c関数とappend関数でベクターを作成する
15 ベクター
ベクター(vector)はRのクラスのうち、最も基本的なものです。R以外の言語では、要素が1つのクラスと、複数の要素を持つクラスは明確に区別されることが多いですが、Rでは、要素が1つでも複数でも全てベクターとして取り扱います。ベクターでは繰り返し処理を用いることなく、すべての要素に対して演算を行うことができます。
ベクターには、
- データ型が1つだけ
- データ型が異なる要素が入ると、ベクター全体の型が変化する
- 演算には反復(recycling)が用いられる
という特徴があります。
15.1 ベクターの作成と結合:cとappend
要素が一つのベクターは関数などを特に用いることなく作成することができます。要素が複数のベクターはc関数(cはconbineの略)で作成することができます。c関数はベクター同士をつなぐのにも使えます。
append関数もベクター同士を結合するのに使います。append関数では、ベクターを追加する位置をafter引数で指定することができます。
15.2 連続する数値ベクターを作成する:コロン(:)、sep、seq
連続する整数や、一定間隔の数列、繰り返しのあるベクターを作成する場合には、:(コロン)、seq関数、rep関数を用います。
:(コロン)は連続する数値のベクターを作成する演算子で、コロンの前に置いた数値から、後に置いた数値まで公差1の、連続する数値のベクターを作成します。コロンの前後には、マイナスの数値を設定することもできます(例えば、-1:-3とすると、-1, -2, -3のベクターとなります)。このコロンの演算は、他の演算子より前に実行されます。
seq関数は、第一引数(from)から第二引数(to)まで、by引数で指定した間隔で連続する数値のベクターを作成する関数です。また、by引数の代わりに、length.out引数を設定すると、fromからtoまで、length.outで指定した長さのベクターを作成することができます。
rep関数は、第一引数にベクターを取り、第二引数に繰り返しの回数を取る関数です。rep関数の出力は、第一引数のベクターを第二引数の回数だけ繰り返したものになります。第二引数にはベクターを取ることもでき、ベクターで指定した回数だけ、要素を繰り返したベクターを作成することができます。
連続した数値ベクターを作成する
1:3 # 1から3までの整数のベクター
## [1] 1 2 3
-5:5 # -5から5までの整数のベクター
## [1] -5 -4 -3 -2 -1 0 1 2 3 4 5
-1:-10 # -1から-10までの整数のベクター
## [1] -1 -2 -3 -4 -5 -6 -7 -8 -9 -10
-1:-10 * 5 # コロンの演算は掛け算より先に行われる
## [1] -5 -10 -15 -20 -25 -30 -35 -40 -45 -50
seq(1, 5, by=0.5) # 1から5まで、0.5間隔のベクター
## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
seq(1, 5, length.out=11) # 1から5まで、等間隔の長さ11のベクター
## [1] 1.0 1.4 1.8 2.2 2.6 3.0 3.4 3.8 4.2 4.6 5.0
x # xは1、2、3のベクター
## [1] 1 2 3
rep(x, 5) # xを5回繰り返す
## [1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3
rep(x, c(1, 2, 3)) # xの要素を1、2、3回繰り返す
## [1] 1 2 2 3 3 315.3 ベクターの型
ベクターの型は、ベクターに含まれる要素によって変化します。数値のベクターはnumeric、文字列が含まれるベクターはcharacter、因子であればfactor(factorはクラスで、型はnumeric)、論理型であればlogicalとなります。ベクターは1つの型からなる要素の集合ですので、別の型の要素が付け加えられると、元のベクター、もしくは付け加えられた要素の型が変化します。型の優先順位はcharacter > numeric > logical = factorという順で、型が混じったベクターはより優先される型に自動的に変換されます。
ベクターはatomic vectorと呼ばれることもあります。ベクターであることの確認には、is.atomic関数を用います。この関数は、引数がベクターであればTRUE、ベクター以外であればFALSEを返します。
ベクターの型・クラス
class(c(x, 4)) # 数値ベクター(numeric)
## [1] "numeric"
class(c(x, "added")) # 文字列ベクター(character)
## [1] "character"
class(factor(x)) # 因子ベクター(factor)
## [1] "factor"
class(c(T, F, T)) # 論理型ベクター(logical)
