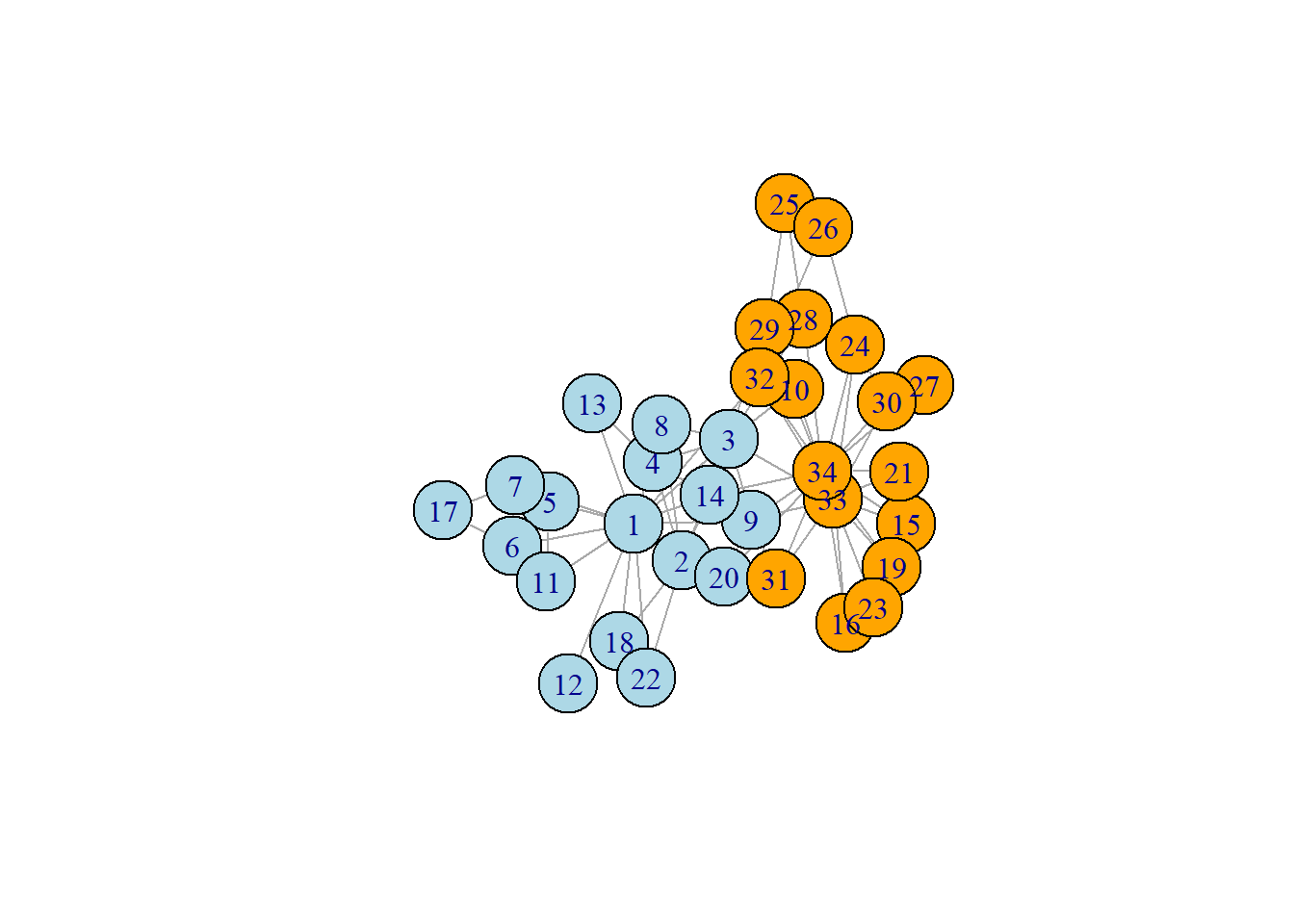パッケージのロード
pacman::p_load(igraph, tidygraph, tidyverse)ネットワーク解析とは、たくさんの人や都市、ウェブページなどの関係性(ネットワーク)を解析する一連の解析手法のことを指します。ここでのネットワークとは、例えば友人関係やメールの送付、電車の路線での駅同士のつながりや物資のやり取りなど、多岐に渡ります。生物学であれば代謝経路や遺伝子の誘導・抑制の関係性、会社であれば命令系統などもネットワークの例となります。これらのネットワークを表示し、特徴を抽出することでネットワークを評価する手法がネットワーク解析です。
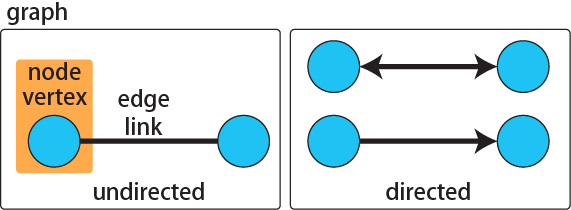
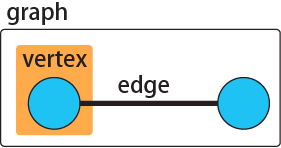
ネットワークの基本は、人や都市などの要素と、そのつながりの2つです。ネットワーク解析では、人や都市などの要素のことをnodeやvertex、つながりのことをlinkやedgeと呼びます。また、このネットワーク全体のことをgraphと呼びます。
linkやedge、つまりネットワークのつながりには、大きく分けて2つのタイプがあります。一つは友人関係や線路での結合など、方向性が無いもので、もう一つはメールの送付や物資の輸送などの方向性があるものです。方向性のないつながりのことを無向(undirected)、方向性のあるつながりのことを有向(directed)と呼びます。
ネットワーク解析の主要な目的は以下の通りです。
この他にランダムなグラフの作成、グラフの類似性の評価や検定を用いたネットワーク解析もあります。
Rでの主要なネットワーク解析パッケージには、statnet(Handcock et al. 2018; Hunter et al. 2008)系パッケージとigraph(Csardi and Nepusz 2006; Csárdi et al. 2024)系パッケージの2系統があります。どちらもネットワーク解析を行うために必要十分な機能を備えていますが、オブジェクトの取り扱いや関数名の特徴が異なります。どちらを使うかは好みで決めてしまってよいですが、igraph系の方が情報が多いため比較的使いやすいと思います。
statnetはsna(Butts 2023)やnetwork(Butts 2015, 2008)などの一連のネットワーク解析用パッケージの総称で、tidyverseのようにinstall.packages("statnet")で一度にインストールし、library(statnet)で一度にロードすることができます。statnetはよくできたパッケージ群だと思うのですが、解説文(Documentation)があまり充実しておらず、なかなか手を付けにくい印象があります。
igraphはネットワーク解析に必要な関数を一通り備えたパッケージで、RだけでなくpythonやMathematica、Cにも機能を提供しています。ネット上にもigraphの情報はたくさん落ちており、statnetよりは間口が広く学びやすいかと思います。ただし、statnetもigraphもたくさんの機能を備えたパッケージであり、学習コストは高めです。
このigraph、非常にたくさんの関数を備えたパッケージではあるのですが、関数の命名規則や引数の形が一定ではなく、そのまま使うとやや使いにくいです。また、tidyverseなどのRの標準的なパッケージとの相性もあまりよくありません。この命名やtidyverseとの整合性を取るためのパッケージがtidygraph(Pedersen 2024b)です。tidygraphはほぼigraphのwrapper(関数名と引数の形を整えたもの)ですが、igraphをそのまま使うよりは使いやすく、パイプ演算子との相性も悪くありません。
この章ではまずigraphについて説明し、その後にtidygraphとigraphの関数との対応を説明することにします。
パッケージのロード
pacman::p_load(igraph, tidygraph, tidyverse)igraphでは、ネットワーク全体をgraph、ノードをvertex、リンクをedgeと呼びます。それぞれをnetwork、node、linkと呼ぶことは基本的にありません(ただし、一部の関数の引数としてnodeを使っていたりします)。
igraphでグラフ、つまりネットワークの全体図を作成する方法はいくつかあります。
単純なグラフを作成するのであればedge vectorやedge listから、vertexやnodeに特性(attribute)を付けた複雑なグラフを作成するのであればdata.frameを用いるのが比較的簡単だと思います。
まずはベクターから作成する方法を説明します。
ベクターでネットワークを表現する場合には、ベクターに、edgeで繋ぎたいvertex2つをセットで記載します。例えば、c("A", "B")であれば、AとBというvertexをedgeで繋いだグラフとなります。edgeでつなぐvertexは必ず2つセットになりますので、もう一つedgeを設定したい場合には、1つ目のedgeを示す2つのvertexの後に、さらに2つのvertexを記載します。つまり、c("A","B", "A","C")といった形で表現することで、A-B、A-Cのedgeを持つ、A、B、Cのvertexを表現することができます。このようなベクターをigraphではedge vectorと呼びます。
とは言っても、edge vectorはただのベクターですので、このedge vectorからグラフを作成する必要があります。グラフの作成には、make_graph関数を用います。edge vectorをmake_graph関数の引数とすることで、グラフを作成することができます。
edge vectorでは、基本的に1つ目のvertexから2つ目のvertexの方向にedgeを繋ぐ、有向グラフが作成されます。無向グラフを作成する場合には、引数にdirected=FALSEと指定します。
グラフを作成し表示すると、グラフの情報が示されます。このグラフの情報については後ほど説明します。
グラフを描画するには、先ほど作成したグラフをplot関数の引数に取ります。より複雑なグラフの描画方法については後ほど説明します。
edge listはedge vectorと似ており、edgeでつなぐvertexを1、2列目にそれぞれ記載した行列(edge list)を用いてグラフを作成する方法です。下の例では、A→B、B→C、C→Aのそれぞれのedgeを2列の行列で表現しています。edge listからグラフを作成する場合には、graph_from_edgelist関数を用います。make_graph関数と同様に、無向グラフを作成する場合には引数にdirected=FALSEを指定します。
edge vector、edge listを用いないグラフの作成方法として、adjacency matrix(隣接行列)を用いる方法があります。隣接行列は行数と列数が同じ行列(正方行列)で、行名・列名をvertexの名前とした行列です。隣接行列では、行方向に見て0であればedgeなし、1以上であればedgeありとなります。例えば下の例では、Aの行を見ると、A列は0、B列に1、C列に1となっています。これは、AからAはedgeがなく、AからB、AからCへのedgeがあることを示しています。
隣接行列からグラフを作成するための関数がgraph_from_adjacency_matrixです。graph_from_adjacency_matrix関数では、有向グラフ・無向グラフを指定する引数としてdirectedではなく、modeが用いられます。デフォルトはmode="directed"で、有向グラフが作成されます。無向グラフを作成する場合にはmode="undirected"を指定します。
隣接行列には1以上の値を設定することができます。1以上の値を設定した場合には、そのedgeが複数、平行なedgeとして設定されます。ただし、weighted=TRUEとした場合には、edgeの数ではなく、edgeのweightという特性(attribute)の値が指定されることになります。
上の例ではA、B、Cを繋ぐすべてのedgeが両方向になっていますが、片方向にする場合には、例えばA行B列を1、B行A列を0とします。このように設定することで、A→Bのみの有向グラフを作成することができます。また、対角成分(A行A列など)が1以上に設定されている場合には、AからAへのループとなるedgeが設定されます。
adjacency matrixで方向を設定する
グラフの表現として、--や-+などの記号を用いる、literalでもグラフを作成することができます。グラフの表現はそれぞれ以下の通りです。
| literal | graph |
|---|---|
| A – B | A-B(無向グラフ) |
| A -+ B | A→B |
| A +- B | A←B |
| A ++ B | A↔︎B |
| A —-+ B | A→B |
要は、+側が矢印の先になるような記法がliteralです。矢印の反対側は-になります。左端と右端の-、+の間には-を複数挟むこともできます。無向グラフと有向グラフを同じグラフに含めることはできませんので、--を用いた場合にはすべてのedgeを--で表現する必要があります。
このliteralからグラフを作成する関数がgraph_from_literalです。literalは文字列ではなく、そのまま引数として取り、edgeの表現として必要な分だけコンマで繋ぎます。
literalからグラフを作成する
graph_from_literal(
A-+B, B-+C, C-+D, D++A
) |> plot()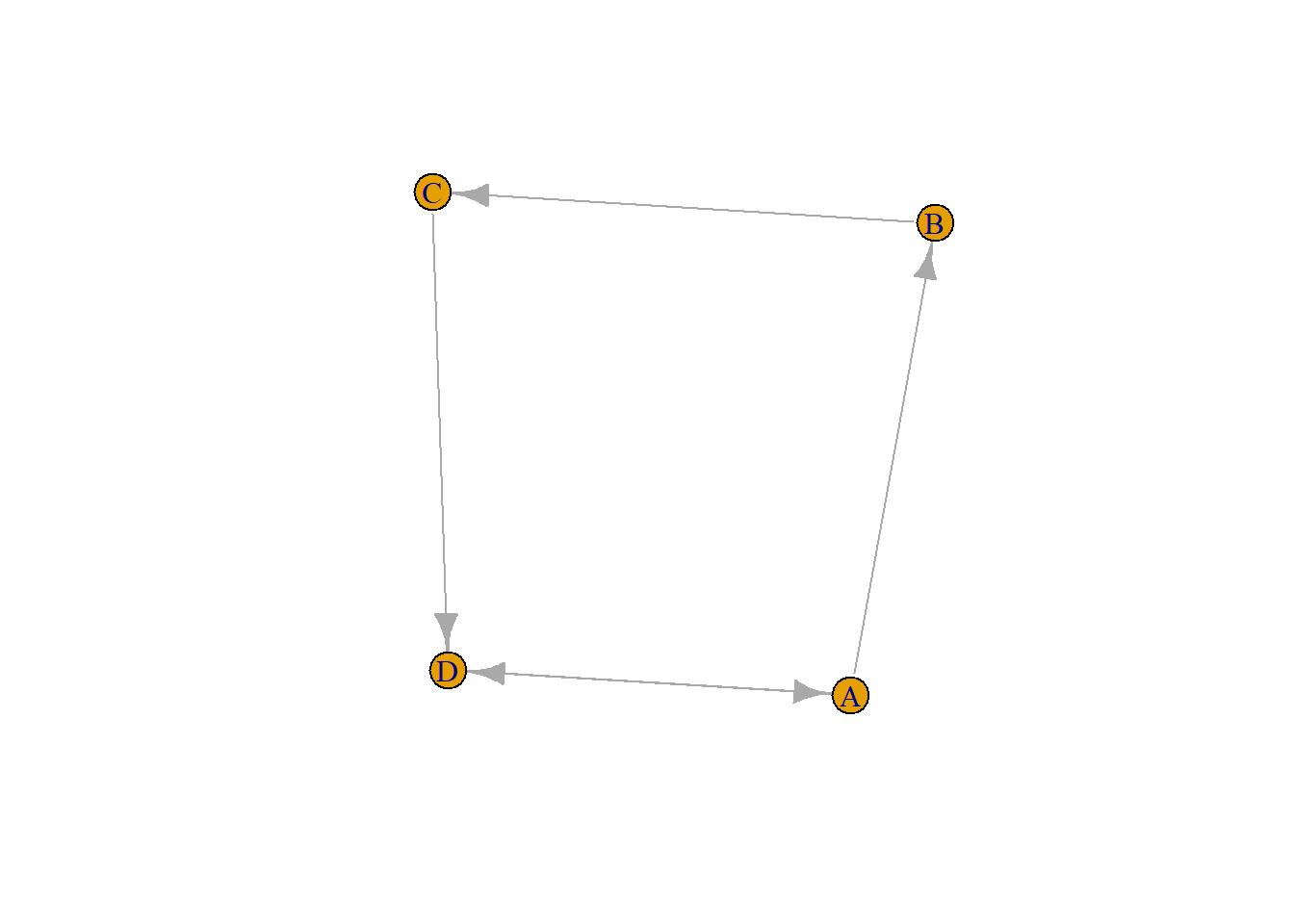
また、このliteralに似た表現を用いてグラフを作成する方法もあります。引数としてベクターではなく、チルダ(~)で始まり、edgeとvertexを表現した―と:から成る式(formula)を用いる方法です。グラフの作成にはedge vectorの際に用いたmake_graphを用います。-がedge、:は複数のvertexへの接続を表します。Rでは:の表現が数列(1:3など)と異なり混乱しやすいので、あまりお勧めできる表記方法ではないように思います。
formulaを用いてグラフを作成する
make_graph(~ A-B, B-C, C-A:D) |> plot() # C-A、C-Dを設定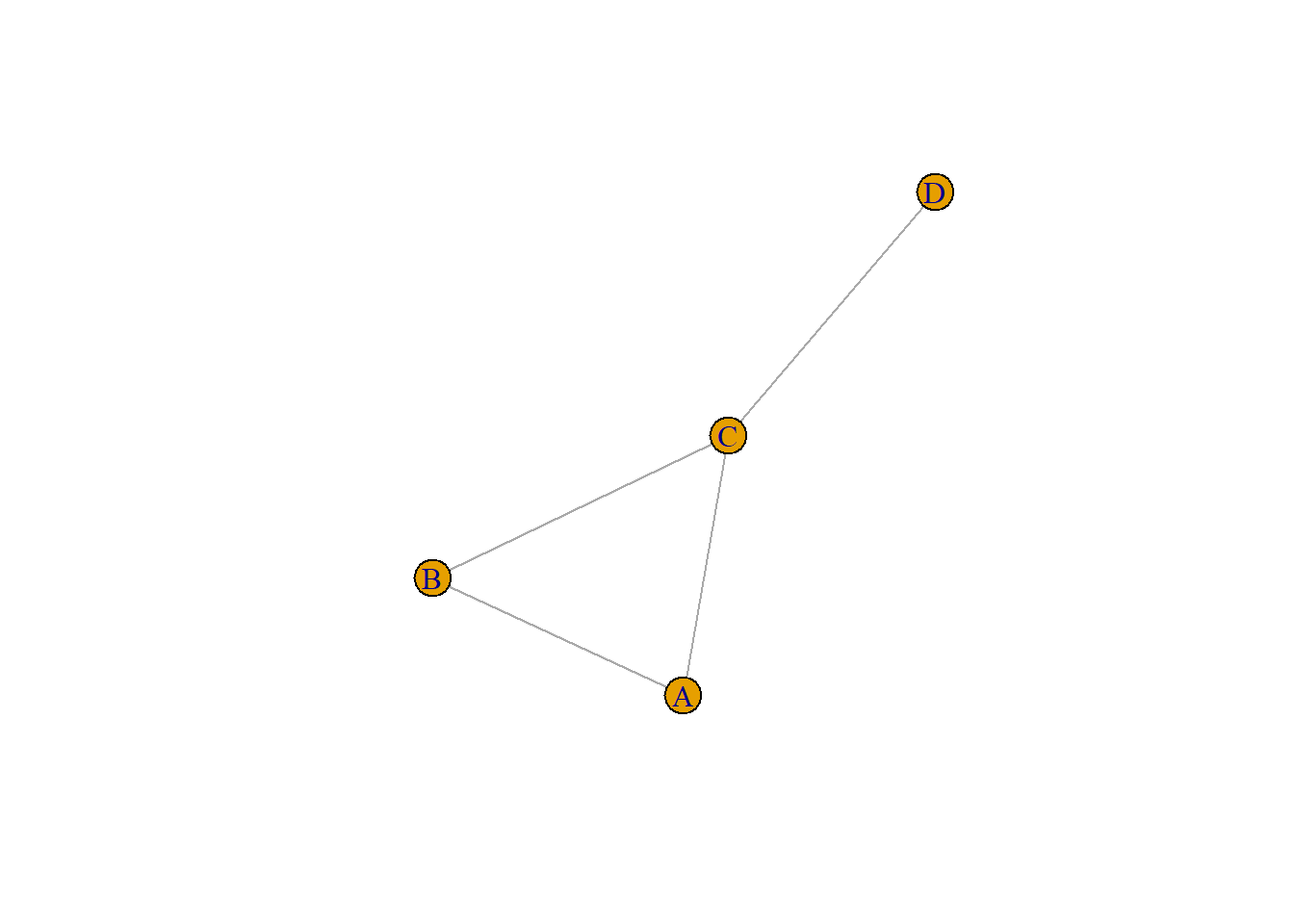
Rで最も頻繁に用いられるデータ型の一つである、データフレームを用いてもグラフを作成することができます。グラフの作成方法はedge listとよく似ていて、1列目と2列目にedgeで接続するvertexを表記したデータフレームを用います。列名はわかりやすいようにそれぞれfromとtoにしておきます。このデータフレームがグラフ作成の基本となります。
データフレームからグラフを作成するための関数がgraph_from_data_frameです。このedgeを設定したデータフレームを引数に取ることで、グラフを作成することができます。
データフレームからグラフを作成する
d_edge <- data.frame(
from = c("A", "B", "C"),
to = c("B", "C", "A")
)
graph_from_data_frame(d_edge)
## IGRAPH b2a203d DN-- 3 3 --
## + attr: name (v/c)
## + edges from b2a203d (vertex names):
## [1] A->B B->C C->Aまた、データフレームを用いると、edgeやvertexに特性(attributes)を持たせたいときに便利です。例えば人間関係であれば、edgeにはメールのやり取りの回数であったり、交友関係の深さを設定することがあります。また、人間関係におけるvertex、つまり人には性別や年齢、所属する組織などを設定したい場合もあるでしょう。データフレームからグラフを作成すると、このような特性を比較的簡単にグラフに持たせることができます。
edgeに特性を持たせたい場合には、上記のfromとtoからなるデータフレームに列を追加します。edgeに設定される主な特性はweightです。上記のメールの数や交友関係の深さなどをweightとして数値で設定します。
同じように、vertexにも特性を持たせることができます。edgeを示したデータフレームとは別に、vertexを表現するためのデータフレームを準備します。このデータフレームの1列目には、edgeのデータフレームに示したvertexをすべて含める必要があります。また、edgeのデータフレームに含まれないvertexを含めることもできます(edgeによる接続のない、独立したvertexが追加されます)。2列目以降には、vertexの特性、例えば人であれば年齢や性別の列を作成しておきます。
この2つのデータフレームを用いて、グラフを作成します。graph_from_data_frameでは、vertices引数にvertexを表現したデータフレームを設定することで、edgeとは別にvertexやその特性を設定することができます。
グラフにAttributesを付与する
# edgeのデータフレームに列を追加する(weightは特性)
d_edge$weight <- c(1, 2, 3)
# vertexのデータフレーム(age、sexは特性)
d_vertex <- data.frame(
name = c("A", "B", "C"),
age = c(20, 25, 30),
sex = c("F", "M", "F")
)
g <- graph_from_data_frame(d_edge, vertices = d_vertex)ここまでで、グラフを作成する方法について述べてきました。作成したグラフはigraphクラスのオブジェクトで、表示させるとedgeの一覧と色々な情報が表示されます。
igraphクラス
class(g)
## [1] "igraph"igraphクラスのオブジェクトを表示する
g
