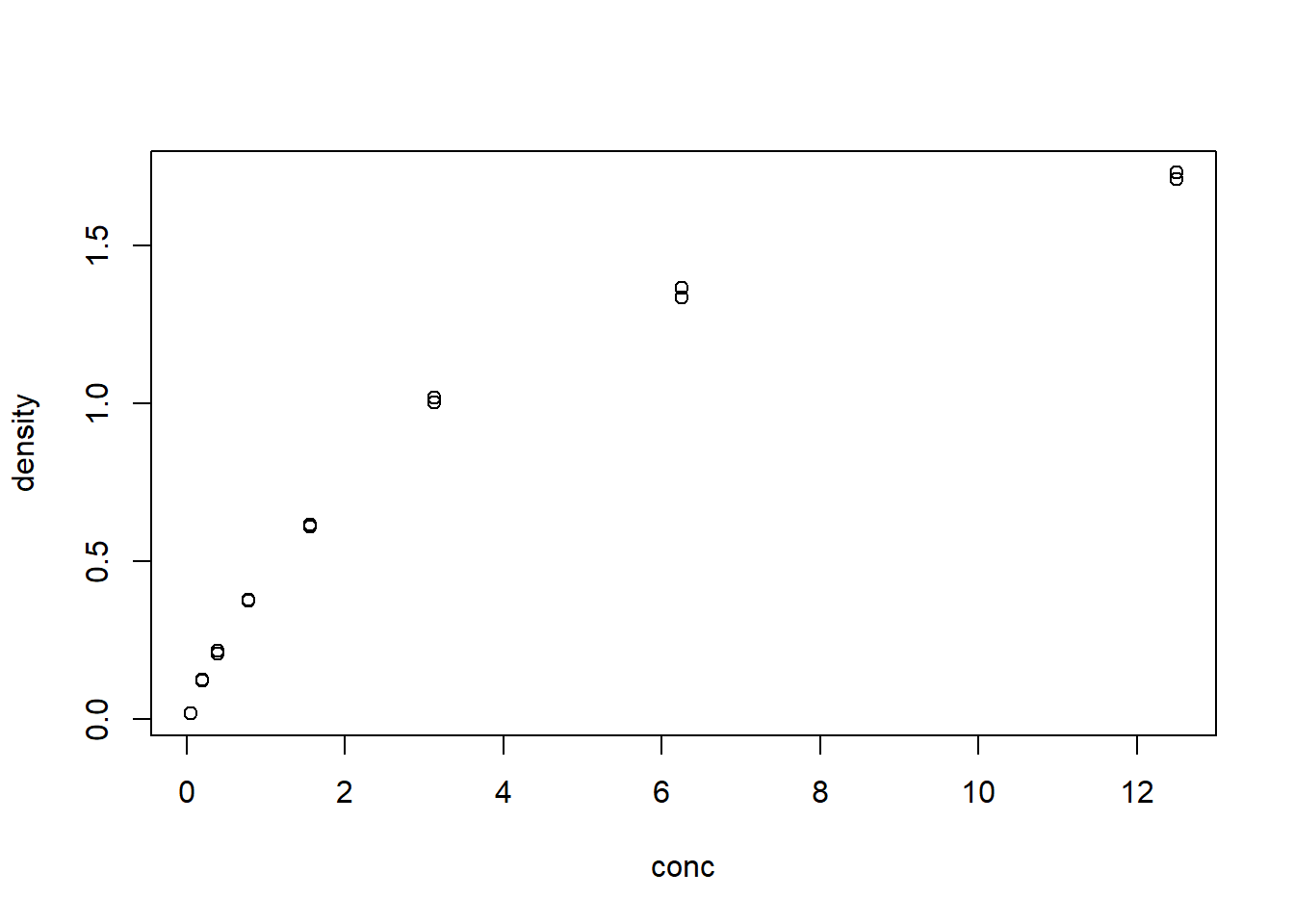
geom_barで、棒グラフの中身の色を変えたい時には、fill引数を指定する必要があります。
geom_barでfillを指定した場合
d1 |>
ggplot(aes(x = Species, y = mvalue, color = name, fill = name)) +
geom_bar(stat = "identity", position = "dodge")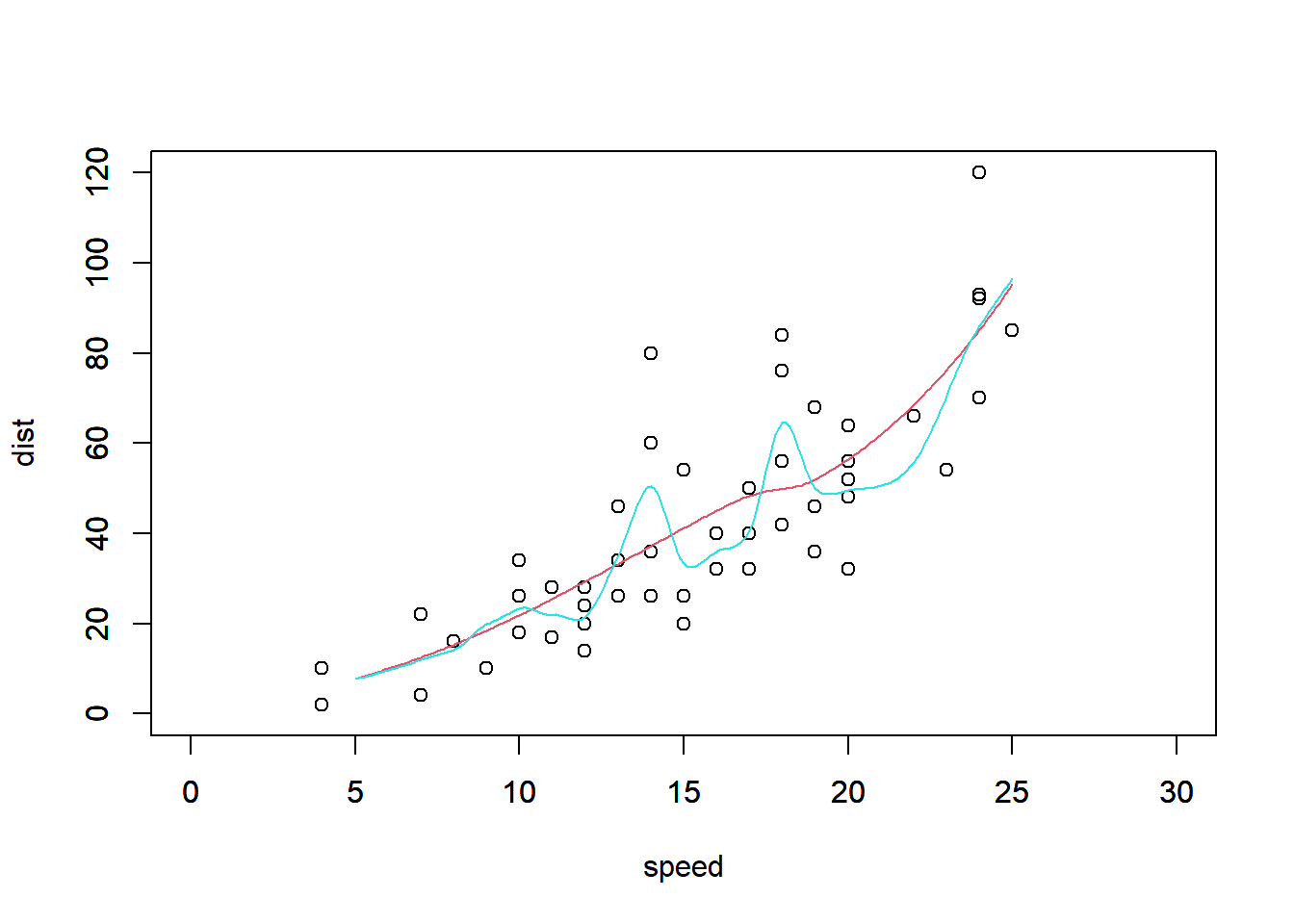
ggplot2では、colorやfillに引数を指定すれば、特に色の指定をしなくても、いい感じの色でグラフを作成してくれます。ただし、デフォルトの色では見にくい時や、デザイン的に別の色を用いたい場合もあります。色を別途指定したい場合には、ColorBrewerを用いた色の設定を行います。
ggplot2でColorBrewerに従った色を用いる場合には、scale_color_brewerを用います。通常のgeom関数と同様に、scale_color_brewerも+で繋いで用います。同様に、fillに指定した色の配色を変えたい場合には、scale_fill_brewerを用います。
色の指定にはpalette引数を用います。palette引数には、カラーパレットを指定する文字列を指定します。カラーパレットの種類はヘルプ(?scale_color_brewer)から確認できます。
scale_color_brewerで色を変更
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point() +
scale_color_brewer(palette = "Set1")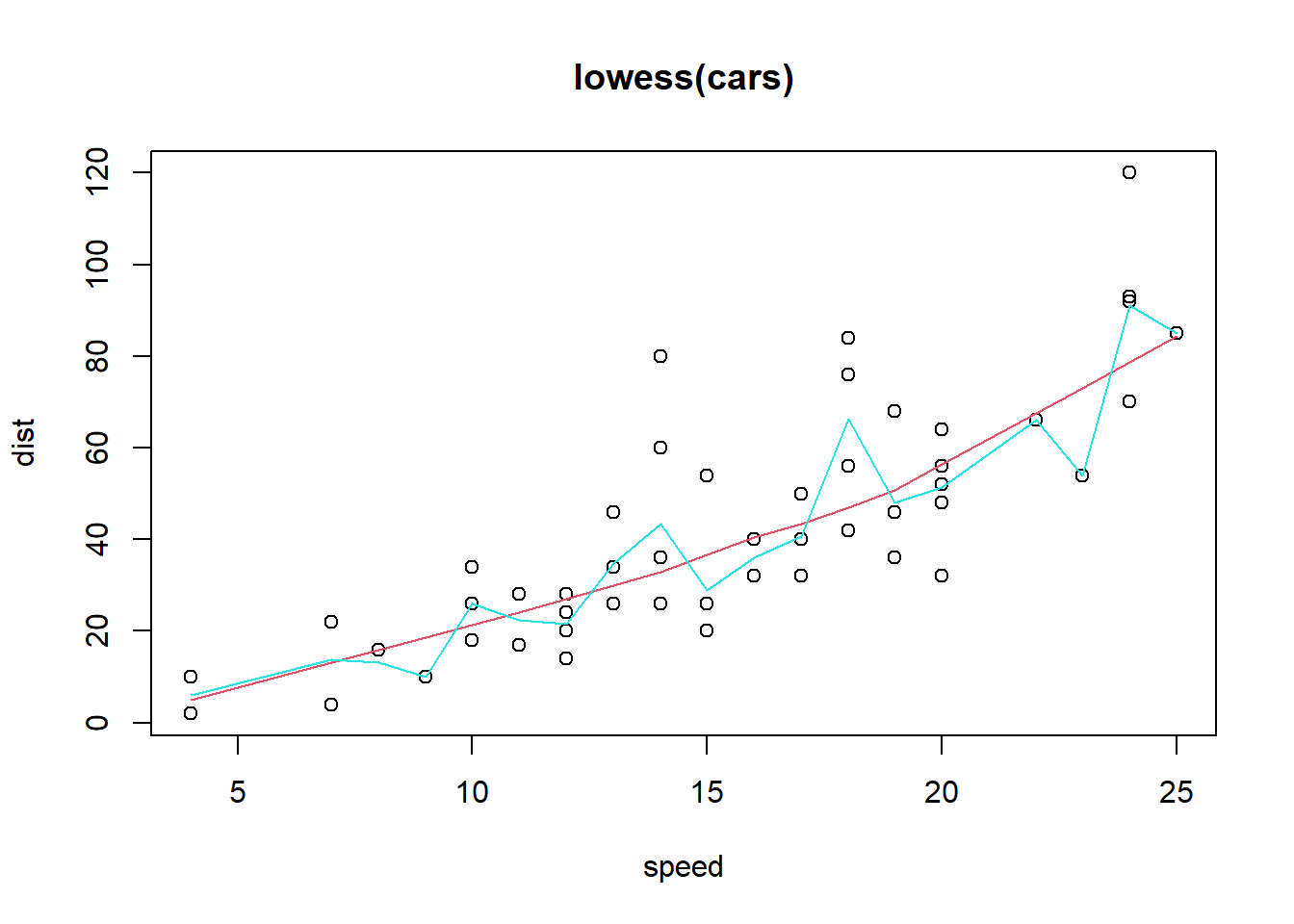
colorに数値を指定した場合には、scale_color_distillerで色を指定します。fillに数値を指定する場合には、scale_fill_distillerを用います。
scale_color_distillerで色を変更
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Petal.Length)) +
geom_point() +
scale_color_distiller(palette = "RdYlBu")
geom_pointなどで点のサイズを変更する場合には、size引数を指定します。
sizeで点のサイズを指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point(size = 10)
size引数はaes内で、数値の列名を取る形でも宣言できます。aes内で数値で指定した場合には、その数値に応じた点のサイズで表示されます。このように点のサイズを列名で指定することで、3つの要素(x、y、size)を3次元グラフを用いることなく表現することができます。このようなグラフのことをバブルチャートと呼びます。