## [1] "logical"
class(c(T, 1)) # logicalとnumericのベクターはnumeric
## [1] "numeric"
class(c(factor("dog"), 1)) # factorとnumericのベクターはnumeric
## [1] "numeric"
class(c(T, factor("dog"))) # logicalとfactorのベクターはnumeric(integer)
## [1] "integer"
class(c(1, "dog")) # numericとcharacterのベクターはcharacter
## [1] "character"
mode(c(x, 4))
## [1] "numeric"
mode(c(x, "added"))
## [1] "character"
mode(factor(x)) # 因子はクラスで、型は数値型
## [1] "numeric"
mode(c(T, F, T))
## [1] "logical"
is.atomic(1) # 長さ1のベクター
## [1] TRUE
is.atomic(c(1, 2)) # 長さ2以上のベクター
## [1] TRUE
is.atomic(list(1)) # リストはベクターではない
## [1] FALSE15.4 演算と反復(recycling)
Rのベクターでは、for文などの繰り返し文を用いることなく、すべての要素に対して演算を行うことができます。
ベクターの演算時には、反復(recycling)のルールが適用されます。長いベクターと短いベクターの演算で、反復のルールを確認してみましょう。
反復(recycling)
y <- c(2, 3, 4) # 長さ3のベクター
x # 長さ3のベクター
## [1] 1 2 3
y
## [1] 2 3 4
x + y
## [1] 3 5 7
x - y
## [1] -1 -1 -1
x * y
## [1] 2 6 12
x / y
## [1] 0.5000000 0.6666667 0.7500000
z <- c(2, 2, 2, 2, 2, 2) # 長さ6のベクター
x
## [1] 1 2 3
z
## [1] 2 2 2 2 2 2
x + z
## [1] 3 4 5 3 4 5
x - z
## [1] -1 0 1 -1 0 1
x * z
## [1] 2 4 6 2 4 6
x / z
## [1] 0.5 1.0 1.5 0.5 1.0 1.5長さが同じベクターでは、ベクターのインデックスが一致するもの同士が演算されていることがわかります。例えば、x(c(1, 2, 3))とy(c(2, 3, 4))の足し算は、1+2、2+3、3+4の結果となります。
一方で、長さが違うベクターを演算した場合には、短いベクターが反復(recycling)されます。x(c(1, 2, 3))とz(c(2, 2, 2, 2, 2, 2))の足し算では、前の3つのインデックスだけでなく、後ろの3つにもxの要素が足し算された結果が返ってきます(1+2, 2+2, 3+2, 1+2, 2+2, 3+2の結果が出力)。このように、短いベクターを繰り返して、長いベクターと同じ長さとし、結果を返すのが反復(recycling)のルールです。ベクターに数値を足し算するような場合にも、この反復と同じルールが適用されています。数値は長さ1のベクターですので、この長さ1のベクターを反復し、長さをあわせて計算した結果が返ってきていることになります。
このルールでは、短いベクターの長さがもう一方のベクターの長さの約数でない場合、中途半端に反復されることになります。下の場合では、c(1, 2)が反復されて、c(1, 2, 1)として取り扱われています。このような場合には、Rは警告(warning)を出します。
15.5 インデックス
ベクターの要素はインデックスを用いて取り出すことができます。インデックスはベクターの1つ目の要素が1、2つ目の要素が2、という形で設定されており、[ ](角カッコ)の中にインデックスを指定することで要素を取り出すことができます。
インデックスは整数のベクターの形でも指定できます。連続したインデックスを指定する際には、コロン(:)を用いて指定します。
ベクターのインデックス
x <- 2:11
x
## [1] 2 3 4 5 6 7 8 9 10 11
x[3] # 3つ目の要素を取り出す
## [1] 4
x[12] # 要素が無いとNAが返ってくる
## [1] NA
x[c(10, 5, 2)] # 10番目、5番目、2番目の要素を取り出す
## [1] 11 6 3
x[4:6] # 4番目から6番目までの要素を取り出す
## [1] 5 6 7インデックスをマイナスで指定すると、そのインデックスが指定する要素を削除することができます。インデックスをマイナスのベクターで指定すると、そのマイナスで指定した位置の要素が削除されます。
インデックスをマイナスで指定する