## IGRAPH b2a5157 DNW- 3 3 --
## + attr: name (v/c), age (v/n), sex (v/c), weight (e/n)
## + edges from b2a5157 (vertex names):
## [1] A->B B->C C->Aこの表示のうち、1行目のDNW-という部分はこのグラフの性質を示しています。始めのDはDirected(有向グラフ)の略です。無向グラフの場合にはU(Undirected)と表示されます。
次のNはNamedの略で、vertexに名前(name)の特性(attribute)がついていることを示しています。その次のWはWeightedの略で、edgeにweightが設定されていることを示しています。vertexに名前がついていない場合にはNの位置が-に、edgeにweightが設定されていない場合にはWの位置が―になります。
最後の―は2部グラフ(Bipartite graph)であるかどうかを示しており、2部グラフの場合はB、2部グラフでない場合には―が表示されます。2部グラフについては後ほど説明します。
次の3 3の部分はvertexとedgeの数を示しており、前がvertexの数、後ろがedgeの数になります。
次の行の+ attrは設定されているattributeを示しています。name、sexには(v/c)と表示されています。この(v/c)はvertexのattributeであり、characterであることを示しています。ageは(v/n)、つまりvertexのattributeでnumericであること、weightは(e/n)、edgeのattributeでnumericであることが表示されています。この他にグラフ自体にもattributeを設定することができます。グラフのattributeは(g/c)や(g/n)で示されます。
最後の行はedgeのリストです。この場合は有向グラフであり、A→B、B→C、C→Aの3つのedgeがあることが示されています。
グラフからedgeを取り出す場合にはE関数、vertexを取り出す場合にはV関数をそれぞれ用います。取り出したedgeやvertexにはattributeが付いたままになっています。
vertex・edgeを取り出す
E(g)
## + 3/3 edges from b2a5157 (vertex names):
## [1] A->B B->C C->A
V(g)
## + 3/3 vertices, named, from b2a5157:
## [1] A B C上記のように、グラフにはattributeを設定することができます。attributeを設定することができるのは、graph全体と、edge、vertexの3種類です。それぞれのattributeはgraph_attr、edge_attr、vertex_attr関数でそれぞれリストとして取り出すことができます。
attributesを取り出す
graph_attr(g)
## named list()
edge_attr(g)
## $weight
## [1] 1 2 3
vertex_attr(g)
## $name
## [1] "A" "B" "C"
##
## $age
## [1] 20 25 30
##
## $sex
## [1] "F" "M" "F"他のRの関数と同様に、graph_attr、edge_attr、vertex_attr関数にベクターやリストを代入することで、グラフに後からattributeを設定することもできます。代入によりattributeを設定する場合には、関数の第一引数にグラフ、第二引数にattributeの名前を文字列で設定します。
attributeを設定する
graph_attr(g, "name") <- "ABC"
edge_attr(g, "degree") <- c(3, 4, 5)
vertex_attr(g, "height") <- c(167, 182, 153)
# attributeが増えている
g
## IGRAPH b2a5157 DNW- 3 3 -- ABC
## + attr: name (g/c), name (v/c), age (v/n), sex (v/c), height (v/n),
## | weight (e/n), degree (e/n)
## + edges from b2a5157 (vertex names):
## [1] A->B B->C C->Aattributeの取り出しには、graph_attr、edge_attr、vertex_attr関数だけでなく、上記のE関数、V関数を用いることもできます。E関数、V関数の返り値にはattributeがくっついているので、E関数、V関数の後に$ + attribute名をつけることでattributeをリストのように取り出すことができます。attributeを用いて演算を行う場合(たとえばネットワークをplot関数で表示するときのオプション設定にattributeを用いる場合など)にはE、V関数からのattributeの呼び出しを用いることになります。
edgeのattributeをE関数から呼び出す
# edgeに指定したweightを呼び出し
E(g)$weight
## [1] 1 2 3
# edgeの太さをweightに従い決める
plot(g, edge.width = E(g)$weight)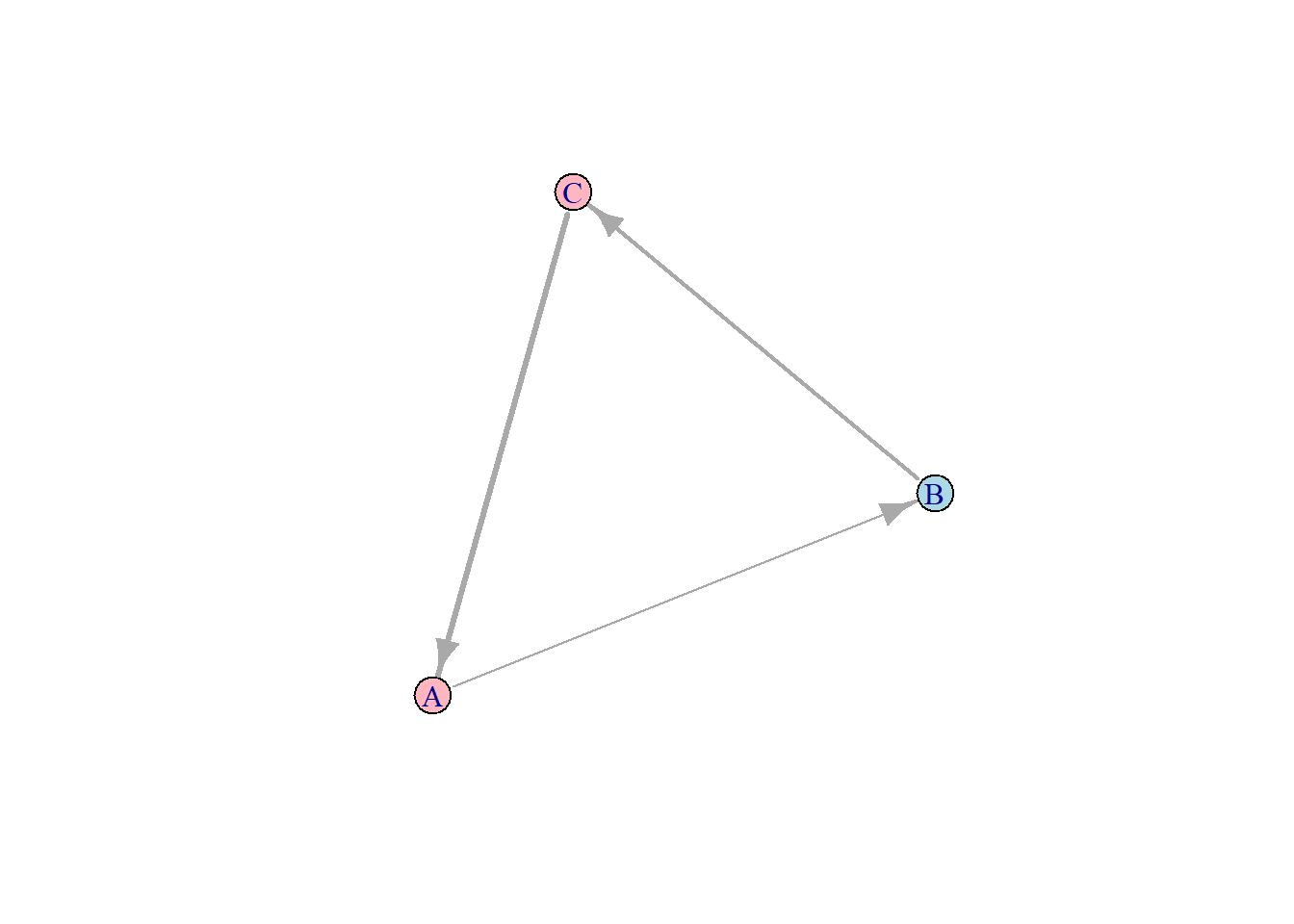
同じように、vertexのattributeもノードの色調整などに用いることができます。
vertexのattributeをV関数から呼び出す
V(g)$sex
## [1] "F" "M" "F"
plot(
g,
edge.width = E(g)$weight,
# 男性のvertexはlightblue、女性のvertexはlightpinkで表示する
vertex.color = if_else(V(g)$sex == "M", "lightblue", "lightpink"))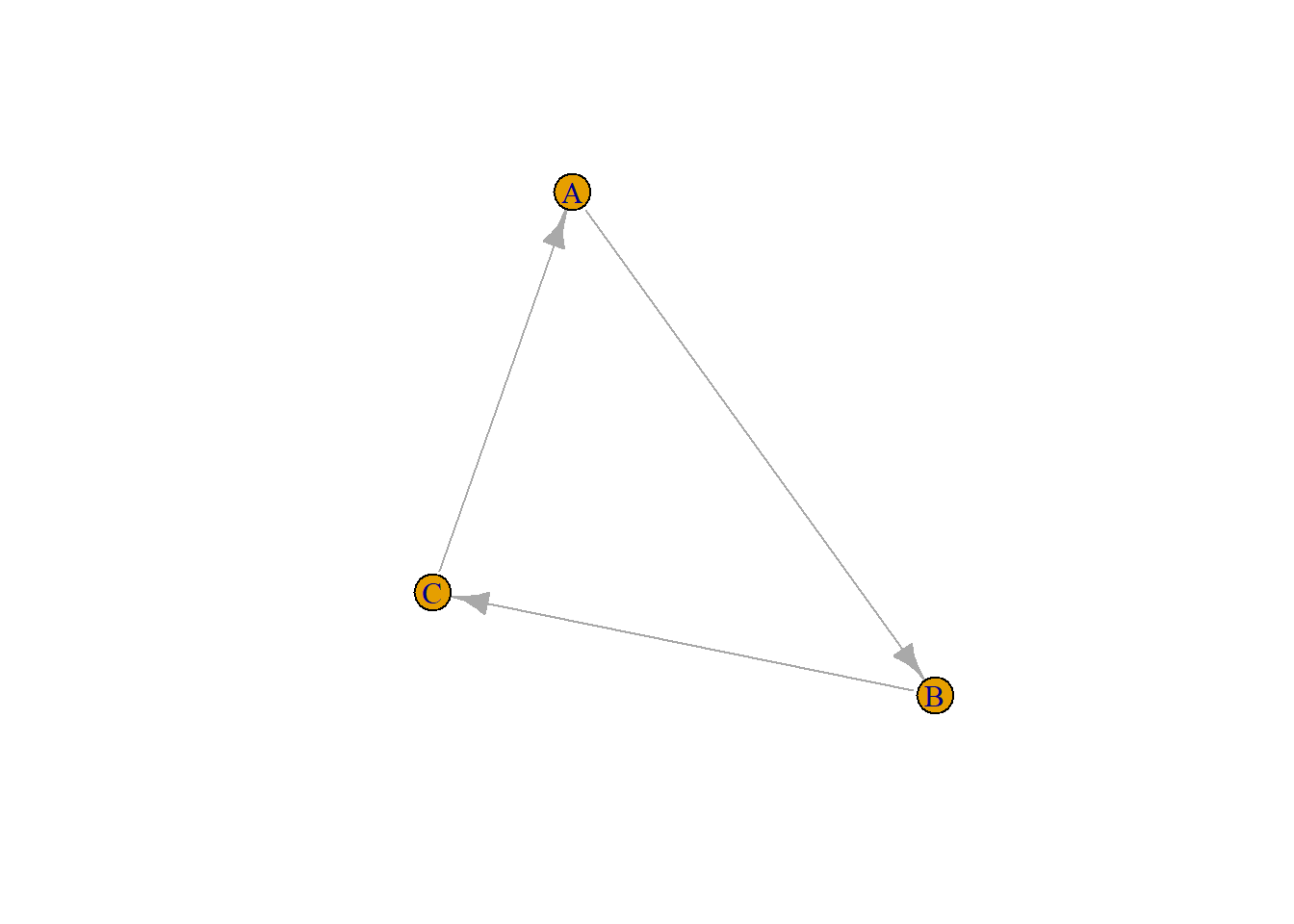
上記の通り、ネットワークを描画する場合には、plot関数の引数にグラフのオブジェクトを取ります。
plot関数でネットワークを表示する
plot(g)
ただし、これだけではedgeやvertexの特性をグラフに反映することはできませんし、場合によっては表示が見にくく、ネットワークの構造をきちんととらえることができないこともあります。
igraphでは、plot関数の引数やlayout(vertexの位置を決める要素)を設定する一連の関数により、ネットワークを自由に描画できるようになっています。以下にplot関数の引数の一覧を示します。
いくつかの引数を指定した例を以下に示します。いろいろ試してみることで自由にネットワークを表示できるようになるでしょう。
ネットワークを表示する際には、上記のような引数による細かな表示の変更の他に、ネットワーク自体の形を大きく変えるlayoutというものを指定することができます。plot関数内のlayout引数にlayoutを指定するための関数を指定することで、ネットワークの見た目を大きく変えることができます。また、layoutを指定するための関数を前もって宣言しておくことでもlayoutを変更することができます。各layout関数にはそれぞれ引数も設定されているので、同じlayout内で見た目を微調整することもできます。
karate <- make_graph("Zachary")
plot(karate, layout=layout_as_star(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_as_tree(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_in_circle(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_nicely(karate)) # plotのデフォルト
karate <- make_graph("Zachary")
plot(karate, layout=layout_on_grid(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_on_sphere(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_randomly(karate))
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_dh(karate)) # Davidson-Harel layout algorithm
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_fr(karate)) # Fruchterman-Reingold layout algorithm
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_gem(karate)) # GEM layout algorithm
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_graphopt(karate)) # graphopt layout algorithm
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_kk(karate)) # Kamada-Kawai layout algorithm
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_lgl(karate)) # Large Graph layout
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_mds(karate)) # multidimensional scaling
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_sugiyama(karate)) # Sugiyama graph layout
karate <- make_graph("Zachary")
plot(karate, layout=layout_with_drl(karate)) # force-directed graph layout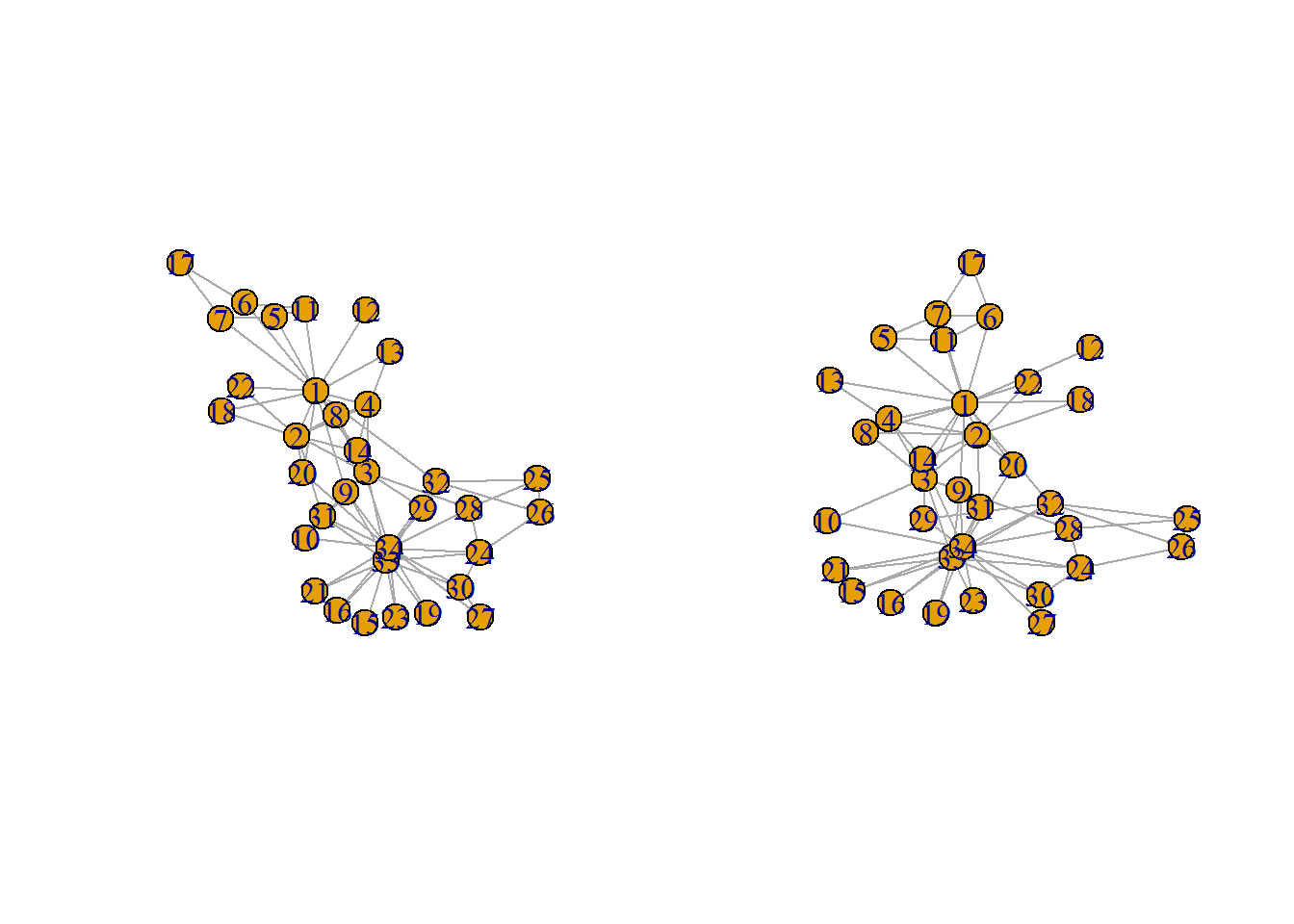
ネットワークをグラフとしてプロットすると、何となくそのネットワークが分かったような気がします。ですので、ネットワーク解析においてプロットすること、ネットワークの表記は非常に重要です。一方で、上記のようにネットワークの表記の方法は様々であり、どのようなネットワークの表記がネットワークの正確な理解につながるのかは難しい問題です。
ネットワークに関する論文 (Jones et al. 2018)では、ネットワークの表記において勘違いしやすい点が4点挙げられています。
上記の4点は表記法により正しかったり間違っていたりするため、必ずしも表示されたネットワークがネットワークの正確な情報を伝えているというわけではありません。ネットワークの描画は乱数依存であるため、例えば下図のように同じグラフを2回表示するだけでも、グラフは同じ形には表記されません。
上記で紹介した論文には、ネットワークの情報を正確に伝えるためのプロットの手法について記載されています。ご一読されるとよいでしょう。
上記のlayoutでは、karate <- make_graph("Zachary")という形でigraphに登録されているネットワークである、"Zachary"を読み込んで利用しています。make_graph関数では、igraphに登録されているネットワーク(Notable graphs)を文字列で指定することで、igraphに保存されているネットワークを呼び出すことができます。
これらのネットワークの中でも有名なものの一つが上記のZachary’s karate clubです。この空手クラブのデータはZachary et al. (1976)(Zachary 1976)で人類学的な解析に用いられたもので、アメリカの大学の空手クラブにおけるメンバー間の交友関係をネットワークとしたものです。この空手クラブ、1番と34番のメンバーを中心とした2つのグループに別れたことで有名で、ネットワークについての教科書などで頻出するデータとなっています。
以下のネットワーク図はメンバーが分離した後の2グループを色で示したものになっています。次に説明する中心性の評価、クラスターの評価にはこのデータを用います。
Zachary`s karate club
karate <- make_graph("Zachary")
# 2つに分離した後のグループ
karate_col <-
c("A", "A", "A", "A", "A",
"A", "A", "A", "A", "B",
"A", "A", "A", "A", "B",
"B", "A", "A", "B", "A",
"B", "A", "B", "B", "B",
"B", "B", "B", "B", "B",
"B", "B", "B", "B")
set.seed(1)
plot(
karate,
vertex.color=
if_else(
karate_col == "A",
"lightblue",
"orange"),
vertex.size = 25)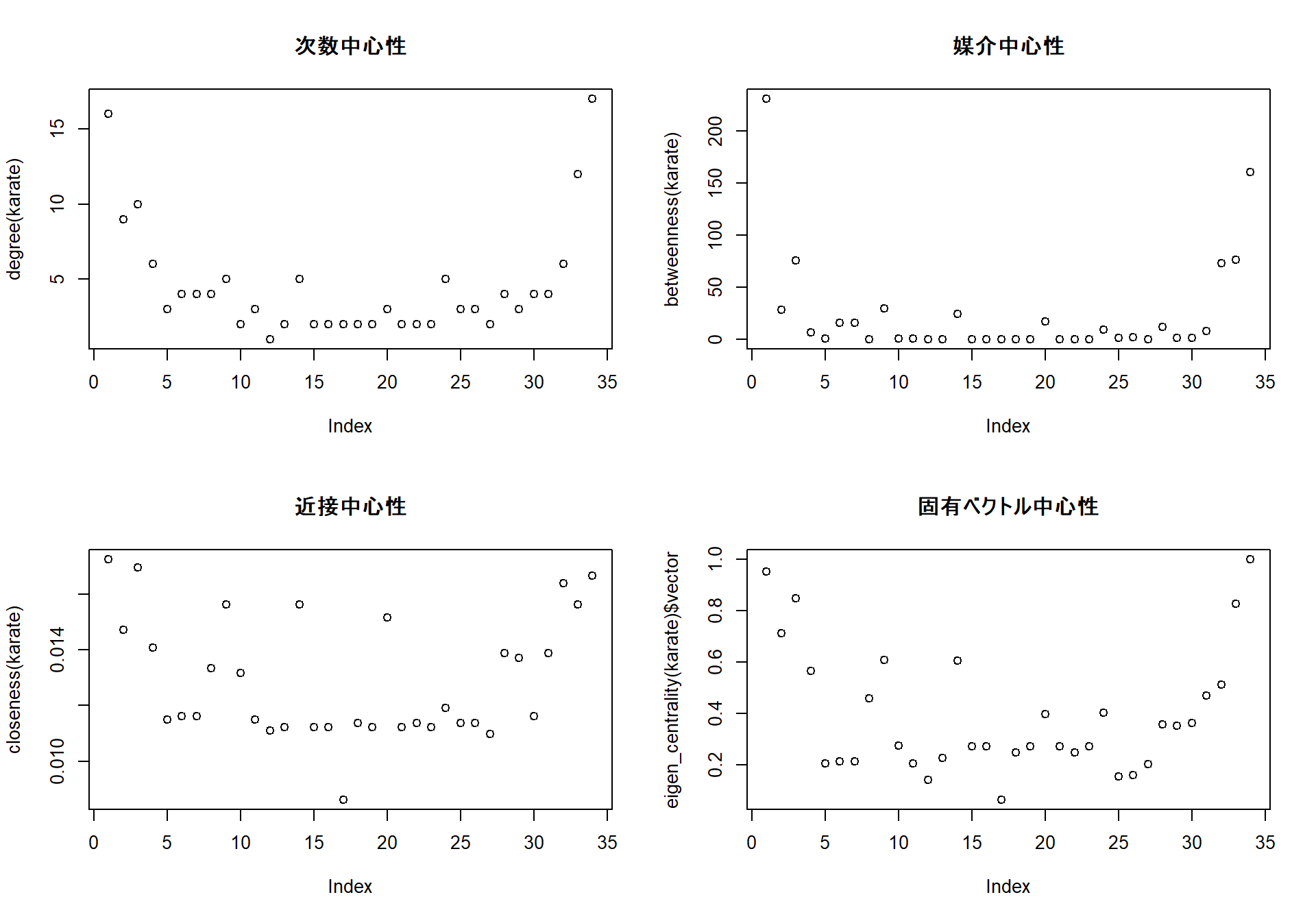
上記の通り、Zachary’s karate clubのネットワークは1と34のメンバーを中心に2つのグループに分離しました。上のネットワーク図を見ると、確かに1と34にはたくさんのedgeが接続しているように見えます。しかし、実際に1と34がネットワークで中心的な役割があるのかと言われると、グラフだけを見ていてもいまいちよくわかりません。
ネットワークで中心的でかつ重要なvertexを抽出するための手法の一つが、中心性(centrality)の評価です。ネットワーク解析でよく用いられる中心性は以下の4種類です。