sizeに数値を指定する
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species, size = Petal.Length)) +
geom_point()
点が大きくなると、重なった点は見えなくなります。重なった点を表示する方法には、ジッタープロット(geom_jitter)などがありますが、x軸もy軸も数値の場合には、位置がランダムに変化することで正確な値を示さなくなります。
重なった点を適切に表示する場合、透明化が有効となる場合があります。上で説明した通り、透明化を指定する引数はalphaです。alphaには0~1までの値を指定することができ、0では完全に透明、1では完全に不透明の点を表示することになります。
geom_point中でalphaを指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point(size = 10, alpha = 0.2)
geom_line等の線グラフで線の太さを指定する場合にはlinewidth引数を、線のタイプを指定する場合には、linetype引数を用います。linewidth引数には太さを数値で指定します。linetypeには、"solid"、"dashed"、"dotted"、"dotdash"、"longdash"、"twodash"の各タイプがあり、それぞれ文字列で指定します。線タイプの詳細については、vignette("ggplot2-specs")を実行することで確認できます。
線の太さとタイプの指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_line(linewidth = 1, linetype = "dotted")
グラフの重ね書きを行う場合には、複数のgeom関数を+で繋ぎます。後に指定したgeom関数が重ね書きの上層(上のレイヤー)に表示されることになります。重ね書きしたグラフの色が下層のグラフの色と同一だと見えなくなってしまうため、通常は色を変えて表示します。
重ね書きするグラフの間でデータが異なる場合には、ggplot関数でデータフレーム・aesを設定せず、geom関数内でそれぞれdata・aesを指定します。dataにはデータフレームを指定します。geom関数内で別のdataを指定することで、それぞれのgeom関数のグラフに別のデータフレームからのデータを用いることもできます。
boxplotとjitterplotを重ね書き
iris |>
ggplot(aes(x = Species, y = Sepal.Length)) +
geom_boxplot() +
geom_jitter(aes(color = Species), width = 0.2, height = 0)