x[-4] # 4番目の要素を削除する
## [1] 2 3 4 6 7 8 9 10 11
x[-(5:8)] # 5番目から8番目までの要素を削除する
## [1] 2 3 4 5 10 11
x[-5:-8] # 上と同じ
## [1] 2 3 4 5 10 11インデックスは数値だけでなく、論理型(TRUEとFALSE)で指定することもできます。[ ]の中に、TRUE(T)とFALSE(F)のベクターを与えると、TRUEのインデックスにある要素だけを取り出すことができます。この指定では、反復(recycling)が適用されるので、ベクターの長さより論理型ベクターの長さが短ければ、論理型ベクターが反復されて使用されます。論理型ベクターの方が長い場合には反復は行われず、論理型ベクターが余分に長い分だけNAが返ってきます。
インデックスを論理型ベクターで指定できるため、比較演算子を用いてベクターの要素を取り出すこともできます。例えば、x[x > 5]という形で比較演算子を用いてインデックスを指定すると、xのベクターのうち、5より大きい要素のみを取り出すことができます。
比較演算子でインデックスを指定する
x == 5 # 論理型を比較演算子で作る
## [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
x[x == 5] # 比較演算子を含む演算もインデックスに取れる
## [1] 5
x[x > 5]
## [1] 6 7 8 9 10 11
x[x > 3 & x < 6] # 3より大きく、かつ6より小さいものを選ぶ
## [1] 4 5
x %in% c(2, 7) # %in%は後ろの要素と一致する場合にTRUEを返す
## [1] TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
x[x %in% c(2, 7)] # 2と7である要素を取り出す
## [1] 2 7ベクターの一部を確認したいときには、head関数とtail関数を用います。head関数はベクターの始めから6つ目までを、tail関数はベクターの後ろから6つ目までを表示する関数です。どちらも第二引数に数値を入れると、その長さのベクターを取り出すことができます。
15.6 インデックスの位置を特定する
インデックスの位置を特定する場合には、which関数を用います。which関数は引数に論理型(もしくは比較・論理演算子)を取り、TRUEになる位置のインデックスを返す関数です。
15.7 ベクターの要素に名前を付ける
ベクターには名前(names)というアトリビュートがあります。namesはベクターの要素に名前をつけるものです。namesの要素が重複していても問題はないのですが、後に述べる呼び出しの際に間違いの原因となるため、あまりオススメはできません。
ベクターの要素は上記の通り、インデックスを用いて呼び出すことができます。しかし、ベクターの要素はその名前からでも呼び出すことができます。呼び出すときには、角カッコ([ ])の中に、文字列で名前を示します。インデックスの代わりに名前の文字列を用いることで、名前に対応した要素を取り出すことができます。
ベクターの名前は、c関数を用いてベクターを作成するときに設定することができます。ベクターがすでに変数として準備されている場合には、names関数を用いて名前を設定することができます。このnames関数の引数にベクターを取り、names関数に名前を記載したベクターを代入する形で名前を設定することができます。
ベクターの名前もnames関数で確認することができます。ベクターでは、ドルマーク($)を用いて名前から要素を取り出すことはできません。
ベクターの複数の要素に同じ名前を付けた場合には、インデックスが最も前の要素だけを名前で呼び出すことができます。同じ名前を付けた2つ目、3つ目の要素を名前を用いて呼び出すことはできません。
ベクターの要素の名前
c(dog = 1, cat = 2, pig = 3) # 名前付きべクターをc関数で作る
## dog cat pig
## 1 2 3
x <- c(1, 2, 3)
names(x) <- c("dog", "cat", "pig") # ベクターに名前を設定する
names(x) # 名前が返ってくる
## [1] "dog" "cat" "pig"
x["cat"] # 名前の文字列をインデックスにすることができる
## cat
## 2
x$cat # 呼び出せない
## Error in `x$cat`:
## ! $ operator is invalid for atomic vectors
Tip連想配列とベクター
プログラミング言語には、連想配列(ハッシュやディクショナリなどとも呼ばれる)というデータ型を持つものがあります。連想配列は文字列(記号)と値を結びつけておき、文字列をインデックスとして値を呼び出すものです(例えば、banana=1、apple=2としておいて、bananaで呼び出すと1が返ってくる)。Rでは、ベクターにnamesが設定でき、名前を用いて要素を呼び出すことができるため、ベクターが連想配列の役割をこなすことができます。