次数中心性は最も単純な中心性で、そのvertexに接続しているedgeの数を表します。igraphではdegree関数で次数中心性を計算することができます。
媒介中心性はそのvertexが他のvertexの間に存在する頻度を表したものです。igraphではbetweenness関数で媒介中心性を計算することができます。
近接中心性はそのvertexから他のvertexまでの距離の和を反映したもので、igraphではcloseness関数で近接中心性を計算することができます。
固有ベクトル中心性は隣接行列から演算できる中心性の指標です。igraphではeigen_centrality関数で固有ベクトル中心性を計算することができます。
この他にも様々な中心性の指標はありますが、とりあえずこの4つを比較するとある程度は中心的なvertexを特定することができるでしょう。以下はkarate clubのネットワークでのvertexの中心性を評価したものです。いずれの中心性でも、1と34が高い値を示しており、この2人が重要なvertexであったことがわかります。
中心性の演算
# 次数中心性
degree(karate)
## [1] 16 9 10 6 3 4 4 4 5 2 3 1 2 5 2 2 2 2 2 3 2 2 2 5 3
## [26] 3 2 4 3 4 4 6 12 17
# 媒介中心性
betweenness(karate)
## [1] 231.0714286 28.4785714 75.8507937 6.2880952 0.3333333 15.8333333
## [7] 15.8333333 0.0000000 29.5293651 0.4476190 0.3333333 0.0000000
## [13] 0.0000000 24.2158730 0.0000000 0.0000000 0.0000000 0.0000000
## [19] 0.0000000 17.1468254 0.0000000 0.0000000 0.0000000 9.3000000
## [25] 1.1666667 2.0277778 0.0000000 11.7920635 0.9476190 1.5428571
## [31] 7.6095238 73.0095238 76.6904762 160.5515873
# 近接中心性
closeness(karate)
## [1] 0.01724138 0.01470588 0.01694915 0.01408451 0.01149425 0.01162791
## [7] 0.01162791 0.01333333 0.01562500 0.01315789 0.01149425 0.01111111
## [13] 0.01123596 0.01562500 0.01123596 0.01123596 0.00862069 0.01136364
## [19] 0.01123596 0.01515152 0.01123596 0.01136364 0.01123596 0.01190476
## [25] 0.01136364 0.01136364 0.01098901 0.01388889 0.01369863 0.01162791
## [31] 0.01388889 0.01639344 0.01562500 0.01666667
# 固有ベクトル中心性
eigen_centrality(karate)$vector
## [1] 0.95213237 0.71233514 0.84955420 0.56561431 0.20347148 0.21288383
## [7] 0.21288383 0.45789093 0.60906844 0.27499812 0.20347148 0.14156633
## [13] 0.22566382 0.60657439 0.27159396 0.27159396 0.06330461 0.24747879
## [19] 0.27159396 0.39616224 0.27159396 0.24747879 0.27159396 0.40207086
## [25] 0.15280670 0.15857597 0.20242852 0.35749923 0.35107297 0.36147301
## [31] 0.46806481 0.51165649 0.82665886 1.00000000
# それぞれをプロットする
par(mfrow = c(2, 2))
degree(karate) |> plot()
title("次数中心性")
betweenness(karate) |> plot()
title("媒介中心性")
closeness(karate) |> plot()
title("近接中心性")
eigen_centrality(karate)$vector |> plot()
title("固有ベクトル中心性")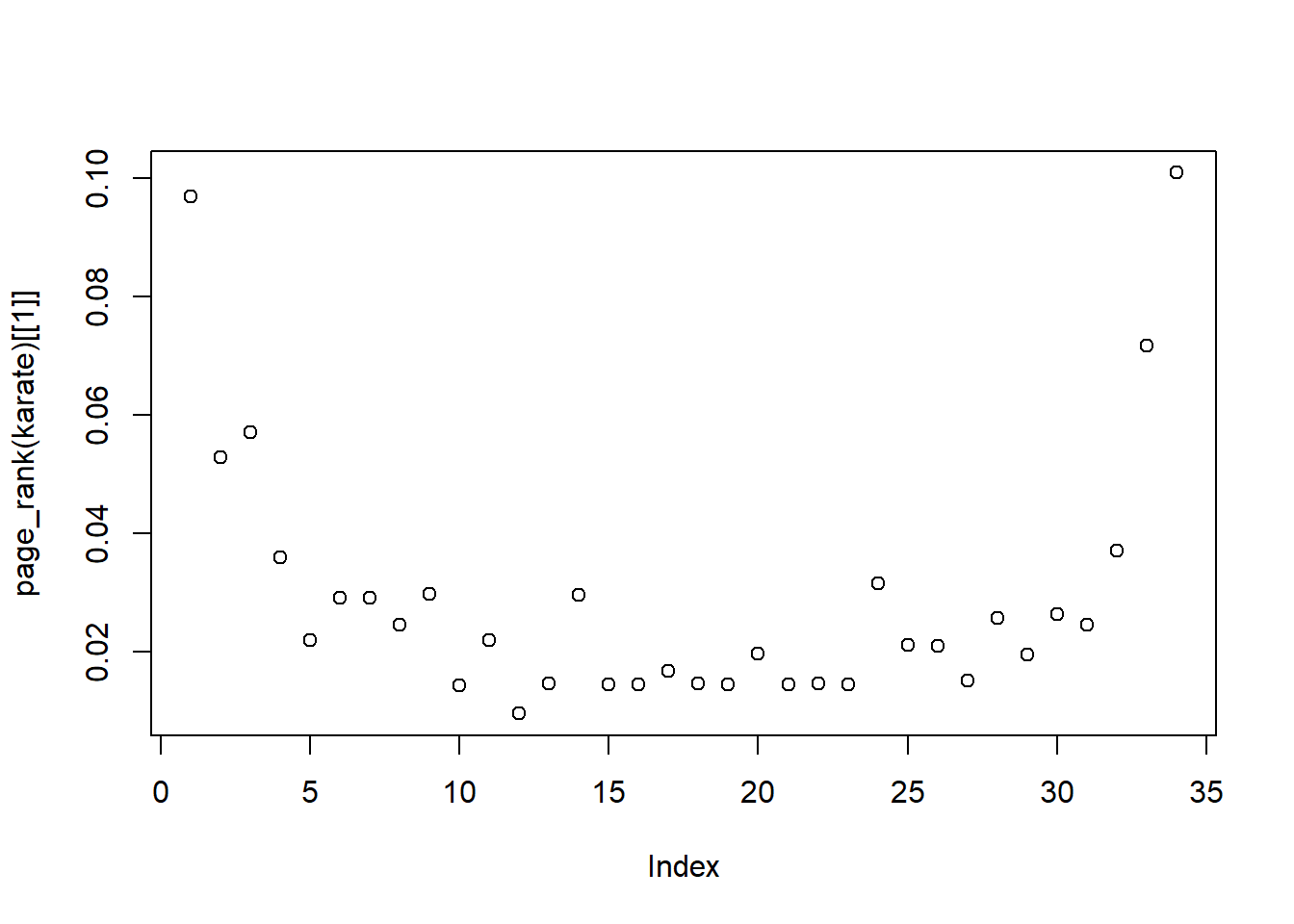
上記の中心性と似た中心性の評価基準として、PageRankがあります。PageRankはGoogleが検索エンジンにおいてホームページの順位付けをするのに用いた評価方法です。igraphではpage_rank関数でPageRankの演算を行うことができます。
PageRankによるvertexの評価
page_rank(karate)[[1]] |> plot()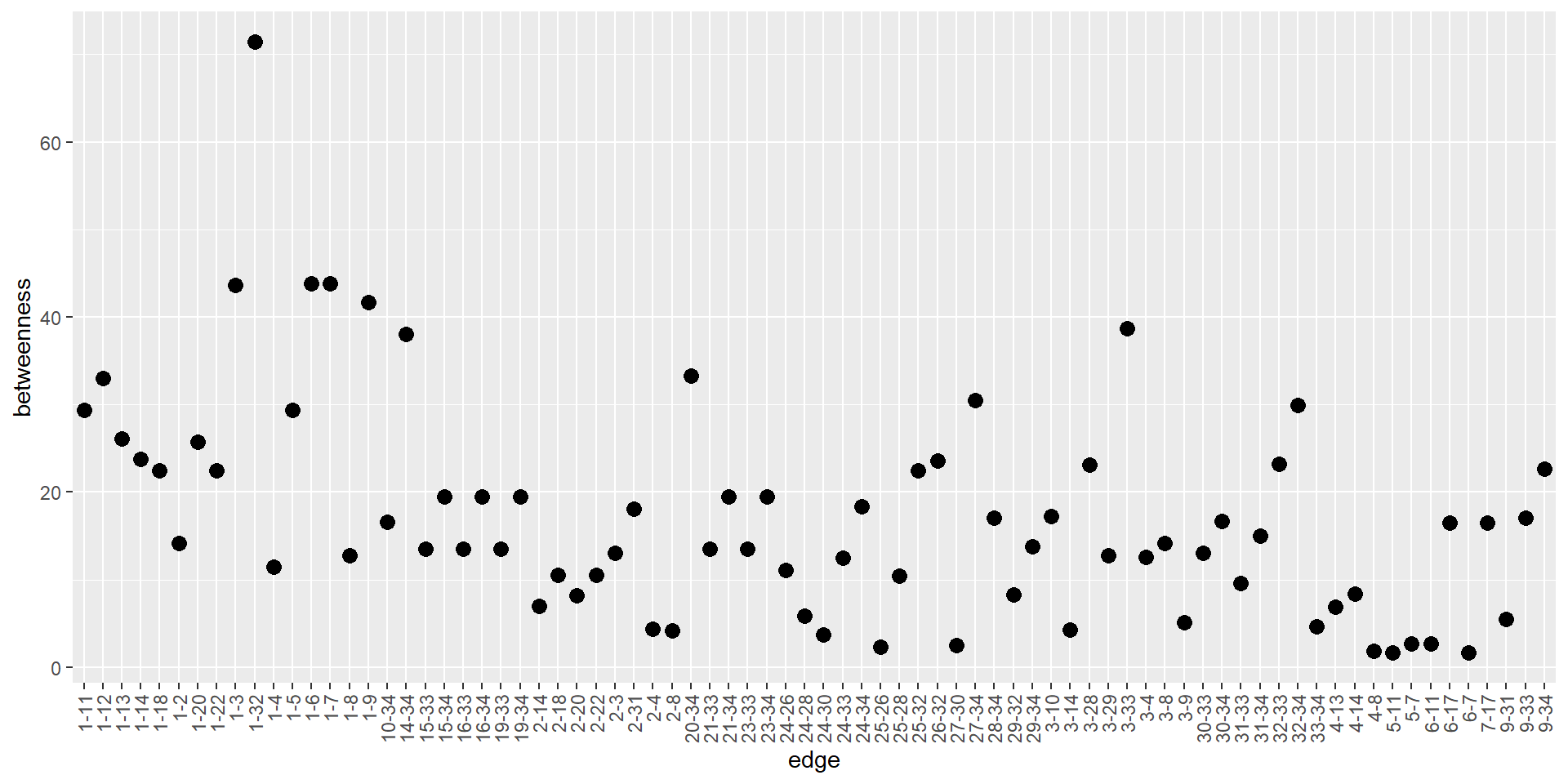
vertexの媒介性ではなく、edgeの媒介性、つまりvertexとvertexの経路の間にあるedgeを評価する方法がedge betweenness(辺の媒介性)です。edge betweennessが高い辺が切れてしまった場合には、ネットワークが大きく分断されることになります。以下の通り、karate clubでは1と32の間のedge betweennessが高く、ココが切れるとネットワークが2つに分離しやすくなります。
edge betweenness
# edge betweennessを演算
edge_betweenness(karate)
## [1] 14.166667 43.638889 11.500000 29.333333 43.833333 43.833333 12.802381
## [8] 41.648413 29.333333 33.000000 26.100000 23.770635 22.509524 25.770635
## [15] 22.509524 71.392857 13.033333 4.333333 4.164286 6.959524 10.490476
## [22] 8.209524 10.490476 18.109524 12.583333 14.145238 23.108730 12.780952
## [29] 38.701587 17.280952 5.147619 4.280952 1.888095 6.900000 8.371429
## [36] 2.666667 1.666667 1.666667 2.666667 16.500000 16.500000 5.500000
## [43] 17.077778 22.684921 16.614286 38.049206 13.511111 19.488889 13.511111
## [50] 19.488889 13.511111 19.488889 33.313492 13.511111 19.488889 13.511111
## [57] 19.488889 11.094444 5.911111 12.533333 18.327778 3.733333 2.366667
## [64] 10.466667 22.500000 23.594444 2.542857 30.457143 17.097619 8.333333
## [71] 13.780952 13.087302 16.722222 9.566667 15.042857 23.244444 29.953968
## [78] 4.614286
edge <- karate |> as_edgelist() |> as.data.frame()
# Edge betweennessをグラフで表示
data.frame(edge , betweenness = edge_betweenness(karate)) |>
mutate(edge = paste0(V1, "-", V2)) |>
ggplot(aes(x = edge, y = betweenness))+
geom_point(size = 3)+
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1))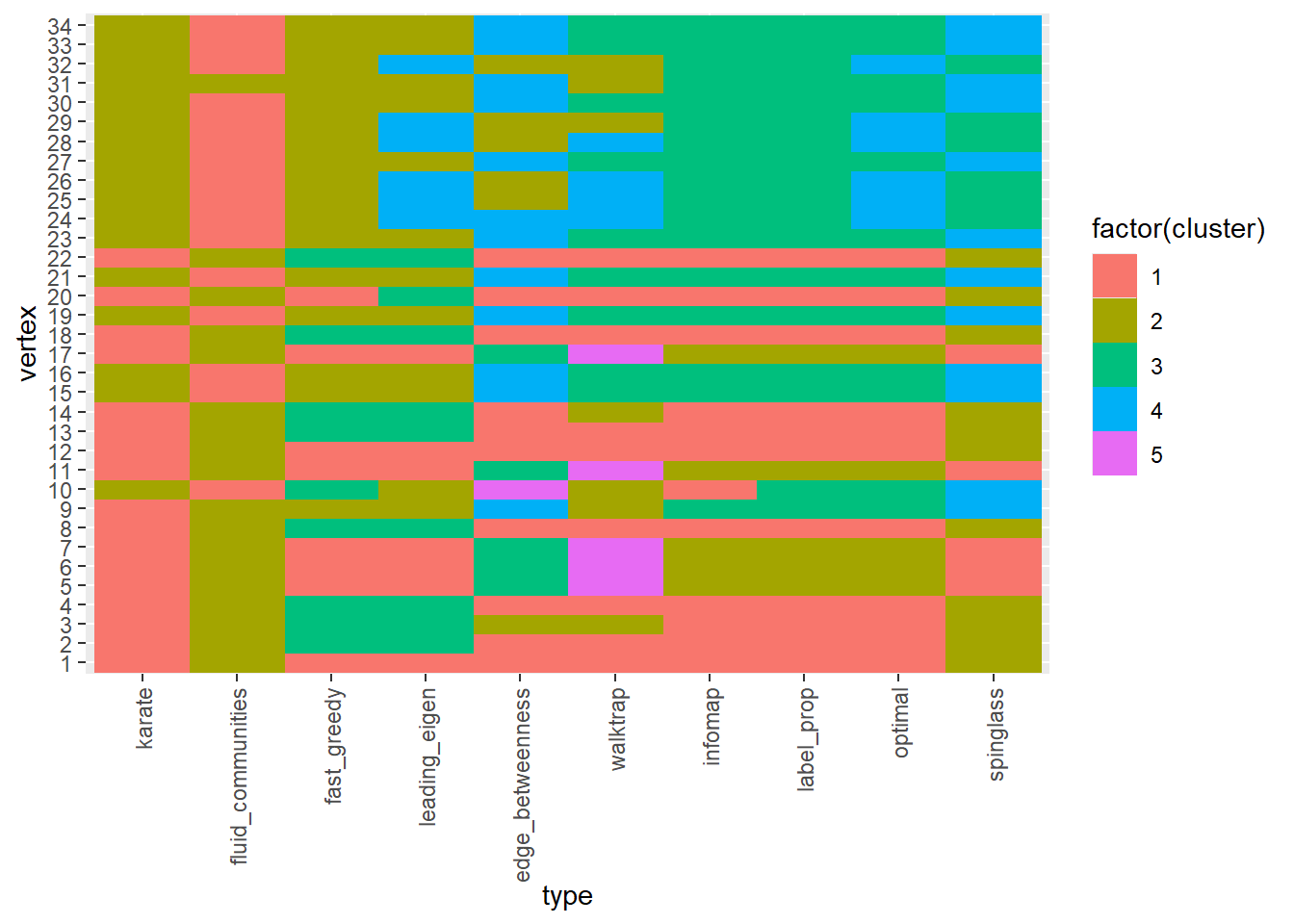
ネットワーク解析の目的の一つは、ネットワーク上のクラスター(コミュニティ)を明らかにすることです。karate clubの例であれば、2つのクラスターが存在することがあらかじめ分かっていれば、グループが割れないように対策することができたかもしれません。
32章で説明したようにクラスター解析には様々な方法があります。同じように、ネットワーク解析におけるクラスター解析にも様々なものがあります。igraphに登録されているクラスター解析だけで10種以上あります。どれがいいのかは時と場合によりますが、いずれもigraphでは名前がcluster_から始まる一連の関数で演算することができます。
以下にigraphが備えているクラスター解析とkarate clubの分離後の2グループを比較したものを示します(一番左のkarateが分離後のグループ)。グラフで左側に示したものほどkarateとの一致度が高くなっています。それぞれの関数には解析方法を調整するための引数が多数準備されているので、うまく調整することでより精度の高いクラスター解析を行うこともできます。したがって、必ずしも以下の例のようにcluster_fluid_communitiesが優れているというわけではありません。時と場合により手法を使い分けるのが良いでしょう。
ネットワークのクラスターの演算
# クラスターを計算
karate_clus <- data.frame(
vertex = as.character(1:34) |> factor(levels=1:34),
karate = if_else(karate_col == "A", 1, 2),
edge_betweenness = cluster_edge_betweenness(karate)$membership,
fast_greedy = cluster_fast_greedy(karate)$membership,
fluid_communities = cluster_fluid_communities(karate, no.of.communities = 2)$membership,
infomap = cluster_infomap(karate)$membership,
label_prop = cluster_label_prop(karate)$membership,
leading_eigen = cluster_leading_eigen(karate)$membership,
optimal = cluster_optimal(karate)$membership,
spinglass = cluster_spinglass(karate)$membership,
walktrap = cluster_walktrap(karate)$membership
)
# 同一クラスターのvertexを同じ色で表示する
karate_clus|>
pivot_longer(2:11, names_to = "type", values_to = "cluster") |>
mutate( # 見やすいように順番を入れ替え
type =
fct_relevel(
type,
c(
"karate",
"fluid_communities",
"fast_greedy",
"leading_eigen",
"edge_betweenness",
"walktrap", "infomap",
"label_prop",
"optimal",
"spinglass"))) |>
ggplot(aes(x = type, y = vertex, color = factor(cluster), fill = factor(cluster))) +
geom_tile()+
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1))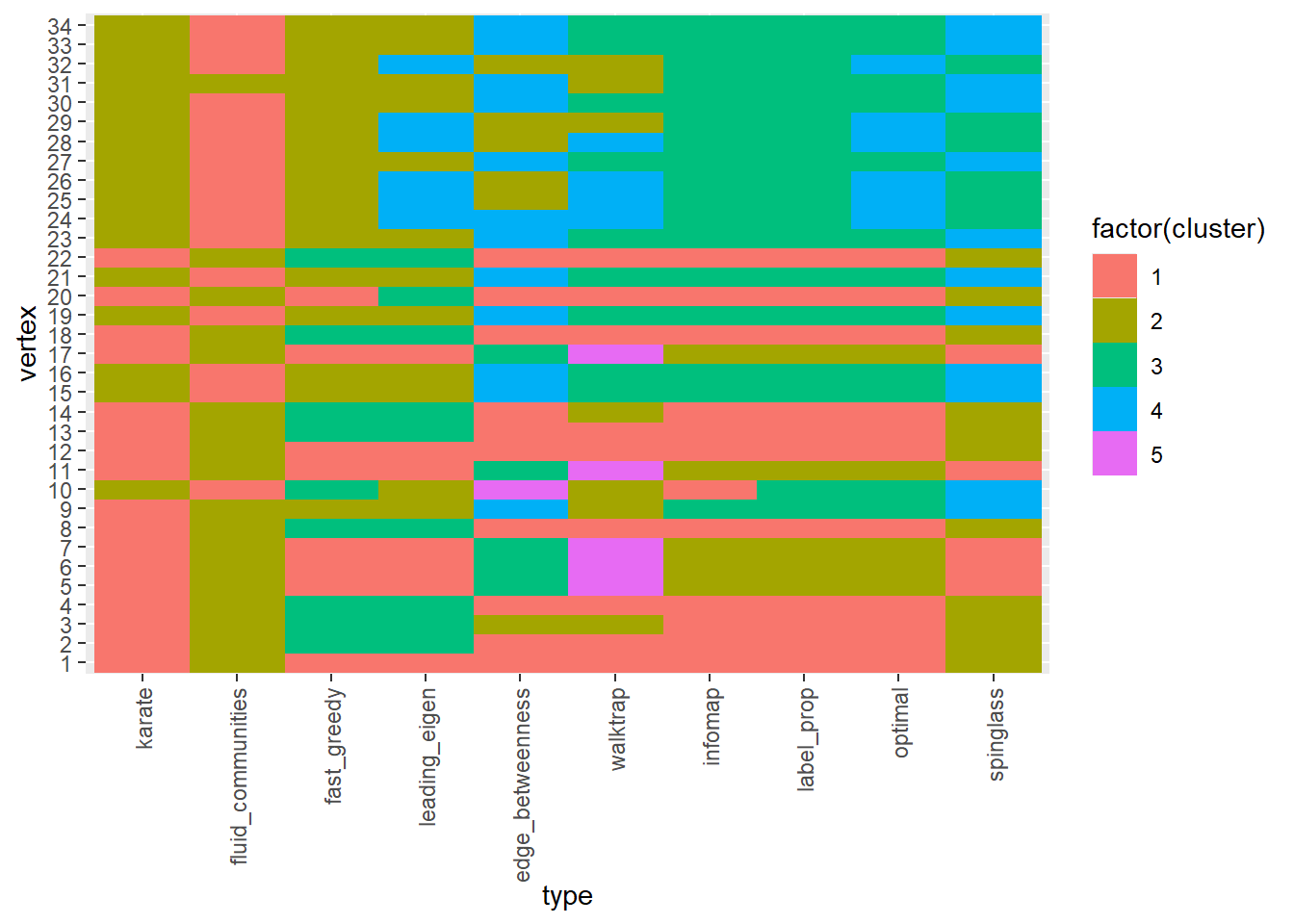
類似の解析方法として、クリーク(cliques、小集団)という、サブグループを見つけるための解析方法もあります。こちらはすべてのvertexをクラスターに所属させるようなものではなく、内部に存在する小集団(例えば、会社の一部署のメンバーなど)を求める手法となっています。clique_num関数はクリークに含まれる最大のvertex数を返す関数です。このclique_numの返り値をcliques関数のmin引数に取ることで、クリークを比較的簡単に見つけることができます。下の例では、5人のクリークを2つ検出しています。
クリーク(clique)の演算
clique_num(karate)
## [1] 5
cliques(karate, min = 5)
## [[1]]
## + 5/34 vertices, from b3d7bc0:
## [1] 1 2 3 4 14
##
## [[2]]
## + 5/34 vertices, from b3d7bc0:
## [1] 1 2 3 4 8ネットワーク解析では、ネットワーク全体を評価することもあります。代表的な特徴として、ネットワークの密度(edge density)があります。密度とは、現在のedgeの数の、そのvertex数で実現可能な最大のedgeの数に対する割合を指します。karateの例では、edgeの数は78ですが、34人のネットワークですべての人がedgeでつながっている場合、つまりedgeの最大数はsum(33:1)、つまり561となります。この78と561の比、78/561がedge densityとなります。
igraphではedge densityをedge_density関数で演算することができます。