データフレームに異なる要素(因子)のデータが保存されており、要素ごとに別々にグラフにしたい場合には、facetting(facet:宝石のカットの面のこと)を用います。facettingには、facet_wrapとfacet_gridの2つの関数ががあります。facet_wrapはデータフレームの要素で分けたグラフを単に並べたもの、facet_gridはx、y方向に要素がそろったグラフ群を作成する関数です。
以下はfacet_wrapの例です。グラフを分ける要素は、facet_wrap内でチルダ(~)を用いて指定します。チルダの左側、右側のどちらに要素をおいても問題ありませんが、右側の要素を入力しない場合には、ピリオド(.)を入力しておきます。グラフはよい感じに縦・横に並べられ、表示されます。並べる順番は要素の因子(factor)のレベル順となります。
facet_wrap関数
d1 |>
ggplot(aes(x = Species, y = mvalue)) +
geom_bar(stat = "identity") +
facet_wrap(~ name)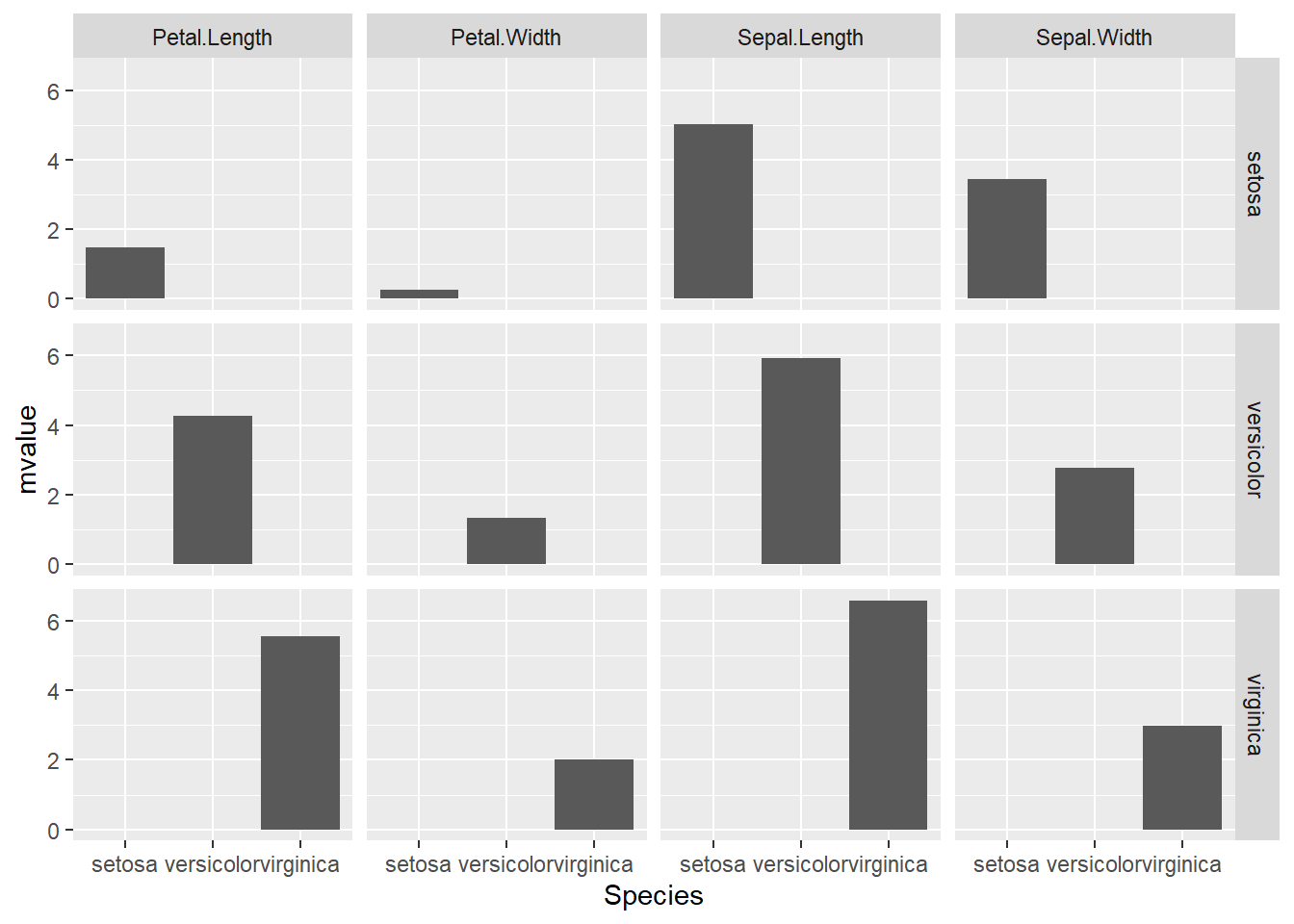
facet_wrapを用いたときに、表示するグラフごとに縦軸のスケールを調整する場合には、scales引数を指定します。scales引数はfacet_wrap関数内で指定し、scales="free_y"ならy方向のスケールが、scales="free_x"ならx方向のスケールが、scales="free"ならx、y両方のスケールが自動的に調整されます。
facet_wrapでscalesを指定
# scalesを指定すると、y軸のスケールがグラフごとに自動調整される
d1 |>
ggplot(aes(x = Species, y = mvalue)) +
geom_bar(stat = "identity") +
facet_wrap(~ name, scales = "free_y")
facet_gridでは、チルダの左と右の要素でそれぞれy軸方向、x軸方向を指定することになります。縦-横方向の軸の値もそろえられます。
facet_grid関数
d1 |>
ggplot(aes(x = Species, y = mvalue)) +
geom_bar(stat = "identity") +
facet_grid(Species ~ name)
軸のラベルやタイトル等を設定する場合には、labs関数を用います。labs関数も+で繋いで用います。x、y、title、subtitle、caption引数を指定することでそれぞれx軸ラベル、y軸ラベル、メインタイトル、サブタイトル、キャプション(注釈)をグラフに追加することができます。
labsでラベルの編集
iris |>
ggplot(aes(x = Sepal.Length)) +
geom_histogram(bins = 30) +
labs(
x = "length",
y = "count",
title = "main title",
subtitle = "sub title",