15.8 ベクターの長さを調べる
ベクターは、名前以外に、長さ(length)を特性として持っています。ベクターの長さは、そのベクターの要素の数のことです。ベクターの長さはlength関数で調べることができます。ベクターは1次元の構造を持つデータですので、dimension(次元)を持ちません。
15.9 ベクターの並べ替えと要素の順番
ベクターの要素を順番に並べ替える場合には、sort関数を用います。sort関数はベクターを昇順に並べ替える関数ですが、decreasing=TRUEを指定すると降順に並べ替えることができます。ベクターを逆順に並べ替える場合には、rev関数を用います。
また、order関数とrank関数は要素の順番を返す関数です。order関数とrank関数ではタイデータの取り扱いが異なります。order関数はデータフレームの順番の並べ替えに使われます。
ベクターの並べ替えと要素の順番
15.10 重複する要素を取り除く
ベクター内の重複する要素を取り除く場合には、unique関数を用います。
15.10.0.1 アトリビュート(attribute)を付ける
Rでは、ベクターに名前以外のアトリビュートをつけることもできます。アトリビュートをつけるとき、アトリビュートを呼び出すときにはattr関数を用います。ただし、names以外のアトリビュートをベクターの要素の呼び出しに用いることはできません。
ベクターのアトリビュートを調べるときには、str関数を用いることもできます。strは「structure」の略で、様々なオブジェクトの構造を調べることができる便利な関数です。
attributeの確認
Tipアトリビュートの使い道
ベクターにnames以外のattributeを設定しても特に利点はないため、アトリビュートの設定を行うことはほぼありません。attributeには、namesの他にクラス名などが登録されます。
15.11 ランダムサンプリング
Rは統計の言語です。統計と確率は密接に関係しているため、統計の取り扱いにおいては、時に確率論的な現象を再現したい、という場合があります。確率論的な現象ではランダムなものを取り扱うため、Rではベクターからランダムに要素を取り出す関数、sample関数が備わっています。
このsample関数では、第一引数にベクター、第二引数にベクターから要素を取り出す回数を指定します。このランダムな取り出しには、復元抽出(1つの要素を何度も取り出すことができる)と非復元抽出(1つの要素を一度取り出すと、再度取り出されることがない)があります。復元抽出と非復元抽出の指定には、sample関数のreplace引数を用います。replace引数のデフォルトはFALSEで、replaceを指定しない場合には非復元抽出が行われます。復元抽出を行う場合には、replaceにTRUEを指定します。
sample関数と復元・非復元抽出
sample(1:10, 5) # 1~10の整数から5つをランダムに取り出す
## [1] 7 6 3 1 5
sample(1:10, 5) # ランダムに取り出すので、上とは異なる結果となる
## [1] 2 3 10 4 7
sample(1:10, 5, replace=FALSE) # 非復元抽出
## [1] 7 3 2 4 1
sample(1:10, 15, replace=FALSE) # エラー(1度しか取り出せない)
## Error in `sample.int()`:
## ! cannot take a sample larger than the population when 'replace = FALSE'
sample(1:10, 15, replace=TRUE) # 復元抽出ではエラーとならない
## [1] 8 6 4 5 10 2 1 1 6 6 5 6 6 1 415.12 ベクターを切り分ける:split
ベクターを同じ長さの因子で切り分けるのが、split関数です。split関数は2つの引数を取り、第一引数にはベクター、第二引数にはベクターと同じ長さの因子を取ります。因子のlevelsに従い、第一引数で指定したベクターを2つ以上のグループに切り分けます。split関数では、グループで切り分けたベクターがリストで返ってきます。
split関数
x <- rep(1:5, 5) # xは1~5を5回繰り返すベクター
y <- factor(c(rep(1, 10), rep(2, 15))) # xを切り分けるための因子
x
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
y
## [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## Levels: 1 2
split(x, y) # リストが返ってくる