edgeの密度(edge density)
edge_density(karate) # edgeの密度
## [1] 0.1390374
E(karate) # 78 edge
## + 78/78 edges from b3d7bc0:
## [1] 1-- 2 1-- 3 1-- 4 1-- 5 1-- 6 1-- 7 1-- 8 1-- 9 1--11 1--12
## [11] 1--13 1--14 1--18 1--20 1--22 1--32 2-- 3 2-- 4 2-- 8 2--14
## [21] 2--18 2--20 2--22 2--31 3-- 4 3-- 8 3--28 3--29 3--33 3--10
## [31] 3-- 9 3--14 4-- 8 4--13 4--14 5-- 7 5--11 6-- 7 6--11 6--17
## [41] 7--17 9--31 9--33 9--34 10--34 14--34 15--33 15--34 16--33 16--34
## [51] 19--33 19--34 20--34 21--33 21--34 23--33 23--34 24--26 24--28 24--33
## [61] 24--34 24--30 25--26 25--28 25--32 26--32 27--30 27--34 28--34 29--32
## [71] 29--34 30--33 30--34 31--33 31--34 32--33 32--34 33--34
E(make_full_graph(n=34)) # full graph(すべてのvertexがedgeでつながっている場合):561 edge
## + 561/561 edges from b4ab94d:
## [1] 1-- 2 1-- 3 1-- 4 1-- 5 1-- 6 1-- 7 1-- 8 1-- 9 1--10 1--11 1--12 1--13
## [13] 1--14 1--15 1--16 1--17 1--18 1--19 1--20 1--21 1--22 1--23 1--24 1--25
## [25] 1--26 1--27 1--28 1--29 1--30 1--31 1--32 1--33 1--34 2-- 3 2-- 4 2-- 5
## [37] 2-- 6 2-- 7 2-- 8 2-- 9 2--10 2--11 2--12 2--13 2--14 2--15 2--16 2--17
## [49] 2--18 2--19 2--20 2--21 2--22 2--23 2--24 2--25 2--26 2--27 2--28 2--29
## [61] 2--30 2--31 2--32 2--33 2--34 3-- 4 3-- 5 3-- 6 3-- 7 3-- 8 3-- 9 3--10
## [73] 3--11 3--12 3--13 3--14 3--15 3--16 3--17 3--18 3--19 3--20 3--21 3--22
## [85] 3--23 3--24 3--25 3--26 3--27 3--28 3--29 3--30 3--31 3--32 3--33 3--34
## [97] 4-- 5 4-- 6 4-- 7 4-- 8 4-- 9 4--10 4--11 4--12 4--13 4--14 4--15 4--16
## [109] 4--17 4--18 4--19 4--20 4--21 4--22 4--23 4--24 4--25 4--26 4--27 4--28
## + ... omitted several edges
78 / 561 # edge_densityの結果と同じ
## [1] 0.1390374次数(degree)、つまりそれぞれのvertexから出ているedgeの数もネットワークの構造を反映するパラメータとなります。次数をヒストグラムとして表示すれば、edgeの分布やその偏りを図示することができます。igraphでは、degree_distribution関数で次数の頻度を計算することができます。また、この関数の返り値をhist関数の引数とすることで、次数のヒストグラムを表示することができます。
次数の分布
degree_distribution(karate) |> hist() # 次数の分布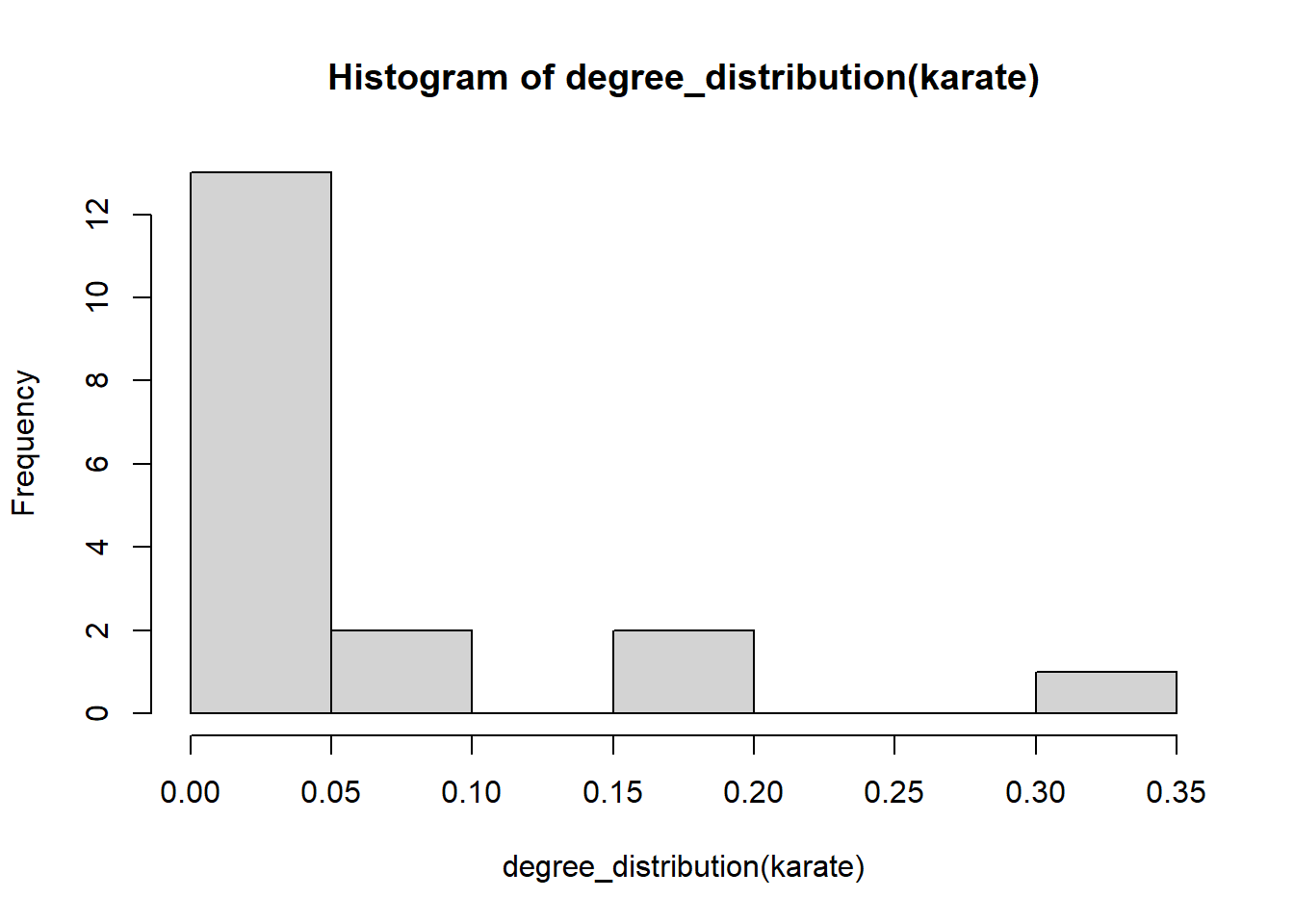
上記のedgeの密度や次数の分布に加えて、vertex間の平均距離や距離の分布、ネットワークの直径もネットワークの性質を表すパラメータとして用いられています。vertex間の距離の分布はdistance_table関数で、ネットワークの直径はgirth関数で計算することができます。
mean_distance(karate) # vertex間の平均距離
## [1] 2.4082
distance_table(karate) # vertex間の距離の要約
## $res
## [1] 78 265 137 73 8
##
## $unconnected
## [1] 0
girth(karate) # ネットワークの直径
## $girth
## [1] 3
##
## $circle
## + 3/34 vertices, from b3d7bc0:
## [1] 2 1 3ネットワーク解析では、上記のような中心性やクラスター以外に、vertexからvertexまでの経路を探索することも目的となります。karate clubでは経路を調べる意味はあまりありませんが、例えば鉄道の路線図や飛行機の航路であれば、最短経路や複数の経路を求める必要があるでしょう。
経路の探索の例として、路線図のデータを利用します。以下は奈良の鉄道(近鉄・JR)の路線のネットワーク(路線図)です。この路線図を利用して経路の探索を説明します。
奈良の路線図
# 駅同士の接続(d)と駅(vt)のデータを読み込む
d <- read.csv("./data/chapter33_nara_stations.csv")
vt <- read.csv("./data/chapter33_nara_stations_vertex_list.csv")
# dとvtからネットワークを作成
nara_stations <- graph_from_data_frame(d, vertices = vt, directed = FALSE)
# ネットワークの表示
nara_stations
## IGRAPH b4bb152 UN-- 119 120 --
## + attr: name (v/c), lat (v/n), lon (v/n), linename (v/c), company
## | (v/c), linename (e/c), company (e/c)
## + edges from b4bb152 (vertex names):
## [1] 奈良 --京終 京終 --帯解 帯解 --櫟本 櫟本 --天理
## [5] 天理 --長柄 長柄 --柳本 柳本 --巻向 巻向 --三輪
## [9] 三輪 --桜井 桜井 --香久山 香久山 --畝傍 金橋 --高田
## [13] 王寺 --畠田 畠田 --志都美 志都美 --香芝 香芝 --JR五位堂
## [17] JR五位堂--高田 高田 --大和新庄 大和新庄--御所 御所 --玉手
## [21] 玉手 --掖上 掖上 --吉野口 吉野口 --北宇智 北宇智 --五条
## [25] 五条 --大和二見 王寺 --三郷 王寺 --法隆寺 法隆寺 --大和小泉
## + ... omitted several edges
# ネットワークを図にする
plot(
nara_stations,
curved = TRUE,
layout = cbind(V(nara_stations)$lon, V(nara_stations)$lat),
vertex.label = NA,
vertex.size = 4)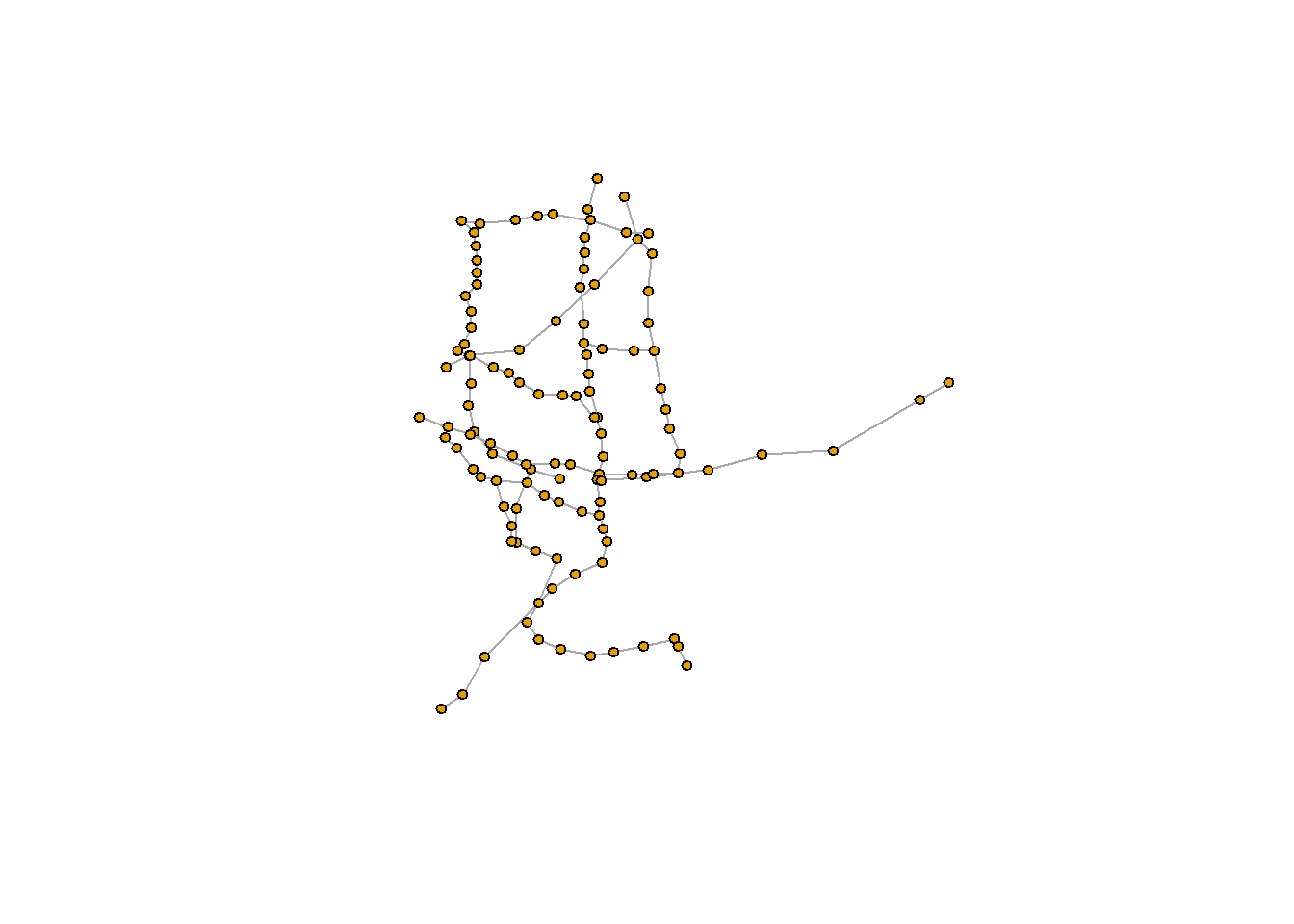
vertex間の距離は行列の形で、distances関数を用いることで求めることができます。到達可能性が無いvertexとの間の距離は無限大(Inf)となります。distances関数には到着点(to引数)を設定することができます。
奈良の鉄道路線の例であれば、田原本線は独立線になっている(王寺-新王寺、西田原本-田原本間は路線としては接続しておらず、別の駅)ので、奈良へは到達不可能(Inf)になっています。
vertex間の距離を調べる
distances(nara_stations)[1:5, 1:5]
## 奈良 京終 帯解 櫟本 天理
## 奈良 0 1 2 3 4
## 京終 1 0 1 2 3
## 帯解 2 1 0 1 2
## 櫟本 3 2 1 0 1
## 天理 4 3 2 1 0
distances(nara_stations, to="奈良")[40:50,]
## 信貴山下 新王寺 大輪田 佐味田川 池部 箸尾 但馬
## 5 Inf Inf Inf Inf Inf Inf
## 黒田 高の原 平城 大和西大寺
## Inf 15 14 13最短距離の探索には、shortest_paths関数、all_shortest_paths関数を用います。shortest_paths関数は最短距離を1つだけ、all_shortest_paths関数はすべての最短距離を返します。路線ではなかなか最短距離が複数存在する場合はありませんので、下の例ではall_shortest_pathsは一つの経路を返しています。
最短距離の探索
shortest_paths(nara_stations, from = "奈良", to = "吉野口")
## $vpath
## $vpath[[1]]
## + 15/119 vertices, named, from b4bb152:
## [1] 奈良 郡山 大和小泉 法隆寺 王寺 畠田 志都美 香芝
## [9] JR五位堂 高田 大和新庄 御所 玉手 掖上 吉野口
##
##
## $epath
## NULL
##
## $predecessors
## NULL
##
## $inbound_edges
## NULL
all_shortest_paths(nara_stations, from = "桜井", to = "吉野口")
## $vpaths
## $vpaths[[1]]
## + 13/119 vertices, named, from b4bb152:
## [1] 桜井 大福 耳成 大和八木 八木西口 畝傍御陵前
## [7] 橿原神宮前 岡寺 飛鳥 壺阪山 市尾 葛
## [13] 吉野口
##
##
## $epaths
## $epaths[[1]]
## + 12/120 edges from b4bb152 (vertex names):
## [1] 桜井 --大福 耳成 --大福 大和八木 --耳成
## [4] 大和八木 --八木西口 八木西口 --畝傍御陵前 畝傍御陵前--橿原神宮前
## [7] 橿原神宮前--岡寺 岡寺 --飛鳥 飛鳥 --壺阪山
## [10] 壺阪山 --市尾 市尾 --葛 吉野口 --葛
##
##
## $nrgeo
## [1] 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 0
## [38] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 2 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1
## [75] 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [112] 1 0 1 0 0 0 0 1
##
## $res
## $res[[1]]
## + 13/119 vertices, named, from b4bb152:
## [1] 桜井 大福 耳成 大和八木 八木西口 畝傍御陵前
## [7] 橿原神宮前 岡寺 飛鳥 壺阪山 市尾 葛
## [13] 吉野口距離行列・最短距離の探索には、幅優先探索(breadth-first search)や深さ優先探索(depth-first search)などのアルゴリズムが用いられています。また、edgeの特性にweightを設定していた場合には、weightを考慮した評価を行うこともできます。
ネットワーク解析には、上記に示した解析方法に加えて、ランダムなグラフの作成、グラフの類似性や検定を用いたネットワーク解析などがあります。
igraphではランダムなグラフの作成には関数名がsample_から始まる一連の関数が、一定の構造を持つグラフの作成にはmake_ringやmake_star関数などの関数が備わっています。ランダムなグラフの作成では、それぞれの関数に設定されたアルゴリズムに従いネットワークが作成されます。また、make_関数でのグラフ作成では、一定の構造を持つグラフが作成されるため、グラフ作成時の基礎構造を準備するのに便利です。
ランダム・一定の構造を持つグラフの作成
g <- sample_tree(n = 30) # ランダムな木構造型ネットワークを作成
plot(g, layout=layout_as_tree(g))
とは言ってもigraphに登録されているsample_関数だけでも10種以上あり、それぞれのアルゴリズムも複雑です。また、グラフの類似性や検定を用いたネットワーク解析に関してはigraphのみでは対応できず、別のパッケージ(statnet、sna)が必要となります。上記のネットワーク解析に関しても詳細な説明は加えていませんので、詳細を理解したい方は教科書(Rで学ぶデータサイエンス ネットワーク分析(鈴木 2017))を一読されることをおすすめいたします。
以下にsample_とmake_関数の一覧を示します。
# ランダムな2部グラフを作成する
sample_bipartite(10, 10, p = 0.3) |> plot(layout = layout_as_bipartite) # pはedgeの頻度