caption = "caption")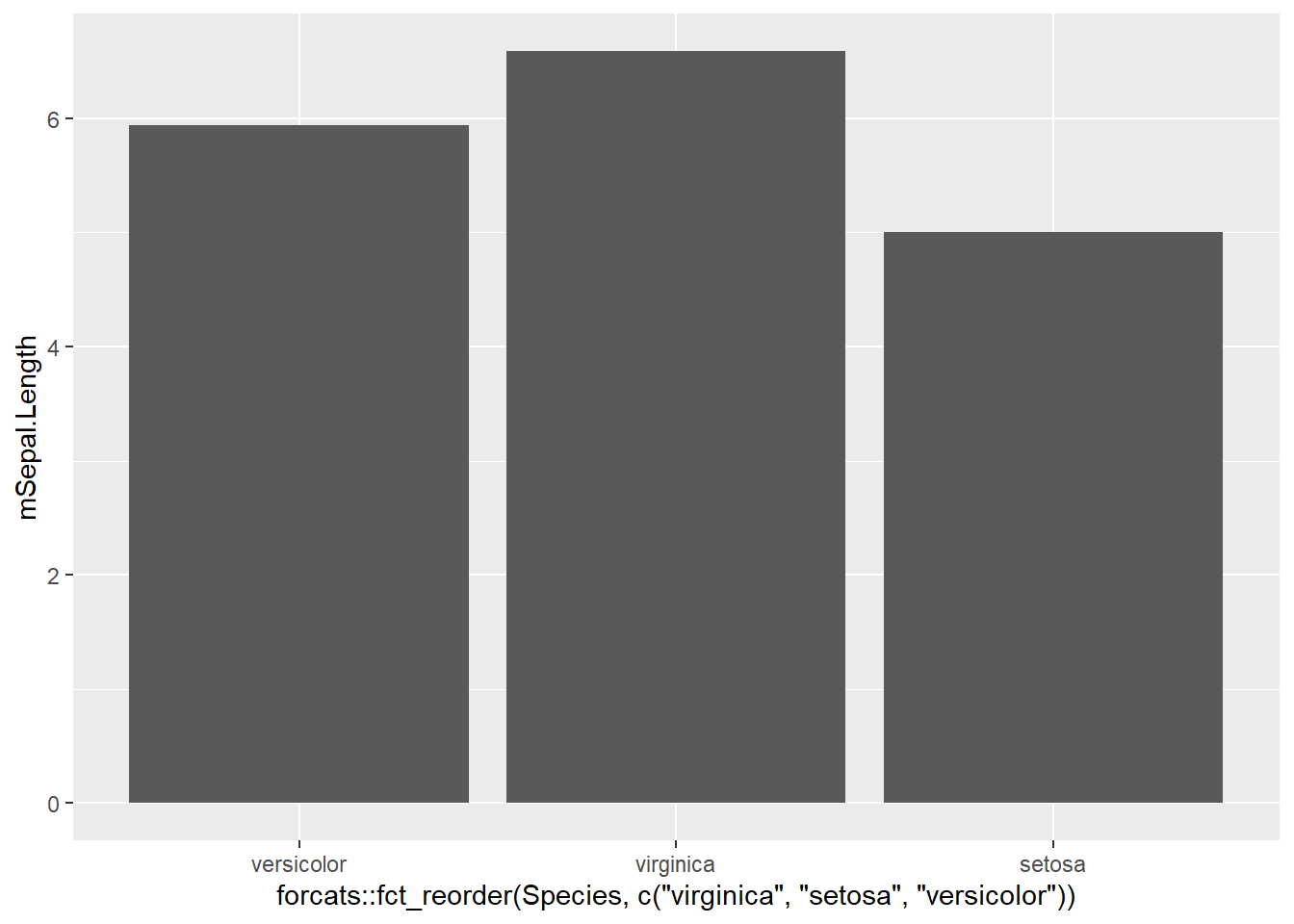
x軸、y軸の数値を対数変換する場合には、scale_x_log10、scale_y_log10を用います。他のggplot2の関数と同様に、scale_x_log10、scale_y_log10も+で繋ぐことで、x軸、y軸が対数変換されます。
軸スケールの変換
diamonds |>
ggplot(aes(x = price)) +
geom_histogram(bins = 50) +
scale_x_log10()
同様の軸の変換の関数には、scale_x_reverse、scale_x_sqrtなどがあります。それぞれ軸を正負反転、平方根に変換するのに用います。
x軸に因子を指定した場合の棒グラフなどの並び順は、その因子のレベルの順番で決まります。ですので、forcatパッケージのfct_reorderを用いて並べ替えることができます。
fct_reorderで順番を変更する
d |>
ggplot(aes(x = forcats::fct_reorder(Species, c("virginica", "setosa", "versicolor")), y = mSepal.Length)) +
geom_bar(stat = "identity")
fct_reorder関数は他の数値を参照して、その数値の順番で並べ替えることもできます。
fct_reorderで数値に従い並べ替え
d |>
ggplot(aes(x = forcats::fct_reorder(Species, mSepal.Length, .desc=TRUE), y = mSepal.Length)) +
geom_bar(stat = "identity")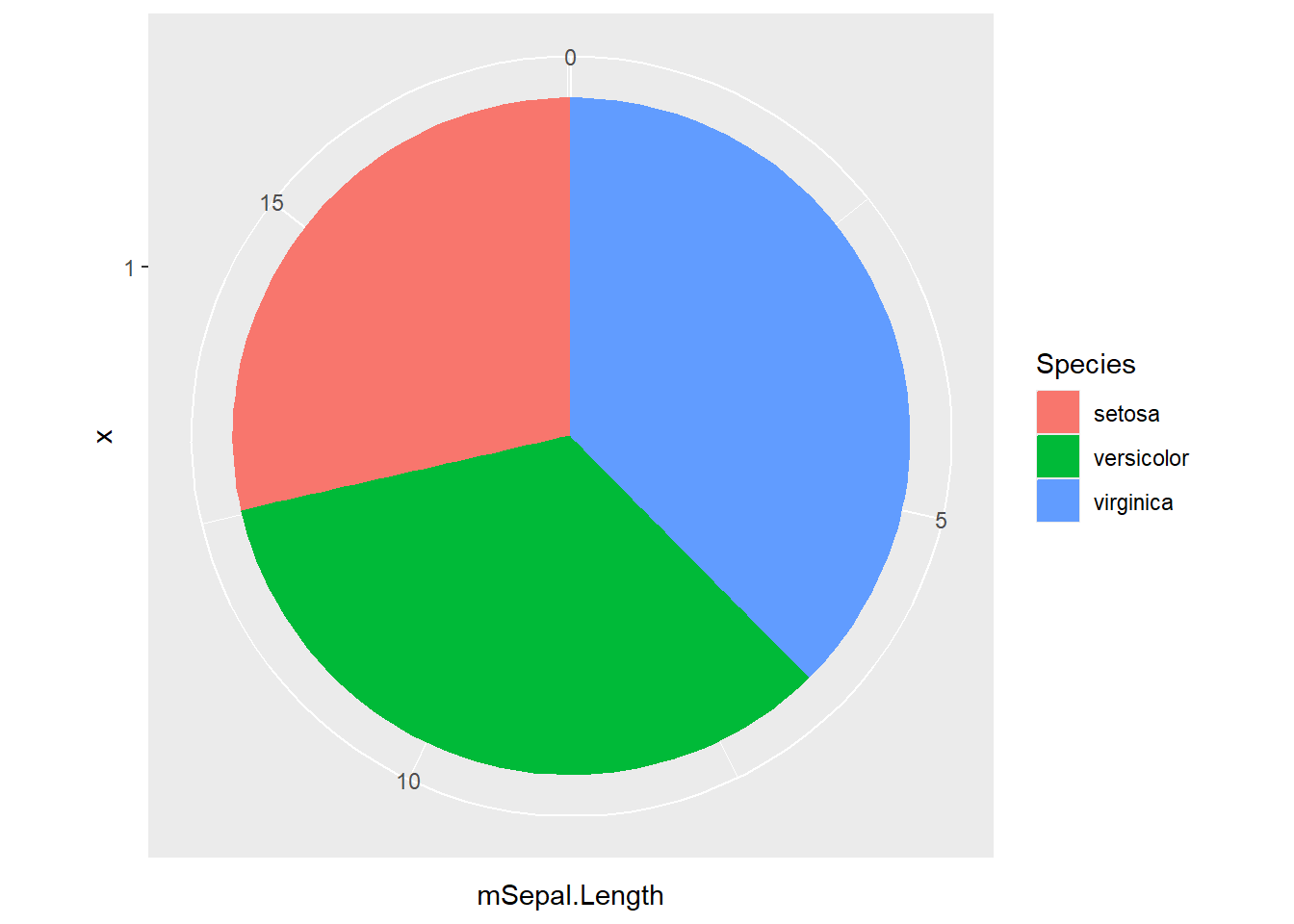
同様の数値による順番の変更は、reorder関数を用いても行うことができます。
reorder関数で並べ替え
d |>
ggplot(aes(x = reorder(Species, mSepal.Length, decreasing = TRUE), y = mSepal.Length)) +
geom_bar(stat = "identity")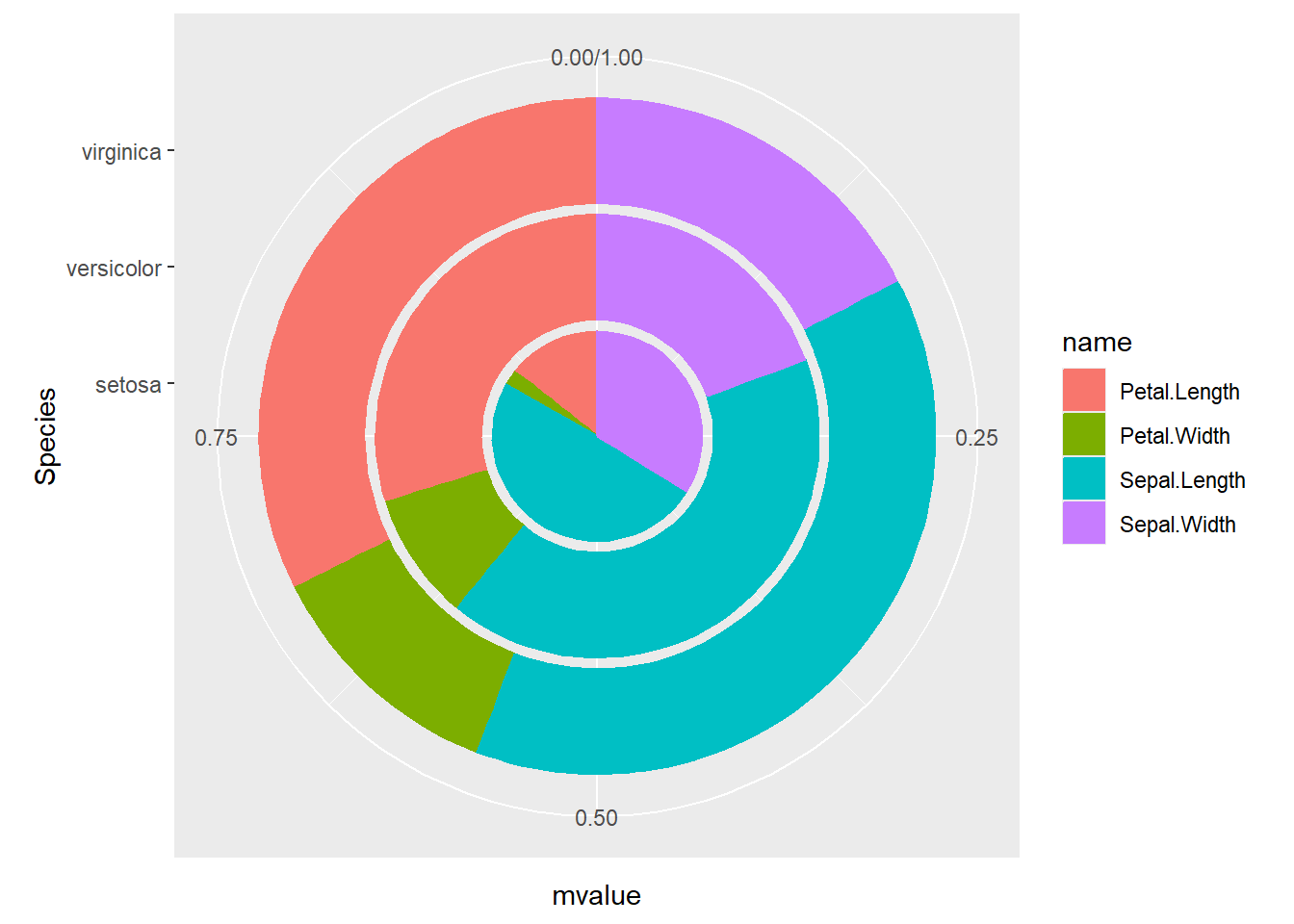
ggplot2で円グラフを作成する場合には、coord_polarを用います。coord_polarは軸を円形に配置する関数で、棒グラフを描画し、coord_polarの引数にtheta="y"を指定すると、円グラフが描画されます。
coord_polarで円グラフの指定
d |>
ggplot(aes(x = "1", y = mSepal.Length, color = Species, fill=Species)) +
geom_bar(stat = "identity") +
coord_polar(theta = "y")