## $`1`
## [1] 1 2 3 4 5 1 2 3 4 5
##
## $`2`
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5| 関数名 | ベクターに適用される演算 |
|---|---|
| head(x) | 始めの6つの要素を返す |
| tail(x) | 最後の6つの要素を返す |
| names(x) | 名前を表示する |
| names(x) <- y | yを名前に設定する |
| length(x) | 要素の数を返す |
| attr(x, which) | attribute(which)を返す |
| attr(x, which) <- y | attribute(which)をyに設定する |
| str(x) | 詳細な情報(構造、structure)を表示する |
| sample(x, size, replace) | xからsizeの個数の要素をランダムに取り出す |
| split(x, f) | 因子fに従ってベクターを分割する |
| sort(x) | 昇順に並べ替える |
| sort(x, decreasing=TRUE) | 降順に並べ替える |
| rev(x) | 逆順に並べ替える |
| unique(x) | 重複を取り除く |
15.13 集合としてのベクター
統計では、集合を取り扱う場合があります。集合としてベクターを取り扱い、積集合や和集合を取り扱う関数がRには備わっています。
ベクターの要素のうち、重複したものを取り除く関数がunique関数です。unique関数はベクターを引数に取り、引数に含まれる重複した要素を1つだけ残して取り除きます。
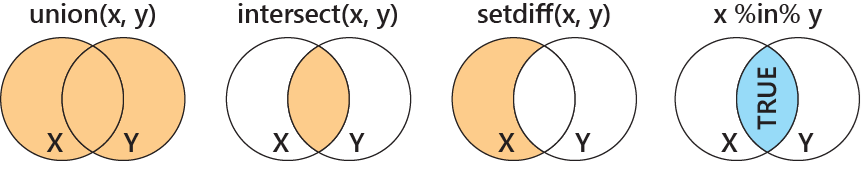
和集合と積集合を求める関数がunion関数とintersect関数です。union関数もintersect関数も共に2つのベクターを引数に取り、union関数は和集合(ベクターがxとyの時、\(x \cup y\))、intersect関数は積集合(ベクターがxとyの時、\(x \cap y\))を返します。
集合の差を示す関数がsetdiff関数です。setdiff関数も2つのベクターを引数に取り、第一引数にあって第二引数に無い要素を返します。
集合が同一とみなせるかどうか判断する関数がsetequal関数です。2つのベクターを引数に取り、2つのベクターの要素が同一であればTRUE、異なっていればFALSEを返します。
最後に、集合に関与する演算子である、%in%について説明します。%in%は前と後ろにベクターを取る演算子で、前のベクターにも後ろのベクターにもある要素(積集合の要素)にはTRUE、前のベクターにはあり、後ろのベクターには無い要素にはFALSEを返す関数です。
| 関数名 | 集合に適用する演算 |
|---|---|
| union(x, y) | xとyの和集合 |
| intersect(x, y) | xとyの積集合 |
| setdiff(x, y) | xにあってyに無い集合 |
| setequal(x, y) | xとyが同一かどうかを評価 |
| x %in% y | xのうち、yにある要素はTRUEを返す |
| duplicated | 重複した要素はTRUEを返す |
| anyDulricated | 重複した要素が出現する最小のインデックスを返す |
ベクターと集合の演算
x <- rep(1:5, 5)
x
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
unique(x)
## [1] 1 2 3 4 5
x <- 1:10
y <- 7:16
union(x, y) # xとyの和集合
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intersect(x, y) # xとyの積集合
## [1] 7 8 9 10
setdiff(x, y) # xにあってyに無いもの
## [1] 1 2 3 4 5 6
setdiff(y, x) # yにあってxに無いもの
## [1] 11 12 13 14 15 16
setequal(x, y) # xとyが同一かどうかを評価
## [1] FALSE
setequal(x, 10:1) # 要素が同一なのでTRUE
## [1] TRUE
x %in% y # xのうち、yにあるものはTRUE
## [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
duplicated(c(1, 2, 3, 4, 4, 4)) # 4が5番目から重複しているのでTRUE、それ以外はFALSE
## [1] FALSE FALSE FALSE FALSE TRUE TRUE
anyDuplicated(c(1, 2, 3, 4, 4, 4)) # 5番目の要素で重複があるので5を返す
## [1] 5
anyDuplicated(c(1, 2, 3, 4)) # 重複がないので0が返ってくる
## [1] 0