## Warning: `sample_bipartite()` was deprecated in igraph 2.2.0.
## ℹ Please use `sample_bipartite_gnp()` instead.
gr <- sample_gnp(20, p = 0.3) # Erdos-Renyi modelに従い作成(20はvertex数、pはedgeの頻度)
gr |> plot() 
gr |> sample_correlated_gnp(corr = 0.2) |> plot() # edgeをランダムに付け加え・取り除く
sample_fitness_pl(10, 15, exponent.out = 2.5) |> plot() # vertexの数、edgeの数、degreeの分布を指定する引数
sample_gnm(10, 15) |> plot() # vertexの数、nodeの数を指定
sample_grg(10, 0.85) |> plot() # vertexの数、radiusを指定
sample_growing(10, m = 3) |> plot() # vertexの数、ランダムに追加するedgeの数
sample_islands(5, 3, 0.3, 5) |> plot() # gnpでのvertex3つのグラフを5つつないだもの
sample_k_regular(10, 3) |> plot()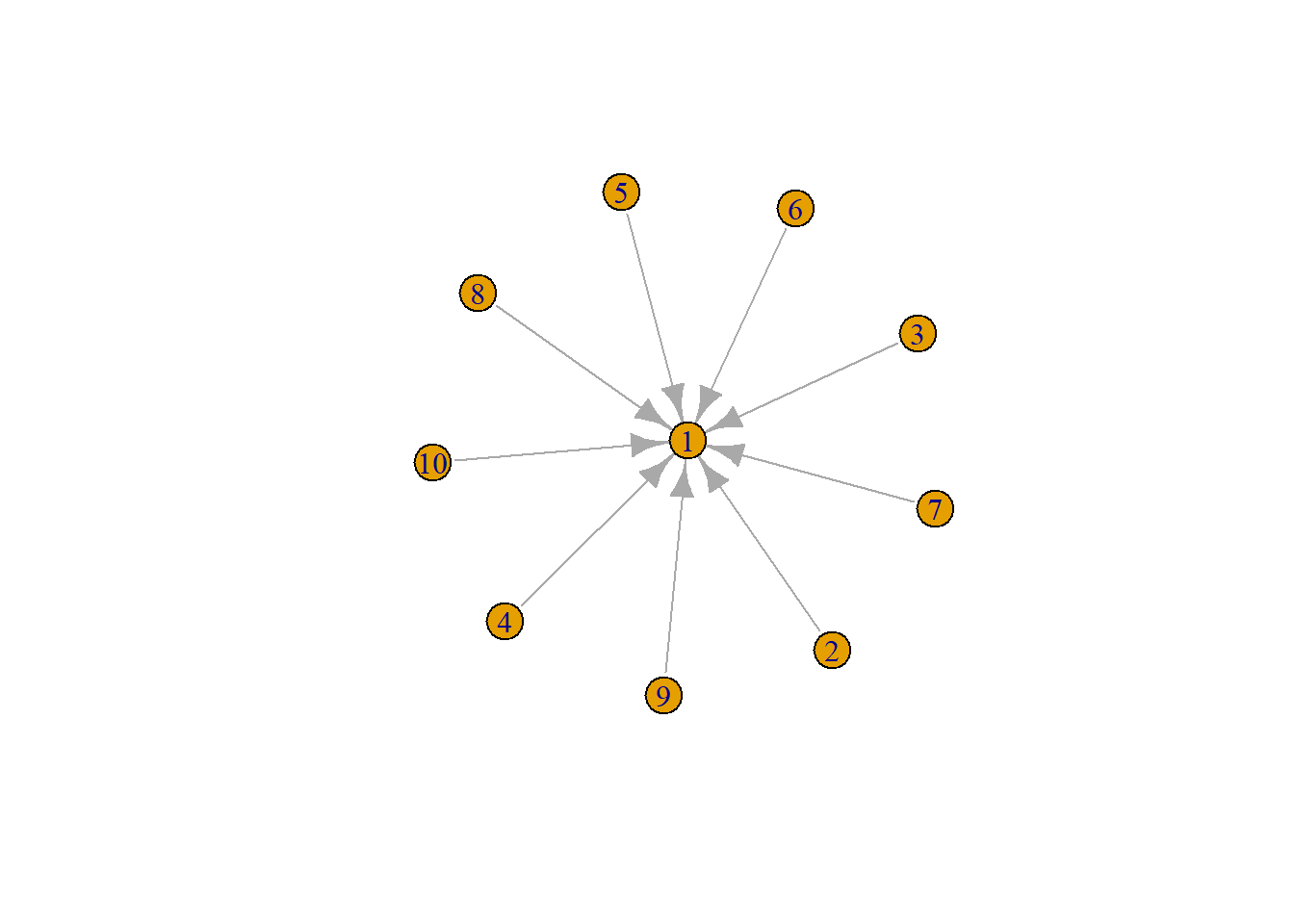
sample_last_cit(10, agebins = 5) |> plot()
sample_pa(10) |> plot()
sample_pa_age(10, 3, -0.5) |> plot()
sample_pref(30, 10) |> plot()
sample_smallworld(dim = 2, size = 5, nei = 1, p = 0.2) |> plot()
sample_traits_callaway(10, types = 3, edge.per.step = 3) |> _$graph |> plot()
g_tree <- sample_tree(20)
g_tree |> plot(layout = layout_as_tree(g_tree))
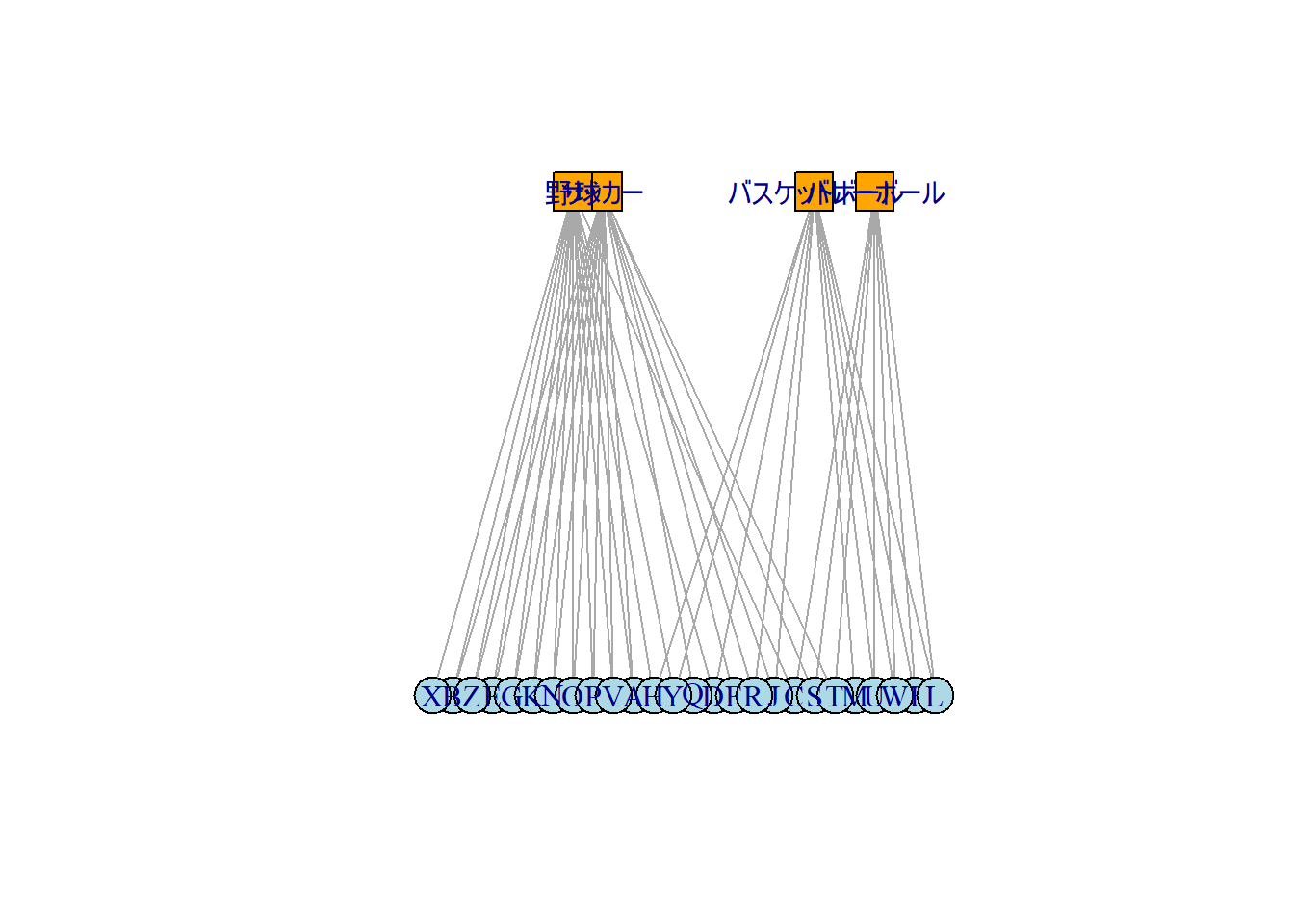
2部グラフ(Bipartite graph)とは、vertexが2つのタイプからなるグラフのことです。この2つのタイプとは、例えば人物と所属するクラブのような、互いに関係性はあるけれども同じタイプ同士のvertex間のつながりは無視できるようなものになります。
以下に2部グラフの例を示します。2部グラフを作成する場合、専用の関数(make_bipartite_graph)がありますが、この関数を用いるよりはedge listやdata.frameからグラフを作成した後、vertexのtypeというattributeに論理型で2部のどちらであるか(上の例では人物をTRUE、所属するクラブをFALSEで指定)を指定する方が作成しやすいと思います。
2部グラフ
set.seed(0)
# edgeを示したデータフレームを作成する
d_edge <- data.frame(
club = sample(c("野球", "サッカー", "バスケットボール", "バレーボール"), 52, replace = TRUE),
person = c(LETTERS, LETTERS)
) |> distinct()
# データフレームから2部グラフを作成する
g <- graph_from_data_frame(d_edge, directed = F)
# typeのattributeを追加する(TRUE、FALSEで2部のどちらであるかを指定する)
V(g)$type <- V(g)$name %in% d_edge[,2]
V(g)$type
## [1] FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [25] TRUE TRUE TRUE TRUE TRUE TRUE
# 2部グラフ(UN-B、BがBipartiteの意味)になっている
g
## IGRAPH b5f228c UN-B 30 48 --
## + attr: name (v/c), type (v/l)
## + edges from b5f228c (vertex names):
## [1] サッカー --A 野球 --B バレーボール --C
## [4] バスケットボール--D 野球 --E サッカー --F
## [7] 野球 --G バスケットボール--H バスケットボール--I
## [10] サッカー --J サッカー --K バスケットボール--L
## [13] バスケットボール--M 野球 --N 野球 --O
## [16] 野球 --P サッカー --Q サッカー --R
## [19] サッカー --S サッカー --T バスケットボール--U
## [22] 野球 --V バスケットボール--W 野球 --X
## + ... omitted several edges
g |> plot(layout = layout_as_bipartite, vertex.color = c("orange", "lightblue")[V(g)$type + 1], vertex.shape = c("square", "circle")[V(g)$type + 1])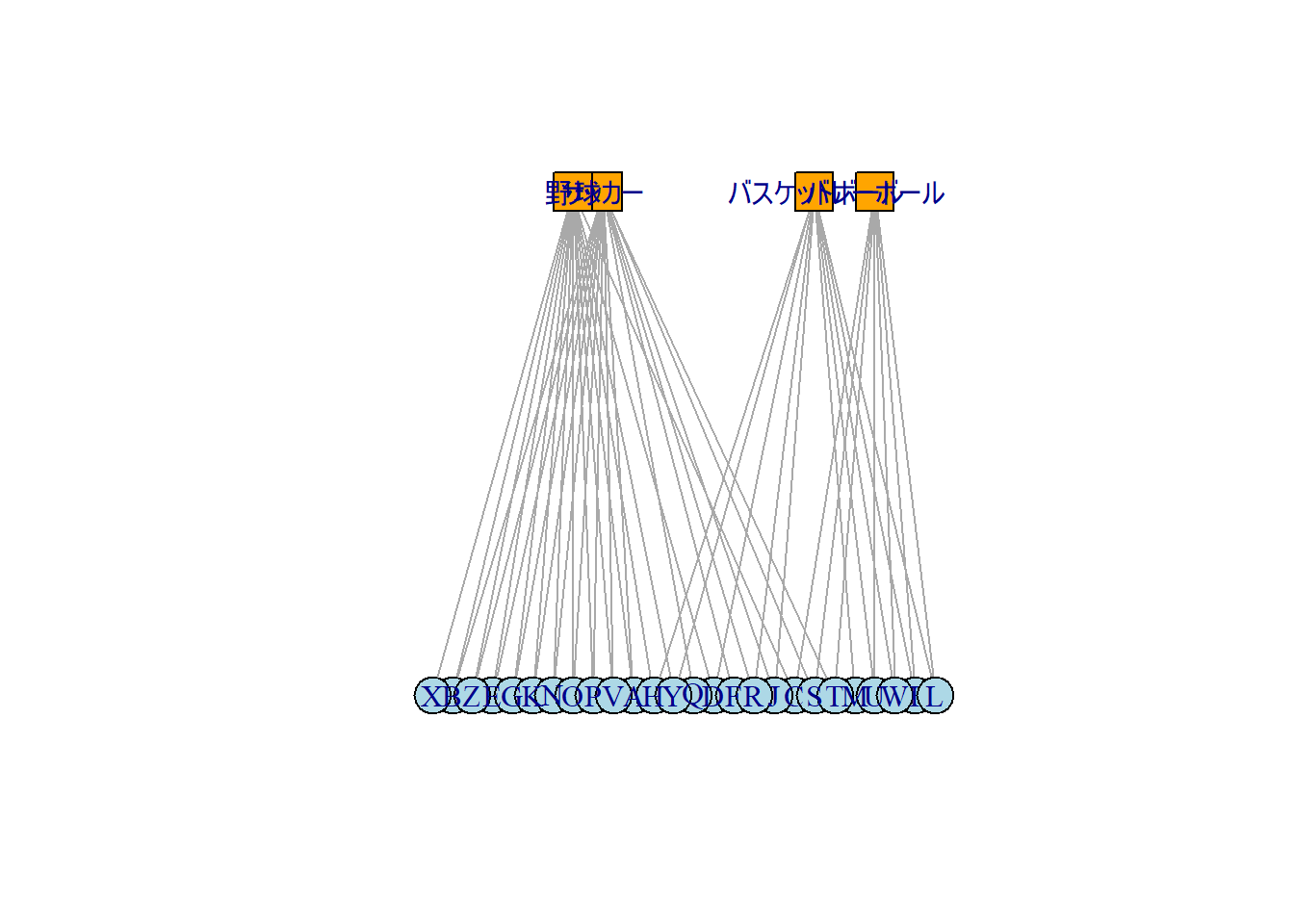
ここまで説明してきたigraphは非常に多機能でよくできたパッケージではありますが、関数名や引数名があまり一定ではなく、使用する際に関数名や引数名をチェックしないとうまく使うことができません。引数の指定方法も多岐に渡っており、統一した手法でグラフを取り扱うことができず、使いにくさがあります。
このような問題を解決するためのパッケージがtidygraphパッケージです。tidygraphパッケージは基本的にtibbleを用いてグラフを作成し、tidyverse(特にdplyr)とパイプ演算子を用いてグラフを編集することを目的として構成されています。
とは言え、igraphが非常に機能豊富なパッケージであったのと同様に、tidygraphも機能豊富で、利用の難易度は高めです。また、解説文等が少ないため、使い方を理解するのが難しい関数もあります。dplyr::mutate関数内以外では使えない関数がたくさんあるなど、使い方もやや複雑です。
tidygraphではグラフはnodeとedgeで表されます。igraphとは異なり、nodeがvertexと呼ばれることはありません。
tidygraphでは、igraphと同じく、データフレームからグラフを作成します。また、igraphで作成したグラフオブジェクトやedge vector、adjacency matrixからもグラフを作成することができます。データフレームからグラフを作成する場合にはtbl_graph関数、その他のオブジェクトやigraphのグラフからtidygraphのグラフを作成する場合にはas_tbl_graph関数を用います。
作成したグラフのクラスはigraphとtbl_graphとなっており、表示するとnodeとedgeのデータフレームが示されます。igraphではvertexに指定するデータフレームの2列目以降、edgeに指定するデータフレームの3列目以降はattributeとして登録されますが、tbl_graphではnodeとedgeのtibbleとして表示されます。tbl_graphはigraphのオブジェクトでもあるので、igraphと同じようにattributesとしてtibbleの列を呼び出すこともできます。
tbl_graphを作成する
pacman::p_load(tidygraph)
d <- read.csv("./data/chapter33_nara_stations.csv") # edgeのデータフレーム
vt <- read.csv("./data/chapter33_nara_stations_vertex_list.csv") # nodeのデータフレーム
colnames(vt) <- c("name", "lat", "lon", "linename", "company") # vertex名はname列から取り込まれる
colnames(d) <- c("from", "to", "linename", "company") # edgeはfrom→toになる
# tbl_graphをデータフレームから作成する
g <- tbl_graph(nodes = vt, edges = d, directed = FALSE)
# igraphオブジェクトをtbl_graphに変換する
as_tbl_graph(karate)
## # A tbl_graph: 34 nodes and 78 edges
## #
## # An undirected simple graph with 1 component
## #
## # Node Data: 34 × 0 (active)
## #
## # Edge Data: 78 × 2
## from to
## <int> <int>
## 1 1 2
## 2 1 3
## 3 1 4
## # ℹ 75 more rows
class(g) # クラスはtbl_graph
## [1] "tbl_graph" "igraph"
V(g)$lat # igraphとして取り扱い、attributeとして2列目以降を呼び出すこともできる
## [1] 34.68078 34.66998 34.64340 34.62101 34.60120 34.57420 34.55911 34.54543
## [9] 34.52719 34.51347 34.51078 34.50962 34.59772 34.57763 34.56155 34.54335
## [17] 34.52765 34.51627 34.48867 34.46466 34.45834 34.45236 34.42085 34.38266
## [25] 34.35572 34.58930 34.60150 34.62228 34.64797 34.69332 34.68555 34.67593
## [33] 34.66550 34.65655 34.64814 34.64007 34.62917 34.61748 34.60600 34.60099
## [41] 34.59775 34.58913 34.58517 34.57857 34.57032 34.56935 34.56830 34.72374
## [49] 34.70172 34.69391 34.68151 34.67054 34.65923 34.64620 34.62042 34.60662
## [57] 34.59827 34.58458 34.57194 34.55330 34.54179 34.52551 34.51320 34.50925
## [65] 34.49337 34.53911 34.53162 34.51647 34.51115 34.50855 34.50694 34.49796
## [73] 34.49332 34.48612 34.48344 34.47411 34.46487 34.44984 34.44186 34.43160
## [81] 34.40729 34.39511 34.38841 34.38366 34.38612 34.39027 34.39549 34.39022
## [89] 34.48940 34.47598 34.69171 34.69411 34.69694 34.69816 34.68543 34.55387
## [97] 34.54635 34.54144 34.53485 34.52618 34.51961 34.52069 34.51978 34.51253
## [105] 34.51292 34.51614 34.52662 34.52975 34.56603 34.60225 34.60100 34.50834
## [113] 34.34589 34.71070 34.55366 34.37661 34.46474 34.68436 34.57828igraphではnode(vertex)やedgeを呼び出す場合、V関数とE関数を用いますが、tidygraphではnode・edgeの呼び出しにactivate関数を用います。activate関数はパイプ演算子を用いて呼び出すことが想定されている関数で、パイプ演算子でつないでグラフに適用します。第2引数としてnodesとedgesを用います。activate関数をグラフに適用すると、node・edgeのtibbleに「activate」と表示されます。この状態でさらにパイプ演算子をつなぐと、activateされている側のtibbleを編集することができます。
node・edgeのどちらがactiveであるかを調べる場合には、active関数を用います。
activate関数
# node・edgeをactivateする
g |> active() # nodeがactiveになっている
## [1] "nodes"
g |> activate(edges) # edgeをactiveにする(nodeはactiveではなくなる)
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Edge Data: 120 × 4 (active)
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## 4 4 5 万葉まほろば線 JR
## 5 5 6 万葉まほろば線 JR
## 6 6 7 万葉まほろば線 JR
## 7 7 8 万葉まほろば線 JR
## 8 8 9 万葉まほろば線 JR
## 9 9 10 万葉まほろば線 JR
## 10 10 11 万葉まほろば線 JR
## # ℹ 110 more rows
## #
## # Node Data: 119 × 5
## name lat lon linename company
## <chr> <dbl> <dbl> <chr> <chr>
## 1 奈良 34.7 136. 万葉まほろば線 JR
## 2 京終 34.7 136. 万葉まほろば線 JR
## 3 帯解 34.6 136. 万葉まほろば線 JR
## # ℹ 116 more rows
g |> activate(edges) |> active() # edgeがactiveになっている
## [1] "edges"tidygraphでは、基本的にactivateでnode・edgeのいずれかを選択した後、mutateなどdplyrの関数を用いてグラフの要素であるtibbleを編集していきます。
mutateなどで編集を行うために、行を選択するための関数がfocusです。focus関数の引数には論理型を用い、TRUEの行のみをdplyrの関数での編集の対象とすることができます。以下の例では、nodeのはじめの5行を選択し、その行だけをmutateでの演算の対象としています。
focusで行を選択して編集する
g |>
activate(nodes) |>
focus(c(T, T, T, T, T, rep(F, 114))) |> # 始めの5つのnodeにfocusする
mutate(lat = lat - 50) # 初めの5つのnodeのlatから50を引く
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Focused on 5 nodes
## # Node Data: 119 × 5 (active)
## name lat lon linename company
## <chr> <dbl> <dbl> <chr> <chr>
## 1 奈良 -15.3 136. 万葉まほろば線 JR
## 2 京終 -15.3 136. 万葉まほろば線 JR
## 3 帯解 -15.4 136. 万葉まほろば線 JR
## 4 櫟本 -15.4 136. 万葉まほろば線 JR
## 5 天理 -15.4 136. 万葉まほろば線 JR
## 6 長柄 34.6 136. 万葉まほろば線 JR
## 7 柳本 34.6 136. 万葉まほろば線 JR
## 8 巻向 34.5 136. 万葉まほろば線 JR
## 9 三輪 34.5 136. 万葉まほろば線 JR
## 10 桜井 34.5 136. 万葉まほろば線 JR
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rows上記のigraphで説明したクラスター計算では、nodeを各クラスターに分離することができます。ただし、分離したクラスターごとに何らかの演算をしたい場合や、nodeのグループごとに演算を行いたい場合、igraphには簡単に計算する方法はありません。tidygraphでは、このようなグループごとの演算をmorph関数を用いて簡単に行うことができます。
morph関数はnode・edgeのtibbleを一時的に変換するための関数です。tidygraphの開発者(Dr. Thomas Lin Pedersen、patchworkやgganimateの開発者)は、このmorph/unmorph/crystaliseをtidygraphの最も代表的な関数の一つだと考えているようで、使い方を理解すれば非常に便利な関数群です。
以下の例ではgroup_infomap関数(igraphのcluster_infomap関数のwrapper)でnodeをクラスター分けし、morph関数内ではそのクラスター(group)に従いto_split関数でtibbleを一時的にnestしています(tidyr::nestに関しては20章を参照。複数の要素をtibbleの「セル」として設定する方法のこと)。
nestしたtibbleに対してgraph_diameter関数(igraphのdiameter関数のwrapper)とcentrality_degree関数(igraphのdegree関数のwrapper)を適用することで、クラスターごとのネットワークの直径、nodeの中心性を演算して行に追加しています。ただし、このままではtibbleがnestされたままです。
このnestされたtibbleをもとに戻すのがunmorph関数です。unmorph関数を適用することで、nodeのtibbleのnestが解除される、つまりunnestされて元のグラフに戻ります。
このように、morph/unmorphを用いることで、node・edgeのグループごとの演算を簡単に行うことができます。morphでのグループ分けのための関数にはto_subgraph関数(dplyr::filterに近い演算を行うもの)やto_components関数などが準備されています。
morph・unmorph関数
# サブグループ内での演算を行うときにはmorph/unmorphを用いる
# morph内の関数はto_から始まる関数群を用いる
g |>
activate(nodes) |> # nodeをactiveにして
mutate(group = group_infomap()) |> # クラスターに分けて
morph(to_split, group) |> # グループで一時的に分割・ネストして
mutate(
group_diameter = graph_diameter(),
centrality = centrality_degree()) |> # グループごとに直径を計算して