棒を複数描画するような場合には、中心からいくつかの層に分かれて円グラフが描画されます。position="fill"を指定すると、棒グラフの高さがそろい、値は割合に変化するため、異なる要素間での比較を示すことができます。ただし、pie関数のhelpに記載されている通り、円グラフではデータの比較が難しくなります。基本的に円グラフを用いない方が良いでしょう。
coord_polarでは見にくい場合
p1 +
geom_bar(stat = "identity", position="fill") +
coord_polar(theta = "y")
themeは、グラフのもっと細かな要素を調整するための関数です。themeには非常に多くの引数が設定されており、themeを用いることで軸ラベルなどのフォントサイズや色、回転、凡例の位置等を調整することができます。代表的な例として、theme関数のlegend.position引数を用いて、凡例をグラフの下に表示した場合を下に示します。凡例を消す場合には、legend.position="none"を指定します。themeの引数には関数を取るものあり、設定はやや複雑ですが、うまく指定すれば様々なグラフの要素を調整することができます。
themeの指定
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point() +
theme(legend.position = "bottom")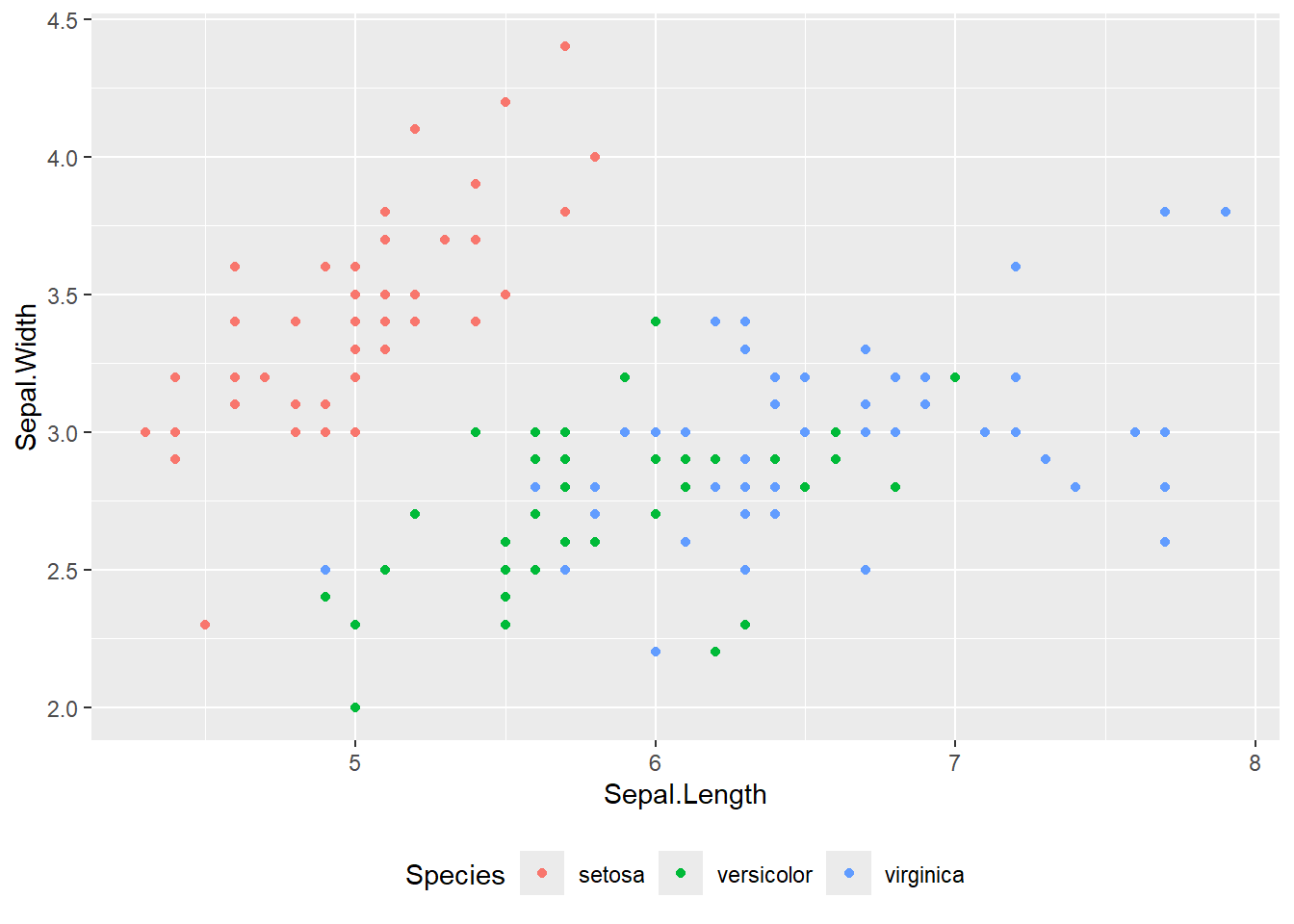
themeには、グラフのデザインを丸ごと変えることができる関数が別途用意されています。例えば、theme_bwででは背景が白いグラフ、theme_lightででは明るめ、theme_darkでは暗めの背景を用いたグラフを作成できます。
theme_bw関数で背景を白にする
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
theme_bw()
上記のグラフでは、Sepal.WidthもSepal.Lengthも最小値が0になっておらず、いわゆる「下駄をはいている」グラフになっています。ggplot2でx軸、y軸の最小値を指定する場合、expand_limits関数を用います。expand_limitsでは、x軸の最小値、y軸の最小値をそれぞれx、yの引数に指定します。
expand_limits関数で軸の最小値を指定する
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
expand_limits(x = 0, y = 0)
ggplot2のグラフを保存する時には、ggsave関数を用います。ggsave関数は第一引数にファイル名、第二引数にggplot2のプロットのオブジェクトを取ります。ファイルの形式はファイル名の拡張子に従い決定します。例えば、ファイル名が「.pdf」で終わっていればPDF、「.jpg」で終わっていればJPEGでグラフが保存されます。
グラフのサイズはwidth、height引数で、解像度はdpiで指定します。limitsize=FALSEと指定することで、縦横が50インチ以上の非常に大きいグラフを保存することもできます。
ggsave関数
# プロットのオブジェクトをpに代入
p <-
iris |>
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point()
# pをpdfで保存
ggsave("plot_iris_Sepal.pdf", p)また、Rstudioでは24章で説明した通り、右下ウインドウのメニューにある『Export』からグラフをファイルに保存することもできます。
ggplot2では、Rで実行した際には日本語も表示することができます。
p <-
cars |>
ggplot(aes(x = speed, y = dist)) +
geom_point(size = 2) +
labs(x = "自動車の速度", y = "停止までの距離")
p
ただし、このグラフをggsave関数でPDFとして保存すると、文字化けします。
PDFで文字化けするggplot2
ggsave("./image/cars.pdf", p)Saving 7 x 5 in image
一方で、PNGのような画像ファイルとして保存すると、日本語がそのまま表示されます。R上で日本語が文字化けせずに表示されるのは、出力がペイント系の画像になっているからです。
pngでは文字化けしない
ggsave("./image/cars.png", p)Saving 7 x 5 in image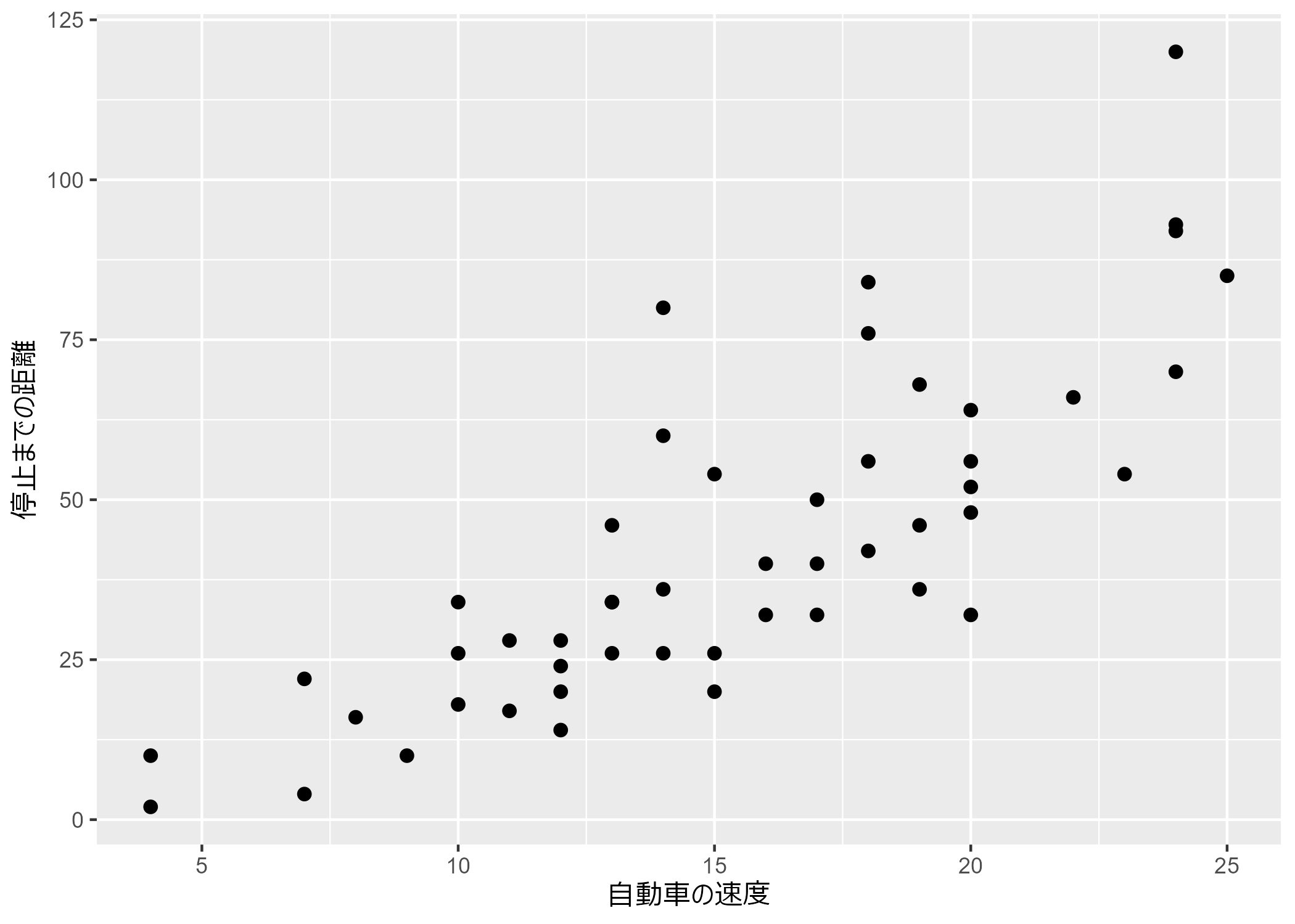
つまり、PDFやEPSのようなドロー系のファイル形式で日本語を含むggplot2のグラフを保存すると、文字化けします。このPDFにすると文字化けする問題は日本のRユーザーを長く悩ませてきました。
日本語を文字化けさせずに表示させる、様々な手法が提案されていますが、なかなか安定して日本語にすることは難しいです。比較的簡単な方法としては、以下のように引数にdevice=cairo_pdfを指定し、さらにfamilyという引数にフォント名を指定する方法があります。
cairo_pdfをデバイスに指定する方法
ggsave("./image/cars_cairo_pdf.pdf", p, device=cairo_pdf, family = "Meiryo UI")Saving 7 x 5 in imageこの他にも様々な日本語を文字化けさせない方法があります。ファイルの保存に関してはこちらのページにも詳しく記載されているので、参考にされるとよいでしょう。
ggplot2には、ggplot2に機能を追加するExtensionsというパッケージがたくさん存在します。代表的なExtensionsを以下に紹介します。
まずは、複数のグラフを1つのデバイスにまとめて表示するpatchwork(Pedersen 2023)です。patchworkを用いれば、位置・幅等を簡単に調整しながら、2つ以上のグラフをまとめることができます。