unmorph() # morphをもとに戻す
## Splitting by nodes
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Node Data: 119 × 8 (active)
## name lat lon linename company group group_diameter centrality
## <chr> <dbl> <dbl> <chr> <chr> <int> <dbl> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線 JR 2 5 3
## 2 京終 34.7 136. 万葉まほろば線 JR 2 5 2
## 3 帯解 34.6 136. 万葉まほろば線 JR 2 5 1
## 4 櫟本 34.6 136. 万葉まほろば線 JR 11 4 1
## 5 天理 34.6 136. 万葉まほろば線 JR 11 4 2
## 6 長柄 34.6 136. 万葉まほろば線 JR 3 6 1
## 7 柳本 34.6 136. 万葉まほろば線 JR 3 6 2
## 8 巻向 34.5 136. 万葉まほろば線 JR 3 6 2
## 9 三輪 34.5 136. 万葉まほろば線 JR 3 6 2
## 10 桜井 34.5 136. 万葉まほろば線 JR 3 6 2
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rowsmorphで変形したグラフをそのまま固定するための関数がcrystallise関数です。crystallise関数を用いると、morphで指定した変形の状態などが固定され、tibbleとしてデータが返ってきます。このtibbleの列としてグラフが保存されています。
crystallise関数
(crystallised_g <-
g |>
mutate(group = group_infomap()) |> # クラスターに分けて
morph(to_split, group) |> # グループで一時的に分割して
crystallise() # crystalliseして固定してしまう
)
## Splitting by nodes
## # A tibble: 22 × 2
## name graph
## <chr> <list>
## 1 group: 1 <tbl_grph>
## 2 group: 2 <tbl_grph>
## 3 group: 3 <tbl_grph>
## 4 group: 4 <tbl_grph>
## 5 group: 5 <tbl_grph>
## 6 group: 6 <tbl_grph>
## 7 group: 7 <tbl_grph>
## 8 group: 8 <tbl_grph>
## 9 group: 9 <tbl_grph>
## 10 group: 10 <tbl_grph>
## # ℹ 12 more rows
crystallised_g |> class() # classからgraph関係のものがなくなり、tibbleになっている
## [1] "tbl_df" "tbl" "data.frame"
crystallised_g$graph[1] # 列の要素はグラフになっている
## [[1]]
## # A tbl_graph: 8 nodes and 7 edges
## #
## # An unrooted tree
## #
## # Node Data: 8 × 7 (active)
## name lat lon linename company group .tidygraph_node_index
## <chr> <dbl> <dbl> <chr> <chr> <int> <int>
## 1 新王寺 34.6 136. 田原本線 近鉄 1 41
## 2 大輪田 34.6 136. 田原本線 近鉄 1 42
## 3 佐味田川 34.6 136. 田原本線 近鉄 1 43
## 4 池部 34.6 136. 田原本線 近鉄 1 44
## 5 箸尾 34.6 136. 田原本線 近鉄 1 45
## 6 但馬 34.6 136. 田原本線 近鉄 1 46
## 7 黒田 34.6 136. 田原本線 近鉄 1 47
## 8 西田原本 34.6 136. 田原本線 近鉄 1 115
## #
## # Edge Data: 7 × 5
## from to linename company .tidygraph_edge_index
## <int> <int> <chr> <chr> <int>
## 1 1 2 田原本線 近鉄 43
## 2 2 3 田原本線 近鉄 44
## 3 3 4 田原本線 近鉄 45
## # ℹ 4 more rowsigraphと同様に、tidygraphにも中心性を評価する関数群(centrality_から始まる関数)が設定されています。igraphとの違いは、これらのcentrality_関数群は単独で呼び出すことができず、nodeをactiveにした上でmutate関数の中で呼び出すような使い方をする点です。単独で使用するとエラーが返ってきます。
tidygraphにはこのcentrality_関数が30個以上も設定されています(igraphの中心性演算の関数に加えて、netrankr(Schoch 2022)パッケージから方法を引用しています)。
中心性:centrality_関数
centrality_degree(g) # 直接呼び出せない
## Error in `private$check()`:
## ! This function should not be called directly
# nodeをactiveにしてからmutateで呼び出す
g |>
activate(nodes) |>
mutate(degree_cent = centrality_degree())
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Node Data: 119 × 6 (active)
## name lat lon linename company degree_cent
## <chr> <dbl> <dbl> <chr> <chr> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線 JR 3
## 2 京終 34.7 136. 万葉まほろば線 JR 2
## 3 帯解 34.6 136. 万葉まほろば線 JR 2
## 4 櫟本 34.6 136. 万葉まほろば線 JR 2
## 5 天理 34.6 136. 万葉まほろば線 JR 3
## 6 長柄 34.6 136. 万葉まほろば線 JR 2
## 7 柳本 34.6 136. 万葉まほろば線 JR 2
## 8 巻向 34.5 136. 万葉まほろば線 JR 2
## 9 三輪 34.5 136. 万葉まほろば線 JR 2
## 10 桜井 34.5 136. 万葉まほろば線 JR 4
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rows
# 4種のcentralityを同時に演算する
g |>
activate(nodes) |>
mutate(
cent_degr = centrality_degree(),
cent_betw = centrality_betweenness(),
cent_clos = centrality_closeness(),
cent_eigv = centrality_eigen())
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Node Data: 119 × 9 (active)
## name lat lon linename company cent_degr cent_betw cent_clos cent_eigv
## <chr> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線…… JR 3 882 0.000728 0.0122
## 2 京終 34.7 136. 万葉まほろば線…… JR 2 862 0.000741 0.0166
## 3 帯解 34.6 136. 万葉まほろば線…… JR 2 887 0.000755 0.0272
## 4 櫟本 34.6 136. 万葉まほろば線…… JR 2 914 0.000770 0.0480
## 5 天理 34.6 136. 万葉まほろば線…… JR 3 1244. 0.000796 0.0866
## 6 長柄 34.6 136. 万葉まほろば線…… JR 2 904. 0.000798 0.102
## 7 柳本 34.6 136. 万葉まほろば線…… JR 2 910. 0.000802 0.156
## 8 巻向 34.5 136. 万葉まほろば線…… JR 2 918. 0.000807 0.268
## 9 三輪 34.5 136. 万葉まほろば線…… JR 2 928. 0.000814 0.480
## 10 桜井 34.5 136. 万葉まほろば線…… JR 4 1340 0.000822 0.870
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rowstidygraphには、igraphと同様にnode、edge、graphを評価するための関数群が設定されています。いずれの関数も単独で呼び出すことはできず、mutate関数内で呼び出して用いることが前提とされています。
以下にnodeの評価に関わる関数を示します。上記の中心性もこのnodeの評価に関わる関数の一部となります。
nodeの評価
# 単独では呼び出せない
node_efficiency(g)
## Error in `private$check()`:
## ! This function should not be called directly
g |>
activate(nodes) |>
mutate(
node_eff = node_efficiency(), # nodeの効率(igraph::local_efficiency)
node_core = node_coreness() # k-core分解(igraph::coreness)
)
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Node Data: 119 × 7 (active)
## name lat lon linename company node_eff node_core
## <chr> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線 JR 0.0108 2
## 2 京終 34.7 136. 万葉まほろば線 JR 0.0323 2
## 3 帯解 34.6 136. 万葉まほろば線 JR 0.0323 2
## 4 櫟本 34.6 136. 万葉まほろば線 JR 0.0323 2
## 5 天理 34.6 136. 万葉まほろば線 JR 0.0417 2
## 6 長柄 34.6 136. 万葉まほろば線 JR 0.0625 2
## 7 柳本 34.6 136. 万葉まほろば線 JR 0.0625 2
## 8 巻向 34.5 136. 万葉まほろば線 JR 0.0625 2
## 9 三輪 34.5 136. 万葉まほろば線 JR 0.0625 2
## 10 桜井 34.5 136. 万葉まほろば線 JR 0.0104 2
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rowsedgeの評価では、edgeの性質を論理型で返すような関数が主に設定されています。edgeの評価に関する関数はそもそも引数にedgeのtibbleを取るように設定されていません。nodeの場合と同じく、edgeの評価の関数もmutate関数内で用いることが想定されています。
edgeの評価
g |>
activate(edges) |>
edge_is_multiple() # そもそも引数として設定できない
## Error in `edge_is_multiple()`:
## ! unused argument (activate(g, edges))
g |>
activate(edges) |>
mutate(
multiple = edge_is_multiple(), # 平行するedgeがあるか
bridge = edge_is_bridge() # edgeが切断されるとグラフが分離されるか
)
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Edge Data: 120 × 6 (active)
## from to linename company multiple bridge
## <int> <int> <chr> <chr> <lgl> <lgl>
## 1 1 2 万葉まほろば線 JR FALSE FALSE
## 2 2 3 万葉まほろば線 JR FALSE FALSE
## 3 3 4 万葉まほろば線 JR FALSE FALSE
## 4 4 5 万葉まほろば線 JR FALSE FALSE
## 5 5 6 万葉まほろば線 JR FALSE FALSE
## 6 6 7 万葉まほろば線 JR FALSE FALSE
## 7 7 8 万葉まほろば線 JR FALSE FALSE
## 8 8 9 万葉まほろば線 JR FALSE FALSE
## 9 9 10 万葉まほろば線 JR FALSE FALSE
## 10 10 11 万葉まほろば線 JR FALSE TRUE
## # ℹ 110 more rows
## #
## # Node Data: 119 × 5
## name lat lon linename company
## <chr> <dbl> <dbl> <chr> <chr>
## 1 奈良 34.7 136. 万葉まほろば線 JR
## 2 京終 34.7 136. 万葉まほろば線 JR
## 3 帯解 34.6 136. 万葉まほろば線 JR
## # ℹ 116 more rowsgraphの評価に関する関数はigraphに設定されている関数群とほぼ同じですが、やはり直接呼び出して用いることはできません。評価の意味に関しては以下を参照して下さい。
グラフ理論講義ノート#8 井上純一先生(北海道大学 情報科学研究科)
graphの評価
g |> graph_diameter() # 直接呼び出せない
## Error in `private$check()`:
## ! This function should not be called directly
g |>
activate(nodes) |>
mutate(
g_diameter = graph_diameter(), # グラフの直径(最大の経路長)
g_girth = graph_girth(), # グラフの内周(最小の閉路長)
g_radius = graph_radius(), # グラフの離心率(igraph::radius)
g_size = graph_size() # グラフのedgeの数
)
## # A tbl_graph: 119 nodes and 120 edges
## #
## # An undirected simple graph with 2 components
## #
## # Node Data: 119 × 9 (active)
## name lat lon linename company g_diameter g_girth g_radius g_size
## <chr> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線 JR 33 18 4 120
## 2 京終 34.7 136. 万葉まほろば線 JR 33 18 4 120
## 3 帯解 34.6 136. 万葉まほろば線 JR 33 18 4 120
## 4 櫟本 34.6 136. 万葉まほろば線 JR 33 18 4 120
## 5 天理 34.6 136. 万葉まほろば線 JR 33 18 4 120
## 6 長柄 34.6 136. 万葉まほろば線 JR 33 18 4 120
## 7 柳本 34.6 136. 万葉まほろば線 JR 33 18 4 120
## 8 巻向 34.5 136. 万葉まほろば線 JR 33 18 4 120
## 9 三輪 34.5 136. 万葉まほろば線 JR 33 18 4 120
## 10 桜井 34.5 136. 万葉まほろば線 JR 33 18 4 120
## # ℹ 109 more rows
## #
## # Edge Data: 120 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 117 more rowsigraphではmake_関数(make_ring関数やmake_star関数など)で形状を指定したグラフを、sample_関数(sample_tree関数やsample_gnp関数など)でアルゴリズムに従ったランダムなグラフを作成することができます。このigraphのmake_関数とsample_関数に当たるものがtidygraphのcreate_関数とplay_関数です。出力がtbl_graphであることと、引数の順序・名前以外にigraphの関数群と大きな差は無いので、igraphの関数に慣れているのであればigraphの関数を用いてグラフを作成した後でas_tbl_graph関数を用いてtbl_graphに変換してもよいでしょう。
purrrのmap関数と同様に、node、edgeのtibbleに関数を適用して演算を行う関数がmap_関数群です。
map_関数群には大きく分けるとbfs(breath first search、幅優先探索)を演算に用いるもの(map_bfs_関数)と、dfs(depth first search、深さ優先探索)を用いるもの(map_dfs_関数)があります。
map_関数も単独では呼び出すことができず、mutate関数内で呼び出すことが想定された関数で、map_関数内で引数(.f引数)として設定する関数は無名関数のみとなります。この.f関数で指定する無名関数については引数が定められていて(node, rank, pathなど)、かなり使い方が複雑です。また、bfs、dfsで到達不可能なパスが存在すると演算ができなくなります。
以下の例では、bfsによってJR奈良駅から他の駅までの到達に必要な距離を演算しています。valueに駅間の距離や運賃などを正確に設定すれば、map_bfs_dbl関数を用いて到達距離を計算することができます。
map_関数
g |>
# 離れているとbfsで探索できないので、田原本線をつなげる
bind_edges(data.frame(from = "田原本", to = "西田原本", linename = "田原本線", company = "近鉄")) |>
mutate(value = rep(1, 119)) |> # 駅間を1としている
mutate(value_acc = map_bfs_dbl(1, .f = function(node, path, ...){
sum(.N()$value[c(node, path$node)]) # searchの順に値を足していく(各nodeまでの距離を反映)
}))