patchworkを用いる時には、まずggplot2のオブジェクトを変数に代入しておくとよいでしょう。
ggplot2オブジェクトを変数に代入
pacman::p_load(patchwork)
p1 <- iris |> ggplot(aes(x = Sepal.Length, y = Sepal.Width)) + geom_point()
p2 <- iris |> ggplot(aes(x = Species, y = Petal.Length)) + geom_boxplot()
p3 <- iris |> ggplot(aes(x = Petal.Width)) + geom_histogram()
p4 <- iris |> ggplot(aes(x = Petal.Length, color = Species, fill = Species)) + geom_histogram(binwidth = 0.5)グラフを横に並べて表示するときには、+でオブジェクトを繋ぎます。
グラフを横に並べる
p1 + p2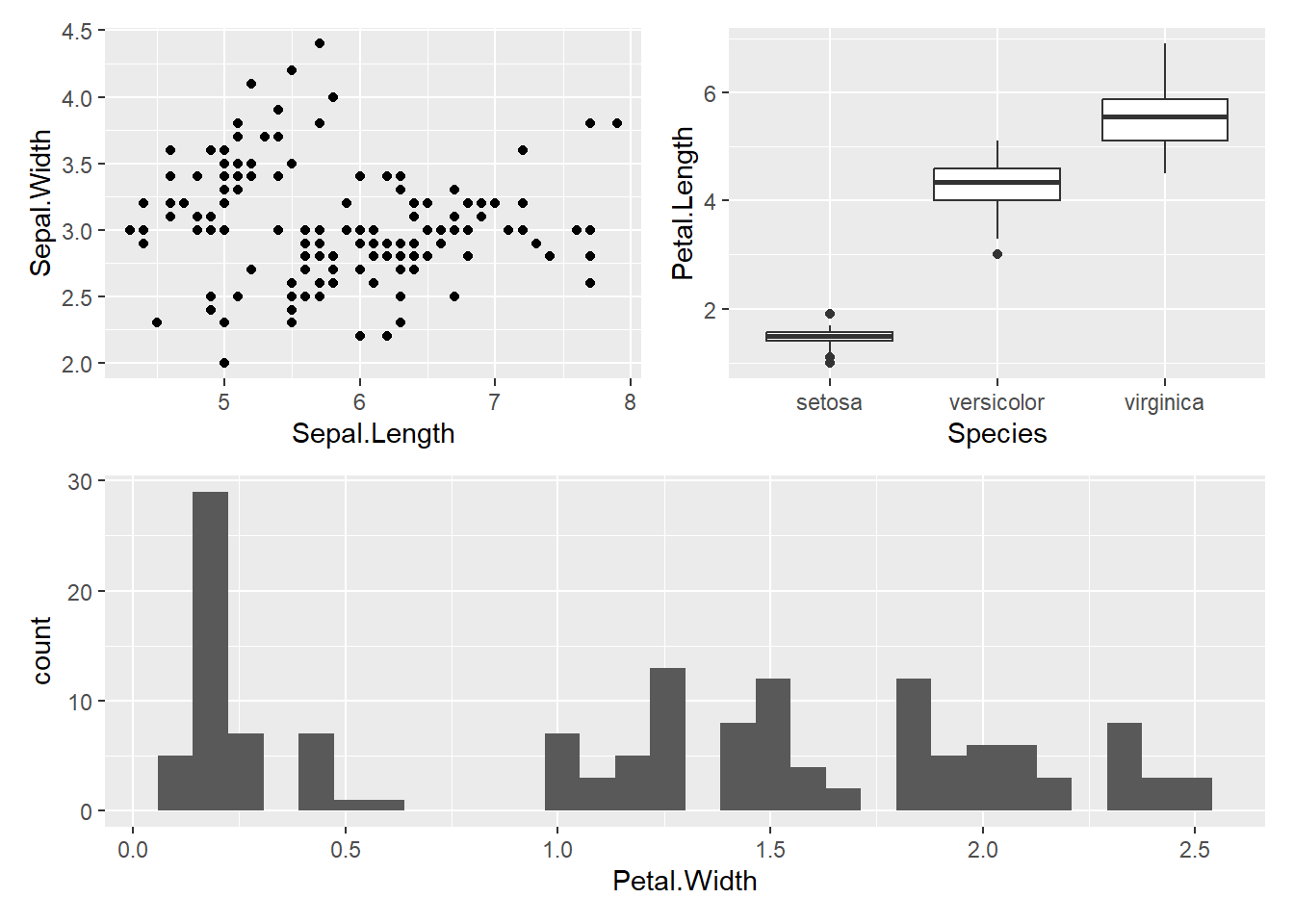
同様にカッコで囲えば表示を一部まとめておくことができます。また、|は横並び、/は縦並びにグラフを配置する場合に用います。
グラフを縦横に配置する
(p1 | p2) / p3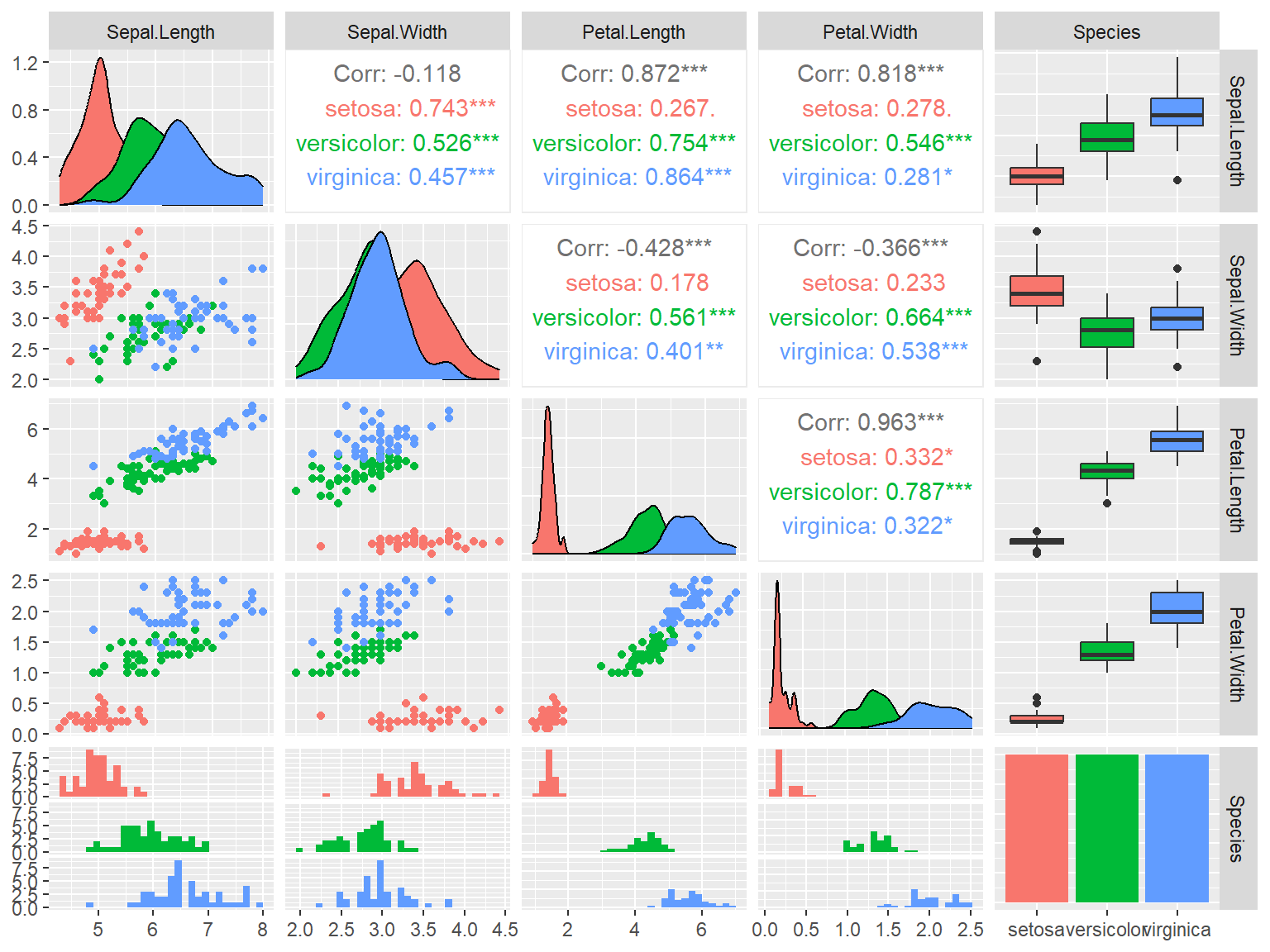
カッコ、|、/を組み合わせれば、グラフを様々な配置に並べて表示することができます。
カッコを用いて配置する
(p1 | p2) / (p3 | p4)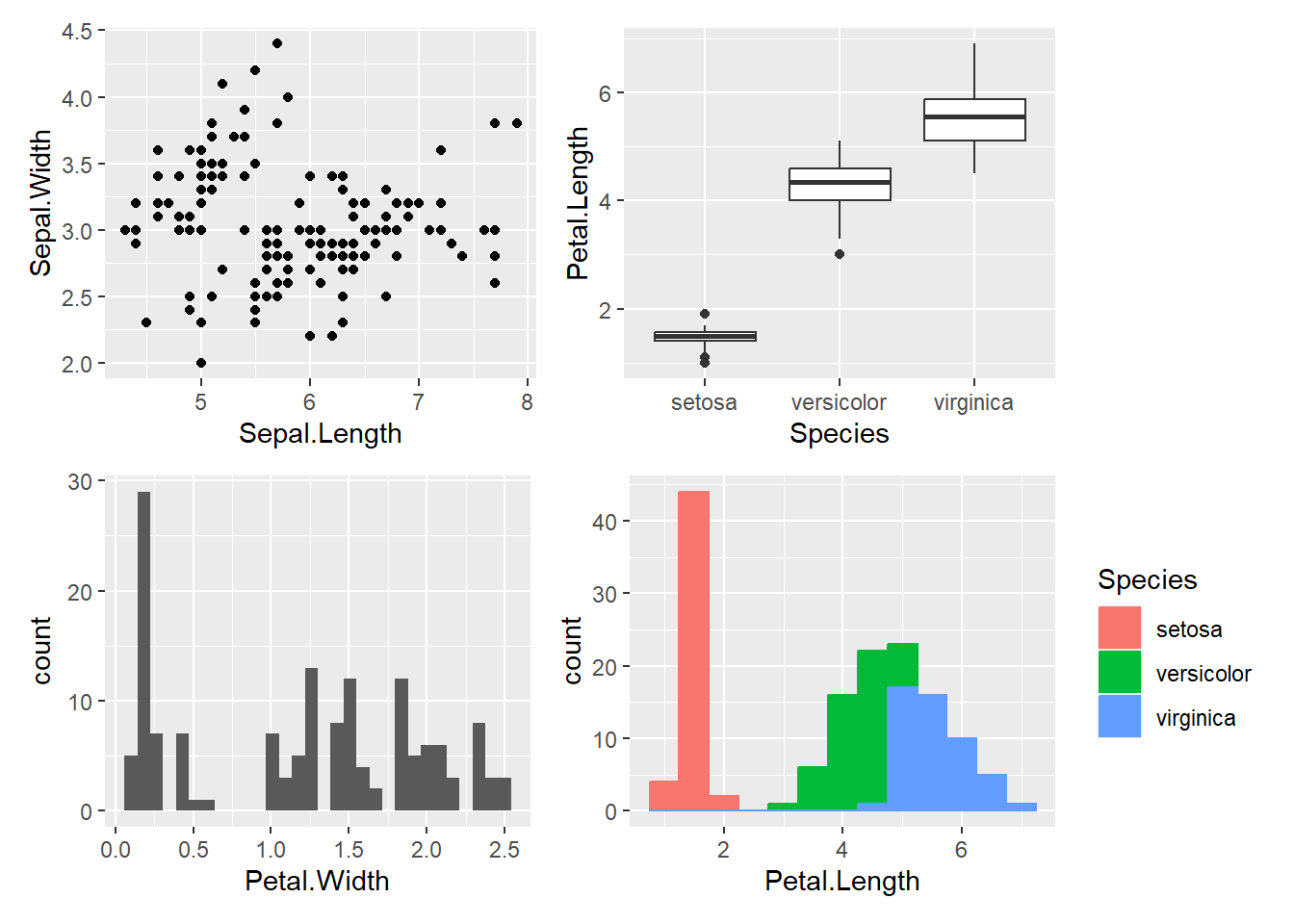
gganimate(Pedersen and Robinson 2022)はアニメーションを利用したグラフを作成するためのパッケージです。下の例では、gamminder(各国の年別のGDPと寿命、人口のデータ)をバブルチャートとし、年毎にアニメーションとしたものです。transition_timeという部分でアニメーションのフレームとなる変数を設定し、ease_aesという部分でフレームの間隔を表現します。
アニメーションをgifで保存する場合には、anim_save関数を用います。anim_save関数の引数の指定はggsaveと類似していますが、グラフオブジェクトをanimate関数の引数とした上で、rendererという引数を設定する必要があります。rendererには保存するファイル形式を指定します。gifアニメーションを作成するときにはrenderer=gifski_renderer()を指定します。このgifski_rendererを用いるためには、gifskiパッケージ(Ooms et al. 2023)を呼び出しておく必要があります。gif以外にもmpegなどのファイルにも保存できますが、別途パッケージの呼び出しが必要です。
gganimate関数でgifを作成