## Warning: There was 1 warning in `mutate()`.
## ℹ In argument: `value_acc = map_bfs_dbl(...)`.
## Caused by warning:
## ! The `father` argument of `bfs()` is deprecated as of igraph 2.2.0.
## ℹ Please use the `parent` argument instead.
## ℹ The deprecated feature was likely used in the tidygraph package.
## Please report the issue at <https://github.com/thomasp85/tidygraph/issues>.
## # A tbl_graph: 119 nodes and 121 edges
## #
## # An undirected simple graph with 1 component
## #
## # Node Data: 119 × 7 (active)
## name lat lon linename company value value_acc
## <chr> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
## 1 奈良 34.7 136. 万葉まほろば線 JR 1 1
## 2 京終 34.7 136. 万葉まほろば線 JR 1 2
## 3 帯解 34.6 136. 万葉まほろば線 JR 1 3
## 4 櫟本 34.6 136. 万葉まほろば線 JR 1 4
## 5 天理 34.6 136. 万葉まほろば線 JR 1 5
## 6 長柄 34.6 136. 万葉まほろば線 JR 1 6
## 7 柳本 34.6 136. 万葉まほろば線 JR 1 7
## 8 巻向 34.5 136. 万葉まほろば線 JR 1 8
## 9 三輪 34.5 136. 万葉まほろば線 JR 1 9
## 10 桜井 34.5 136. 万葉まほろば線 JR 1 10
## # ℹ 109 more rows
## #
## # Edge Data: 121 × 4
## from to linename company
## <int> <int> <chr> <chr>
## 1 1 2 万葉まほろば線 JR
## 2 2 3 万葉まほろば線 JR
## 3 3 4 万葉まほろば線 JR
## # ℹ 118 more rows上記のように、グラフの表示はグラフの理解において非常に重要です。igraphを用いることでグラフを様々な形式で表示することができますが、デザイン的にはggplot2などとは異なり、Rのデフォルトのプロットに近い形での表示となります。Rには、igraphだけでなく、グラフを表示するためのパッケージがいくつかありますので、以下に簡単に紹介します。
ggraph(Pedersen 2024a)は上記のtidygraphの開発者が開発した、tbl_graphをggplot2の文法・デザインで描画するためのパッケージです。仕組みは比較的単純で、以下の例のようにtbl_graphをggplot2のグラフ表示に適したtibbleに変形し(create_layout関数)、ggplot2の文法でこのtibbleを表示しています。この変換において、nodeの位置をlayout引数で指定した位置に指定させています。
layout引数には"auto"、"igraph"、"dendrogram"、"manual"、"linear"、"matrix"、"treemap"などの様々な値を指定することができます。layoutによる違いは後ほど説明します。
ggraph:create_layout関数
pacman::p_load(ggraph)
create_layout(g, layout = "tree")
## # A tibble: 119 × 10
## x y name lat lon linename company .ggraph.orig_index circular
## <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr> <int> <lgl>
## 1 -7.97 12 奈良 34.7 136. 万葉まほろば線…… JR 1 FALSE
## 2 -7.97 13 京終 34.7 136. 万葉まほろば線…… JR 2 FALSE
## 3 -7.97 14 帯解 34.6 136. 万葉まほろば線…… JR 3 FALSE
## 4 -7.97 15 櫟本 34.6 136. 万葉まほろば線…… JR 4 FALSE
## 5 -6.47 16 天理 34.6 136. 万葉まほろば線…… JR 5 FALSE
## 6 -6.47 17 長柄 34.6 136. 万葉まほろば線…… JR 6 FALSE
## 7 -6.47 18 柳本 34.6 136. 万葉まほろば線…… JR 7 FALSE
## 8 -6.47 19 巻向 34.5 136. 万葉まほろば線…… JR 8 FALSE
## 9 -6.47 20 三輪 34.5 136. 万葉まほろば線…… JR 9 FALSE
## 10 -3.03 21 桜井 34.5 136. 万葉まほろば線…… JR 10 FALSE
## # ℹ 109 more rows
## # ℹ 1 more variable: .ggraph.index <int>ggraphの文法はggplot2と非常に類似しています。まず、ggplot2でのggplot関数に当たるggraph関数の引数として、グラフ、layout引数を設定します。layoutによってはこのggraph関数内で追加の引数を設定する必要があります。ggplot2と同様に、このggraph関数に足し算(+)で他のgeom関数を付け加えていくことでグラフを構成していきます。
以下の例では、nodeを点で表示し(geom_node_point)、node側のtibbleの変数であるname(駅名)をテキストとして重ね書きし(geom_node_text)、edgeを運行会社により色分けして直線でつないでいます(geom_edge_link)。ggplot2のaes関数に関してはgeom_node_関数、geom_edge_関数内で指定します。geom_node_関数内ではnode側のtibble、geom_edge_関数内ではedge側のtibbleの列名を用いて表示する色や大きさを指定することができます。
ggraph:グラフを描画する
# グラフのテーマの設定(ggplot2のthemeをあらかじめ定めておくもの)
windowsFonts(Meiryo = windowsFont("Meiryo"))
set_graph_style(family="Meiryo", text_size = 5, background = "white", caption_size = 3)
# x、yで指定した位置にnodeを表示する
ggraph(g, layout = "manual", x = lon, y = lat) +
geom_node_point() +
geom_node_text(aes(label = name)) +
geom_edge_link(aes(color = company))
このggraphのlayout・node・edgeの表示は非常に多種多様で、情報を捉えにくいものも含まれています。開発者がアートに興味があることもあり、ggraphにはどちらかというと現代美術的な、意味よりも見た目重視な表示方法も含まれています。
以下にlayoutの例を示します。layoutは単にnodeのx・y軸上の位置を定めているだけで、layout自体にはそれほど変わったものはありません。とは言え、特定のnode・edgeの表示とセットで用いることを前提としている、使いにくいものもあります。
layoutにはsfをベースにしたもの(layout = "sf")もあるため、上記のような路線図であれば、sfで表示するのもよいでしょう。sfについては45章で説明しています。
g |> ggraph(layout = "auto") +
geom_node_point() +
geom_edge_link() # stressが選択されている
## Using "stress" as default layout
g |> ggraph(layout = "stress") +
geom_node_point() +
geom_edge_link() # autoで選ばれているのと同じ
g |>
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "sparse_stress", pivots = 10) + # 分離したグラフでは表示できない
geom_node_point() +
geom_edge_link()
g |>
ggraph(layout = "igraph", algorithm = "grid") + # igraphのon_gridと同じ
geom_node_point() +
geom_edge_link()
g |>
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "backbone") + # 分離したグラフには適さない
geom_node_point() +
geom_edge_link()
g |>
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "pmds", pivots = 10) + # 分離したグラフでは表示できない
geom_node_point() +
geom_edge_link()
g |>
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "eigen") + # 分離したグラフでは表示できない
geom_node_point() +
geom_edge_link()
g |>
mutate(cent = centrality_degree()) |> # 中心性に従い位置を決定する
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "centrality", centrality = cent) + # 分離したグラフでは表示できない
geom_node_point() +
geom_edge_link()
g |> # 分離したグラフでは表示できない
bind_edges(data.frame(from="田原本", to="西田原本", linename="田原本線", company="近鉄")) |>
ggraph(layout = "focus", focus = 1) + # JR奈良駅にfocusする
geom_node_point() +
geom_edge_link()
create_tree(n=30, children = 4) |> # 有向グラフにしか適用できない
ggraph(layout = "dendrogram") +
geom_node_point() +
geom_edge_link()
g |>
ggraph(layout = "unrooted") +
geom_node_point() +
geom_edge_link()
g |>
ggraph(layout = "linear") +
geom_node_point() +
geom_edge_arc() # 直線ではedgeが見えないのでarcとしている
set.seed(0)
play_gnm(30, 80, directed = TRUE) |> # 有向グラフのみ対応
ggraph(layout = "circlepack") +
geom_node_point() +
geom_edge_link()
## Multiple parents. Unfolding graph
## Multiple roots in graph. Choosing the first
create_tree(n=30, children = 4) |> # 有向グラフにしか適用できない
ggraph(layout = "treemap") +
geom_node_point() +
geom_edge_link()
create_tree(n=30, children = 4) |> # 有向グラフにしか適用できない
ggraph(layout = "partition") +
geom_node_point() +
geom_edge_link()
create_tree(n=30, children = 2) |> # 有向グラフでないとnodeが範囲外に出る
ggraph(layout = "cactustree") +
geom_node_point() +
geom_edge_link()
create_tree(n=15, children = 2) |> # 二分木でないと描画できない
ggraph(layout = "htree") +
geom_node_point() +
geom_edge_link()
g |> ggraph(layout = "matrix") +
geom_node_point() +
geom_edge_arc() # 直線では見えなくなるのでarcを選択
g |>
activate(nodes) |>
mutate(linename = E(g)$linename[1:119]) |>
ggraph(layout = "hive", axis = linename) + # linenameを軸として配置
geom_node_point() +
geom_edge_arc(aes(color=linename)) # 直線では見えなくなるのでarcを選択
g |> ggraph(layout = "fabric") +
geom_node_point() +
geom_edge_link()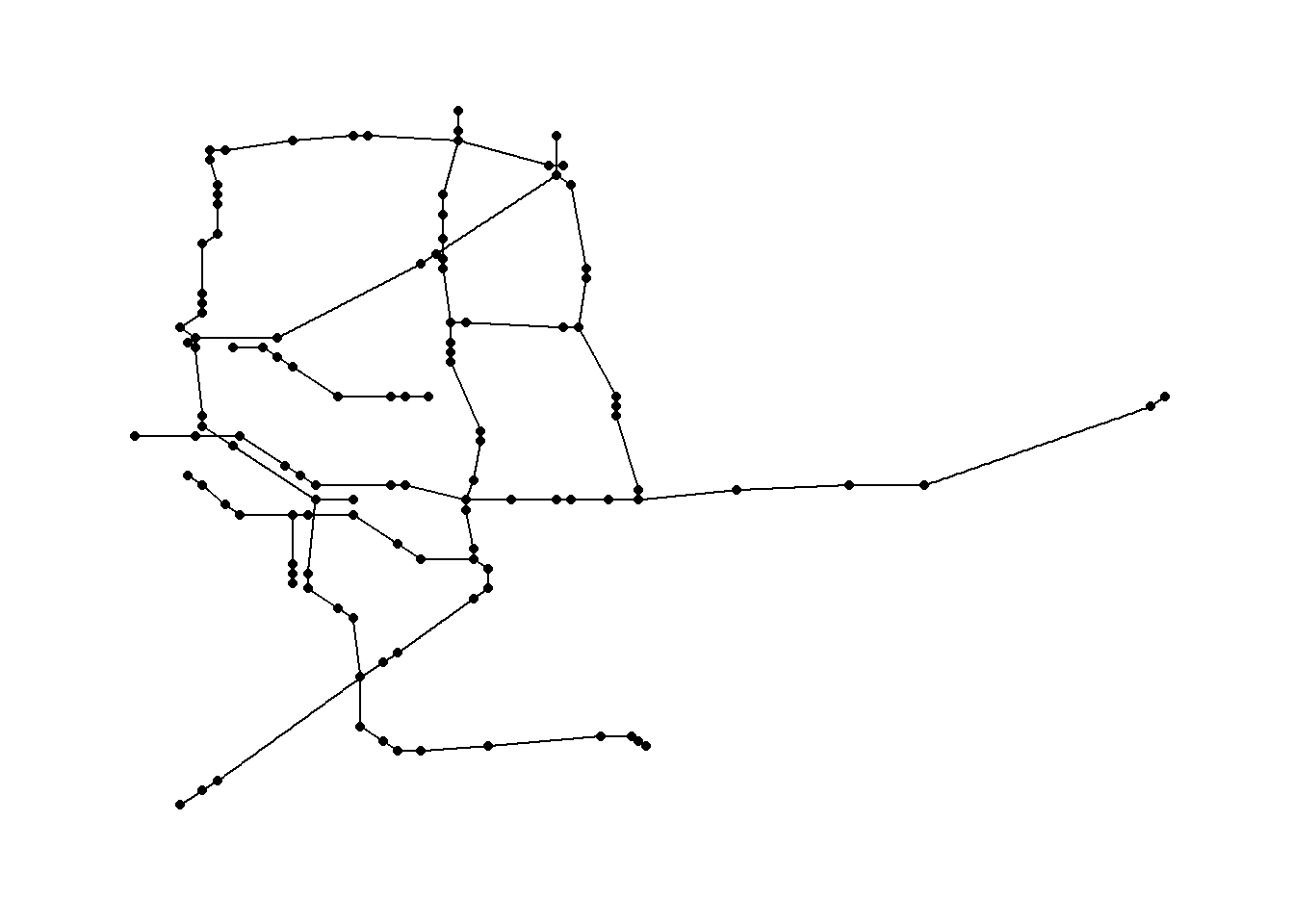
g |> ggraph(layout = "metro", x = lon, y = lat) +
geom_node_point() +
geom_edge_link()
nodeの表示には、geom_node_関数を用います。geom_node_の後にnodeの形状を示す単語(point、text、tile、voronoiなど)を繋ぐことで、nodeの形状を指定します。geom_node_関数はggplot2のgeom_関数と同様に、ggraph関数に+でつないで用います。
geom_node_pointやgeom_node_text、geom_node_labelはどのようなグラフで用いても使いやすいですが、geom_node_voronoiのようにデザイン重視でネットワークの理解にはつながらないものもあります。以下にgeom_node_関数の使用例を示します。
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_point()
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_text(aes(label = name))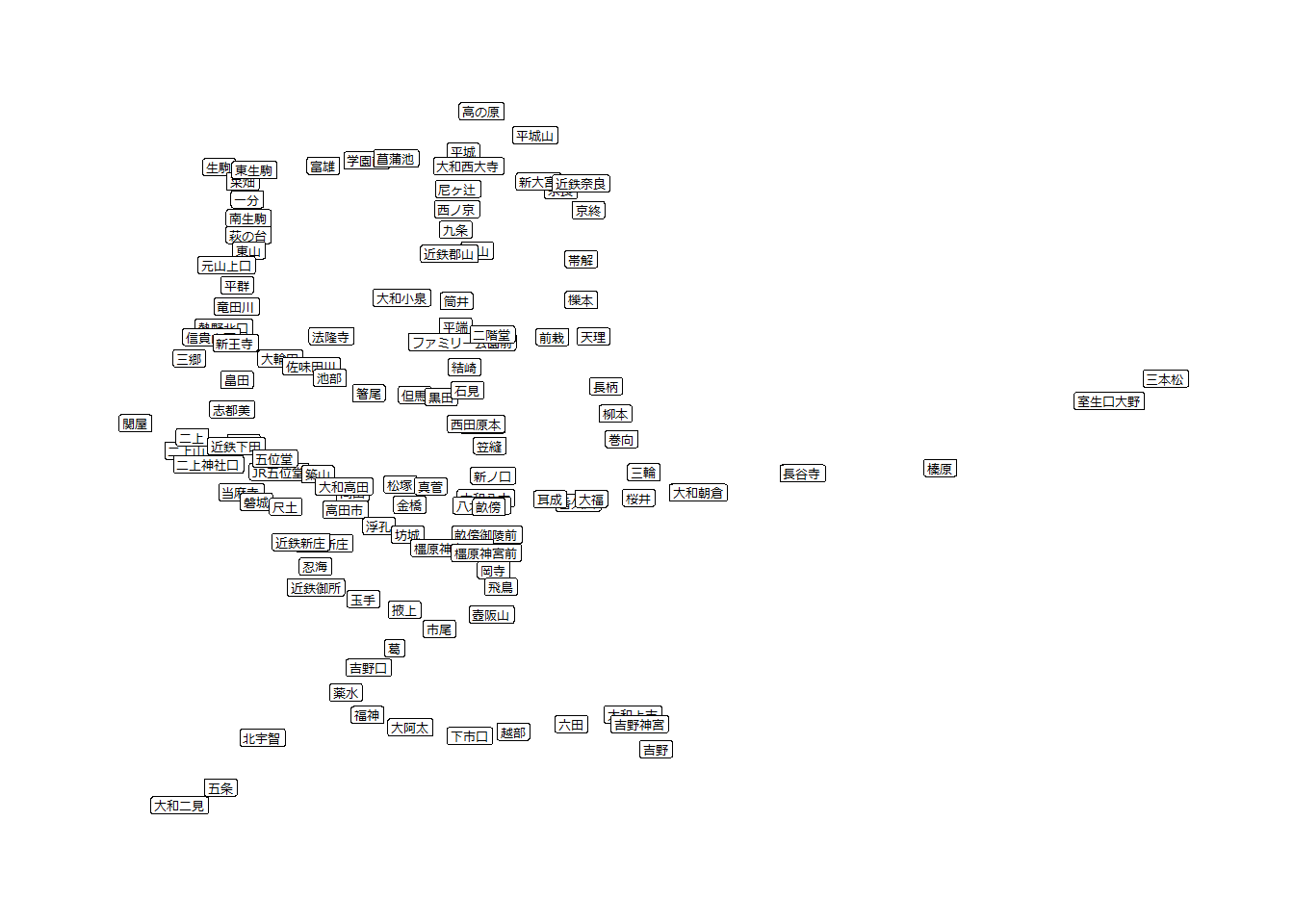
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_label(aes(label = name))
g |>
ggraph(layout = "igraph", algorithm = "grid") +
geom_node_tile(aes(fill=lon, color = lat, width=0.9, height=0.9))
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_circle(aes(r = lon/10000, color = factor(lon)))+
theme(legend.position = "none")
g |>
ggraph(layout = "fabric") +
geom_node_range(aes(color = factor(lon)))+
theme(legend.position = "none")
edgeの表示には、geom_edge_関数を用います。geom_edge_関数はgeom_node_関数とほぼ同じように用います。つまり、geom_edge_の後に形状を指定する単語(link、arcなど)を繋いだ関数として用い、ggraph関数に+でつないで用います。
geom_edge_link関数やgeom_edge_arc関数のように比較的使いやすいものから、平行するedge(同じnode間をつなぐ複数のedge)を示すときだけに用いるもの(geom_edge_parallel、geom_edge_fan)、ループ(ノードからそのノード自身に接続するedge)を示すときだけに用いるもの(geom_edge_loop)、特定のlayout・nodeと共に用いることが想定されているもの(geom_edge_hive、geom_edge_span)など、特定の場合以外にはほぼ用いないものもあります。
create_tree(n=30, children = 4) |>
ggraph(layout = "dendrogram") +
geom_node_point() +
geom_edge_link()
karate |>
ggraph(layout = "auto") +
geom_node_point() +
geom_edge_arc()
## Using "stress" as default layout
# マニュアルの例の通り
gr <- create_notable('bull') |>
convert(to_directed) |>