pacman::p_load(gganimate, gifski, gapminder)
p <- ggplot(gapminder, aes(gdpPercap, lifeExp, size = pop, colour = country)) +
geom_point(alpha = 0.7, show.legend = FALSE) +
scale_colour_manual(values = country_colors) +
scale_size(range = c(2, 12)) +
scale_x_log10() +
facet_wrap(~ continent) +
labs(title = 'Year: {frame_time}', x = 'GDP per capita', y = 'life expectancy') + # frame_timeで描画を指定
transition_time(year) + # yearの列をフレームとする
ease_aes('linear') # yearごとのフレーム間隔は一定
anim_save("p.gif", animate(p, renderer = gifski_renderer())) # 描画の方法を指定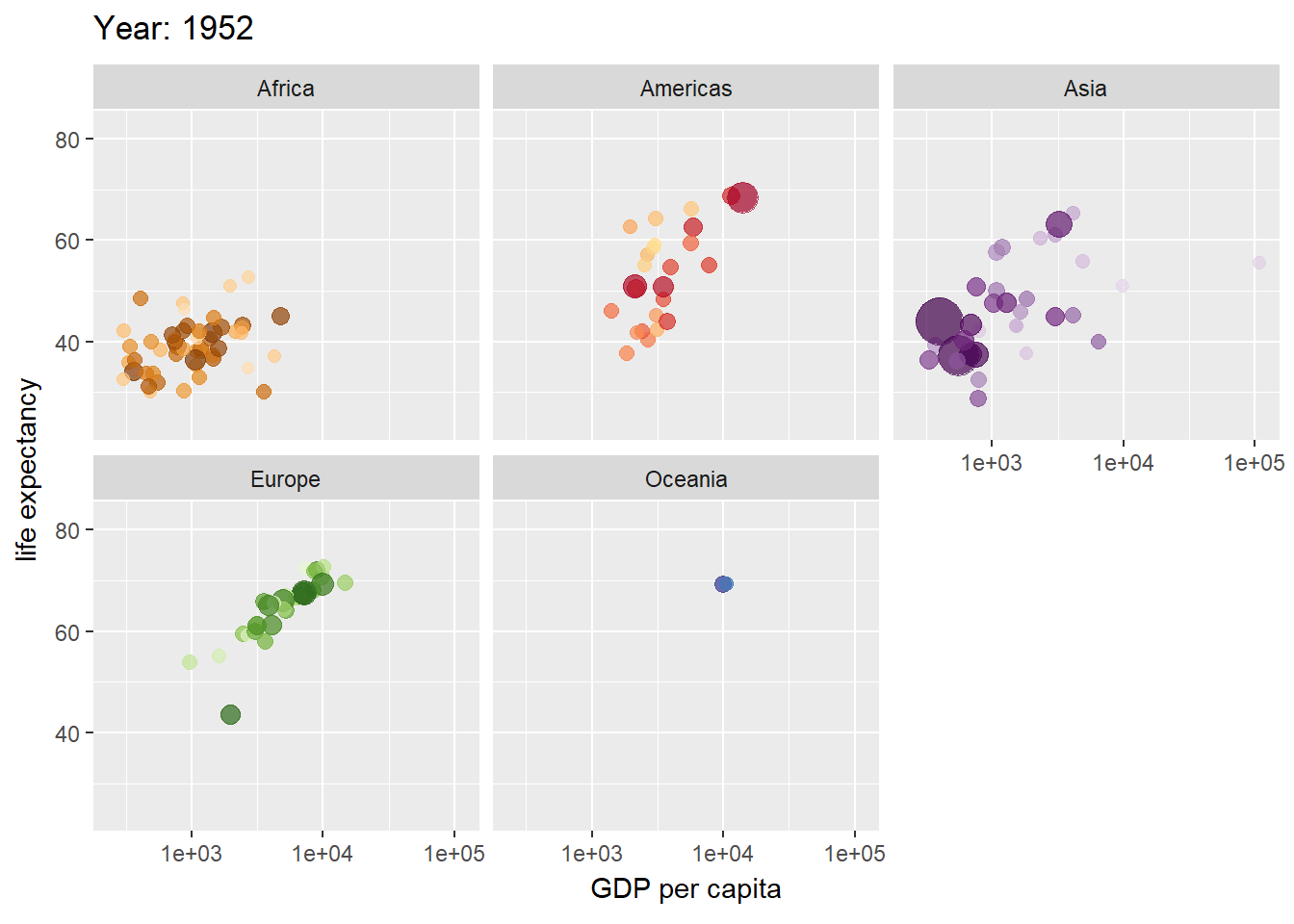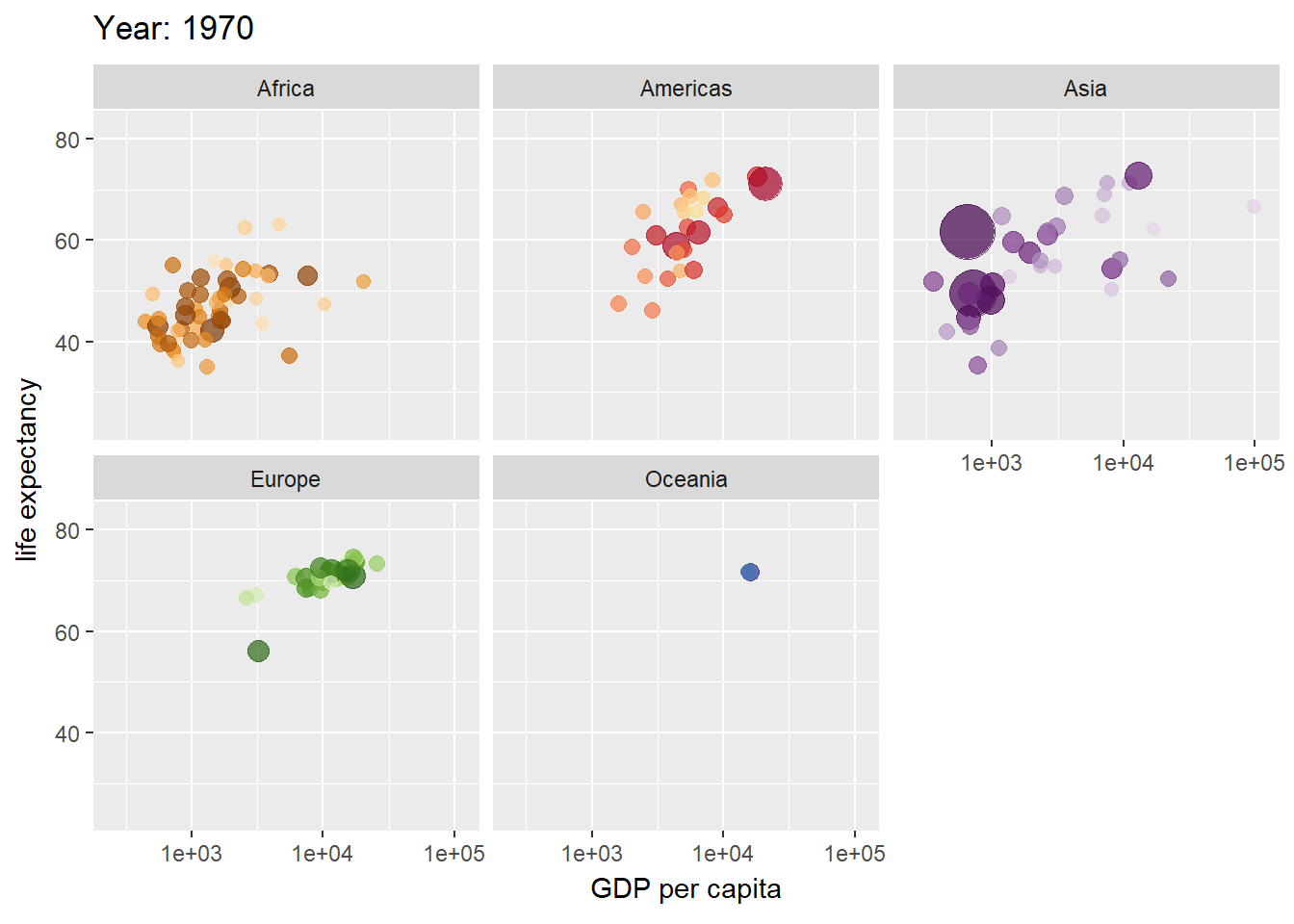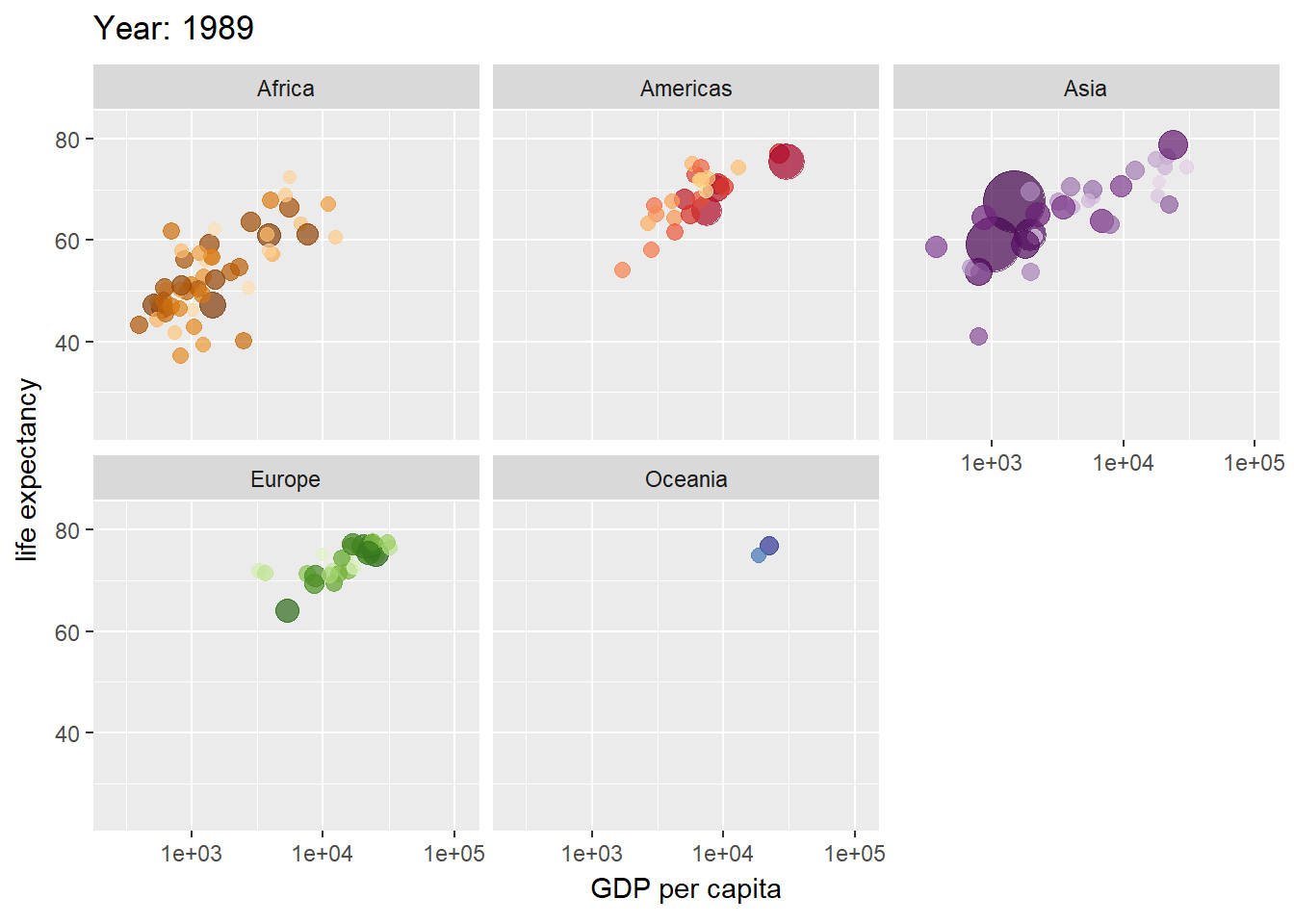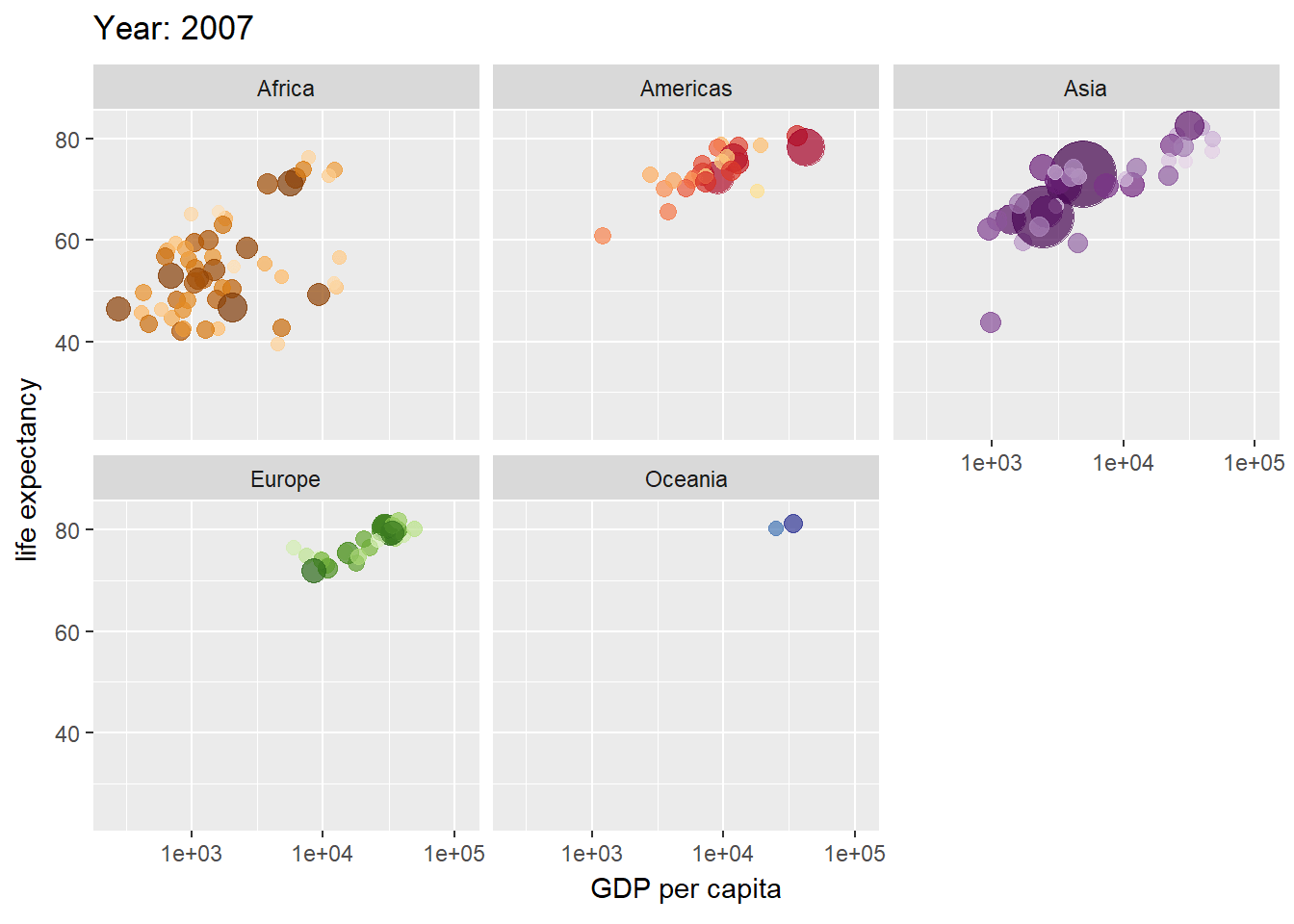
GGally(Schloerke et al. 2023)はggplot2を使って、相関行列を描画するためのExtensionです。各列のデータの型に従い、表示するグラフの形を変えてくれたり、相関係数を表示してくれたりします。pairs関数を用いてグラフを書くよりもデータの特徴をとらえやすい相関行列の図を簡単に作成することができます。
GGally::ggpairs関数
pacman::p_load(GGally)
ggpairs(iris, mapping=aes(color=Species))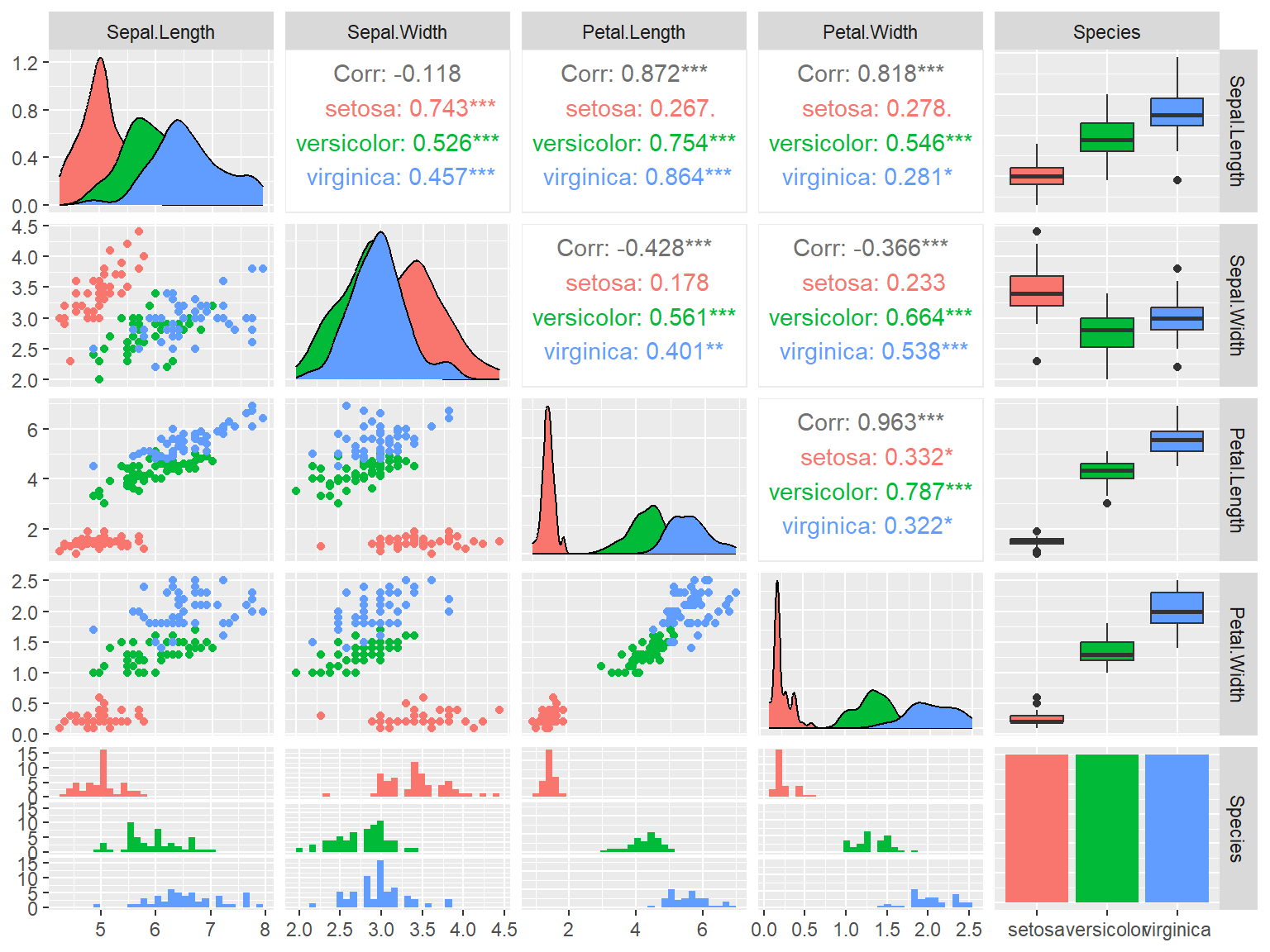
R以外の言語にも、グラフ作成のライブラリが備わっています。例えばPythonでは、matplotlibやseaborn、plotlyなどがあります。JuliaではGRがデフォルトのグラフ作成ライブラリです。いずれもどちらかと言えばRのデフォルトに近い関数を用いてグラフを作成するようです。
ggplot2では、データ、aes、グラフの形をそれぞれggplot、aes、geom関数で表現し、ジェネリック関数として設定された+で繋ぐ点が特徴です。特徴が他のパッケージとは異なるため、記法に慣れるまでは他のパッケージよりグラフを作成するのが難しく感じるかもしれません。しかし、ggplot2の経験を積み、慣れてしまえば表現したいグラフを他のパッケージよりスムーズに作成することができます。