bind_edges(data.frame(from = c(1, 2, 2, 3), to = c(2, 1, 3, 2)))
ggraph(gr, 'stress') +
geom_node_point(aes(size=1))+
geom_edge_parallel(aes(alpha = after_stat(index)))+
theme(legend.position = "none")
gr <- create_notable('bull') |>
convert(to_directed) |>
bind_edges(data.frame(from = c(1, 2, 2, 3), to = c(2, 1, 3, 2)))
ggraph(gr, 'stress') +
geom_node_point(aes(size=1))+
geom_edge_fan(aes(alpha = after_stat(index)))+
theme(legend.position = "none")
data.frame(from = c(1, 1, 2, 2, 3, 3, 3), to = c(1, 2, 2, 3, 3, 1, 1)) |>
as_tbl_graph() |>
ggraph(layout = "auto") +
geom_node_point() +
geom_edge_loop() + # node自身への接続(ループ)を表示する
geom_edge_fan()
## Using "stress" as default layout
create_tree(n=30, children = 4) |>
ggraph(layout = "dendrogram") +
geom_node_point() +
geom_edge_diagonal() # ベジェ曲線
create_tree(n=30, children = 4) |>
ggraph(layout = "auto") +
geom_node_point() +
geom_edge_elbow()
## Using "tree" as default layout
create_tree(n=30, children = 4) |>
ggraph(layout = "auto") +
geom_node_point() +
geom_edge_bend()
## Using "tree" as default layout
create_tree(n=30, children = 4) |>
mutate(group = rep(1:3, 10)) |>
ggraph(layout = "hive", axis = group) +
geom_node_point() +
geom_edge_hive() # axis間しか繋がない
g |>
ggraph(layout = "fabric") +
geom_node_range(aes(color = factor(lon)))+
theme(legend.position = "none")+
geom_edge_span()
g |>
ggraph(layout = "manual", x = lon, y = lat) +
theme(legend.position = "none")+
geom_edge_point(aes(color = factor(linename)))
g |>
ggraph(layout = "matrix") +
theme(legend.position = "none")+
geom_edge_tile(aes(color = linename, fill=linename))
g |>
ggraph(layout = "manual", x = lon, y = lat) +
theme(legend.position = "none")+
geom_node_point(size = 0.1)+
geom_edge_density(aes(fill=linename))
make_graph("Zachary") |>
as_tbl_graph() |>
ggraph(layout = "auto") +
theme(legend.position = "none")+
geom_node_point(size = 0.1)+
geom_edge_bundle_force()
## Using "stress" as default layout
make_graph("Zachary") |>
as_tbl_graph() |>
ggraph(layout = "auto") +
theme(legend.position = "none")+
geom_node_point(size = 0.1)+
geom_edge_bundle_path()
## Using "stress" as default layout
make_graph("Zachary") |>
as_tbl_graph() |>
ggraph(layout = "auto") +
theme(legend.position = "none")+
geom_node_point(size = 0.1)+
geom_edge_bundle_minimal()
## Using "stress" as default layout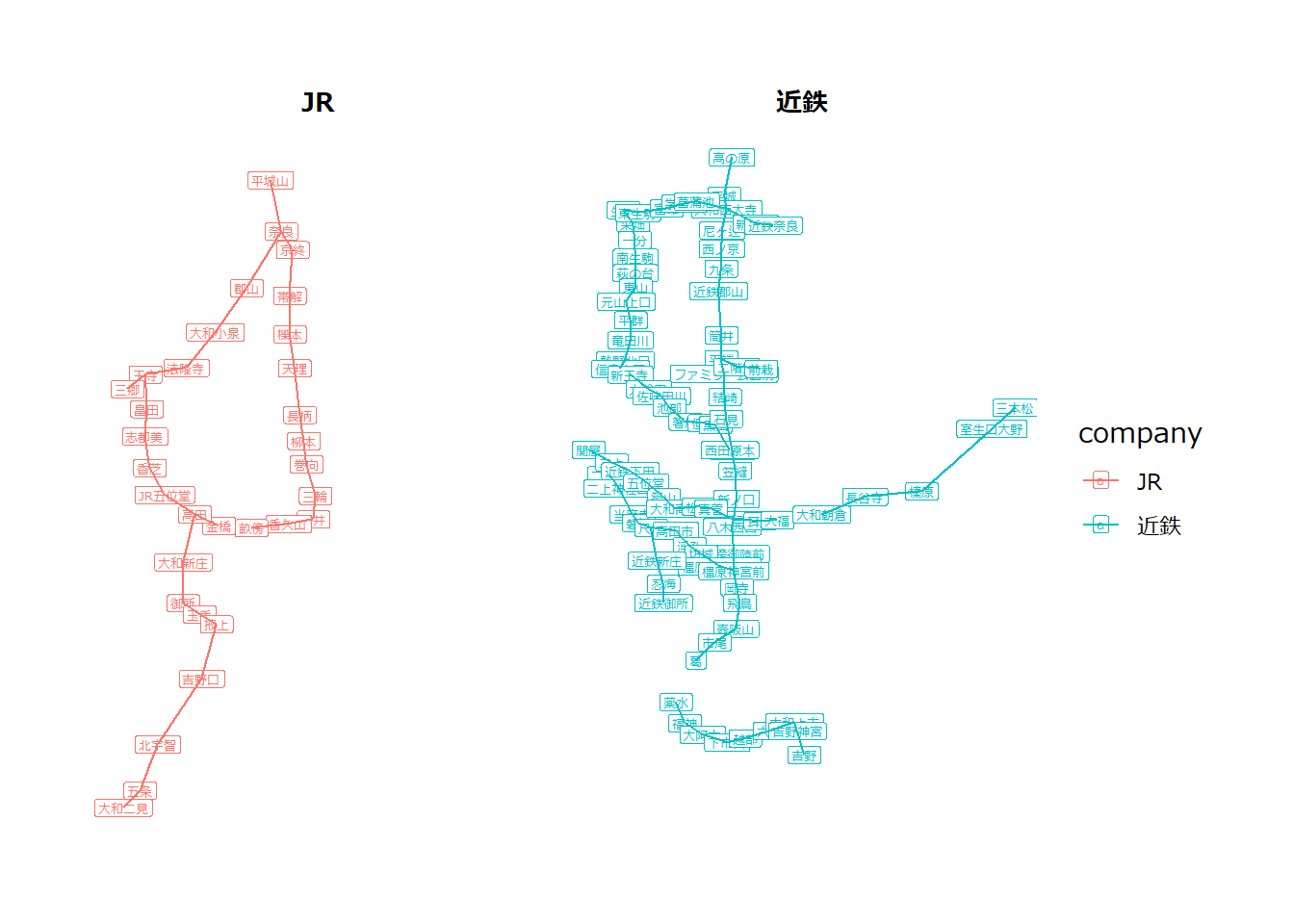
ggplot2と同じように、facet関数を用いることで、tbl_graphに含まれている変数(igraphにおけるattribute)を用いてグラフを分割し、表示することができます。facet関数にはfacet_graph、facet_node、facet_edgeの3つの関数があり、それぞれ使用感が少しずつ異なります。
facet関数の引数にはチルダ(~)を用い、チルダの右辺、もしくは両辺に変数を指定することで、グラフを分割表示することができます。
ggraphには上に示したものの他に、色や文字等を指定するたくさんの関数が設定されています。
faceting
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_label(aes(label = name, color = company)) +
geom_edge_link(aes(, color = company)) +
facet_graph(~ company)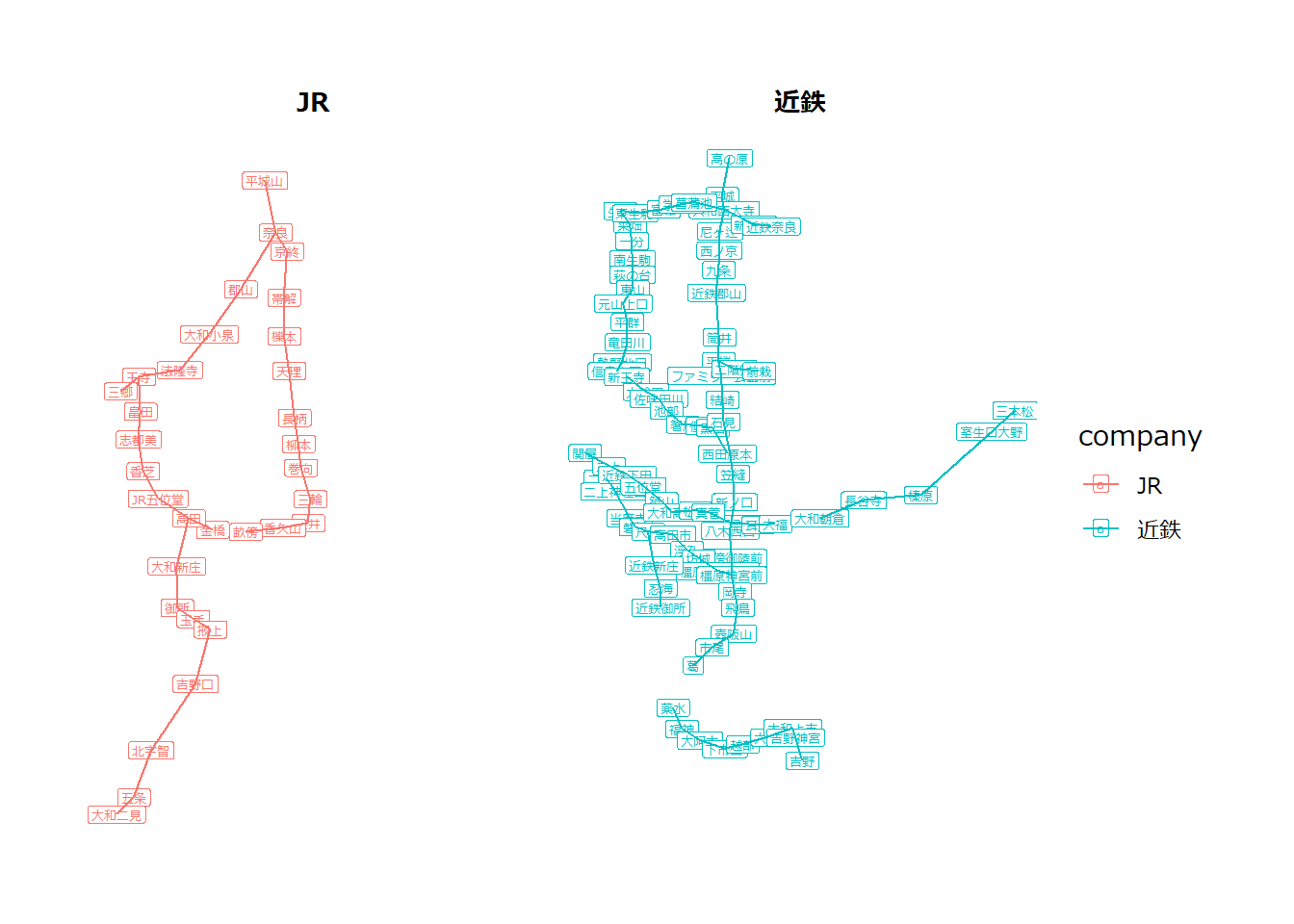
# 上と同じ
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_label(aes(label = name, color = company)) +
geom_edge_link(aes(, color = company)) +
facet_nodes(~ company)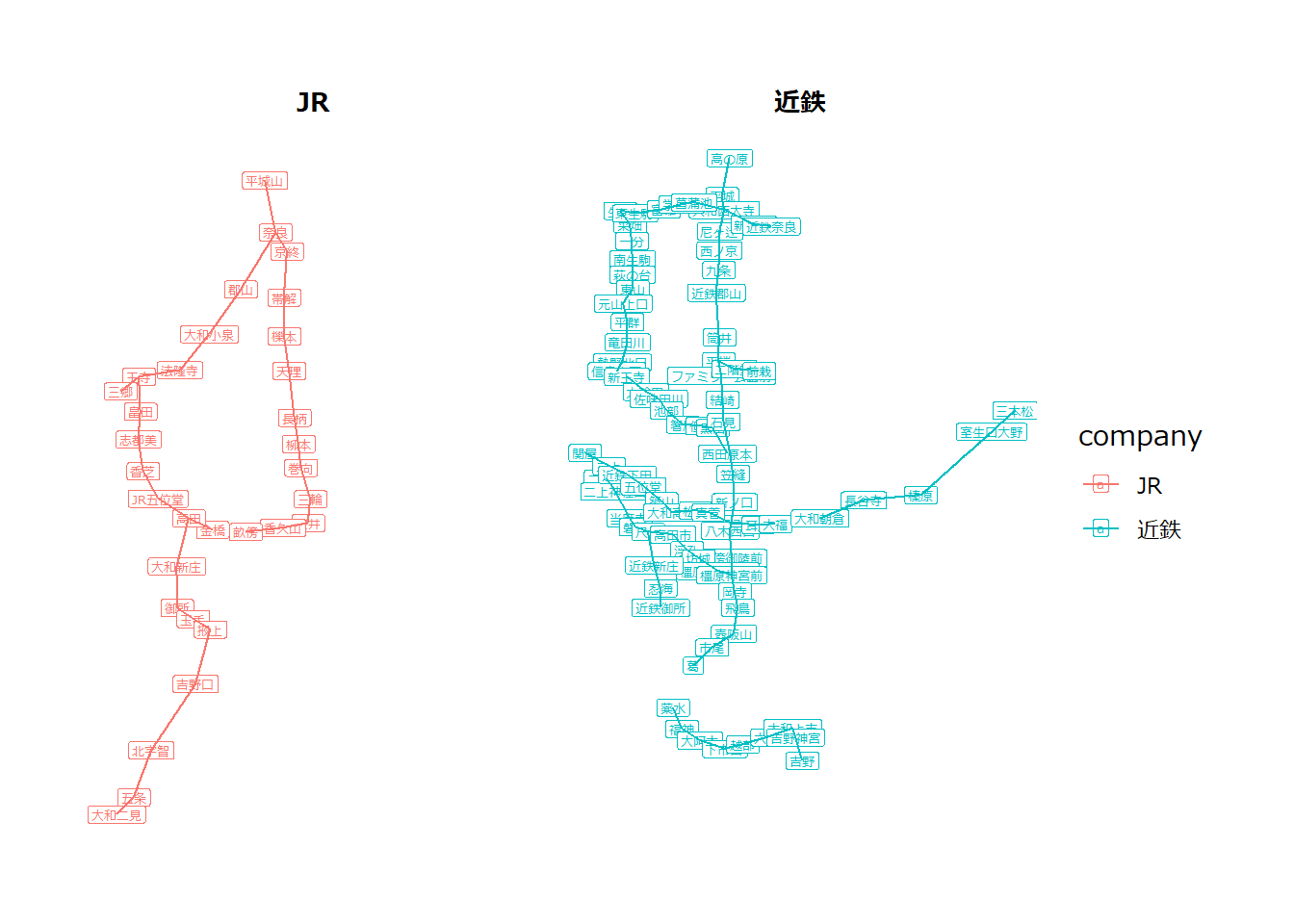
# edgeだけが2つに分かれる
g |>
ggraph(layout = "manual", x = lon, y = lat) +
geom_node_label(aes(label = name, color = company)) +
geom_edge_link(aes(, color = company)) +
facet_edges(~ company)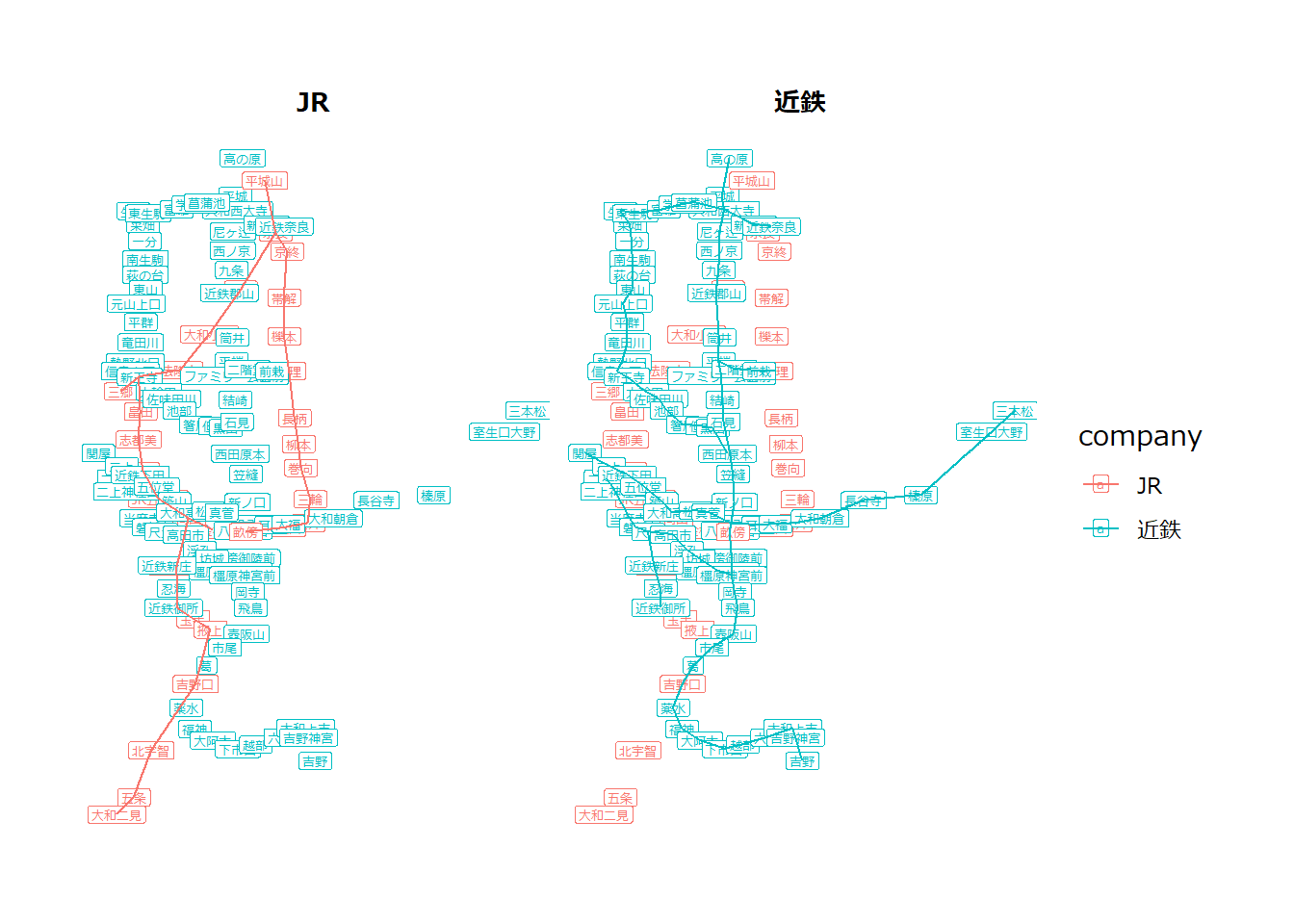
上記のようにigraphのplot関数やggraphで静的なグラフを準備すれば、論文や出版物、プレゼンテーションで示すグラフとしては十分ですが、Web上ではグラフをインタラクティブに示すことでグラフの構造を読み取りやすくできる場合があります。
このようなインタラクティブなグラフの表示を行うためのパッケージがnetworkD3(Allaire et al. 2017)です。networkD3はJavascriptのグラフィックライブラリであるD3.jsをRに持ち込んで、ネットワークの表記ができるようにしたものです。
D3.jsを用いることができるパッケージにはr2d3(Strayer et al. 2022)もありますが、r2d3との違いはネットワークの表記にのみ対応していることで、r2d3でもネットワークを表記することはできます。ただし、r2d3はデータの準備がかなり独特(r2d3のgithubページを参照。idの列にネットワークの情報を入力)ですので、networkD3の方が比較的使いやすいでしょう。
パッケージの読み込み
pacman::p_load(networkD3)networkD3でのグラフ表記には、nodeのデータフレームとedgeのデータフレームをそれぞれ独立に準備する必要があります。igraphやtidygraphのグラフオブジェクトをnetworkD3で利用する場合には、igraph_to_networkD3関数でデータをリストに変換します。このigraph_to_networkD3関数はigraphのオブジェクトをnodeのデータフレーム、edgeのデータフレーム(名前はlinks)からなるリストに変換してくれるだけの関数です。group引数を指定すると、元のigraphオブジェクトのattributeやベクターをnodeのデータフレームに付け加えることもできます。
ファイルの準備
# dとvtからネットワークを作成
nara_stations <- graph_from_data_frame(d, vertices = vt, directed = FALSE)
ns_D3 <- nara_stations |>
igraph_to_networkD3(group = V(nara_stations)$linename)
ns_D3$links |> head() # edge_listに似たデータフレーム
## source target
## 1 15 16
## 2 55 56
## 3 30 31
## 4 83 84
## 5 74 75
## 6 82 83
ns_D3$nodes |> head() # nodeをまとめたもの
## name group
## 1 奈良 万葉まほろば線
## 2 京終 万葉まほろば線
## 3 帯解 万葉まほろば線
## 4 櫟本 万葉まほろば線
## 5 天理 万葉まほろば線
## 6 長柄 万葉まほろば線最も簡単にネットワークを表示するための関数が、simpleNetwork関数です。この関数の引数にedgeを示すデータフレームを設定するだけで、D3.jsを用いたネットワークを表示することができます。このグラフ上では、nodeをドラッグすることでnodeを移動させて表記することができます。
ただし、このsimpleNetworkをそのまま用いるとグラフが拡大されすぎて見えなかったり、nodeの意味がよくわからなくなったりします。グラフが拡大されて見にくい問題は引数にzoom = TRUEすることで拡大・縮小できるようにすることで対処できます。しかし、他の情報を表示するのにはこのsimpleNetwork関数は向いていません。
simpleNetwork関数
simpleNetwork(ns_D3$links, zoom = TRUE)もう少し情報を詰め込んだグラフを作成するための関数がforceNetwork関数です。この関数ではedgeのデータフレーム(Links引数)とnodeのデータフレーム(Nodes引数)を別に指定することができます。
この関数では、ネットワークの接続(edgelistに当たるもの)をSourceとTarget引数に、edgeの太さをValue引数に、ノードに表示される名前をNodeID引数に、色などのグループ分けをGroup引数に指定することで、比較的簡単に情報量の多いインタラクティブなグラフを作成することができます。
forceNetwork関数
forceNetwork(
Links = ns_D3$links,
Nodes = ns_D3$nodes,
Source = "source",
Target = "target",
NodeID = "name",
Group = "group",
fontSize = 30, zoom = TRUE
)dendroNetwork関数はネットワークではなく、階層ありクラスタリングの結果を表示するための関数です。引数に取れるのはhclust関数の返り値(hclustクラスのオブジェクト)だけです。dendroNetwork関数を用いることで簡単にインタラクティブな階層ありクラスタリングの結果を表示することができます。
networkD3には上記のforceNetwork、dendroNetworkの他にも円形・階層型のグラフを表示することができるradialNetwork関数やdiagonalNetwork関数、サンキー図を表示するsankeyNetwork関数も備わっています。以下の例ではjsonをjsonline::fromJSON関数でリストにして引数としていますが、sankeyNetwork関数は上記のforceNetworkと同様にedgeとnodeのデータフレームを引数に取ることもできます。
radialNetwork関数
# JSONのアドレスを読み込み
URL <-
"https://cdn.rawgit.com/christophergandrud/networkD3/master/JSONdata//flare.json"
# JSONをリストにする
Flare <- jsonlite::fromJSON(URL, simplifyDataFrame = FALSE)
# ネットワークを表示
radialNetwork(List = Flare, opacity = 0.9)diagonalNetwork関数
diagonalNetwork(List = Flare, opacity = 0.9)sankeyNetwork関数
# sankeyNetwork(サンキー図)
URL <-
"https://cdn.rawgit.com/christophergandrud/networkD3/master/JSONdata/energy.json"
# データはforceNetworkと同じように準備する(valueがlink側に必要)
Energy <- jsonlite::fromJSON(URL)
Energy$links |> head()
## source target value
## 1 0 1 124.729
## 2 1 2 0.597
## 3 1 3 26.862
## 4 1 4 280.322
## 5 1 5 81.144
## 6 6 2 35.000
Energy$nodes |> head()
## name
## 1 Agricultural 'waste'
## 2 Bio-conversion
## 3 Liquid
## 4 Losses
## 5 Solid
## 6 Gas
sankeyNetwork(Links = Energy$links, Nodes = Energy$nodes, Source = "source",
Target = "target", Value = "value", NodeID = "name",
units = "TWh", fontSize = 12, nodeWidth = 30)visNetwork(Almende B.V. and Contributors and Thieurmel 2022)はD3.jsとは異なるJavascriptのビジュアライゼーションライブラリであるvis.jsを用いたインタラクティブなネットワーク描画に関するパッケージです。上記のNetworkD3とは少し違う感じでネットワークが描画されるので、好みの方を用いるとよいでしょう。
パッケージの読み込み
pacman::p_load(visNetwork)visNetwork関数は、NetworkD3のforceNetwork関数に近い使い勝手の関数で、forceNetwork関数と同様にnodeとedgeのデータフレームを引数に取る関数です。ただし、forceNetwork関数が引数で色やnode名の指定を行うのに対し、visNetwork関数は引数に取ったデータフレームの列名に従ってネットワークを描画するという特徴があります。Rの他のグラフィックパッケージとは少し使い勝手が異なります。
nodeに指定するデータフレームにはidという名前の列が、edgeに指定するデータフレームにはfromとtoという名前の列が必要です。この列名を読み取って、visNetworkはグラフを描画します。
visNetwork関数
visNetwork関数にnodeとedgeを指定しただけでは、nodeをドラッグして位置を変えることができる程度で、nodeの情報などは表示されません。nodeをクリックしたときに表示される文字列はtitleという列名に指定します。また、nodeの色を変える場合には、nodeに指定するデータフレームにcolorという列が必要です。このtitleやcolorに指定された値・色を読み取って、visNetwork関数はnodeの情報を変更します。
nodeの情報を指定する
vt$title <- vt$id # nodeをクリックしたときに表示する文字
vt$color <- if_else(vt$company == "JR", "red", "blue") # nodeの色
visNetwork(nodes = vt, edges = d)また、visNetworkではパイプ演算子(%>%や|>)を用いてグラフの要素を追加することもできます。visNodes関数をパイプで繋ぐことでnodeの編集、visOptionsをパイプで繋ぐことでオプション設定の変更を行うこともできます。
パイプ演算子でグラフを編集する
visNetwork(nodes = vt, edges = d) |>
visNodes(shape = "square") |>
# クリックすると連結したノードがハイライトされる
visOptions(highlightNearest = TRUE)