論理型
TRUE
## [1] TRUE
FALSE
## [1] FALSE
T
## [1] TRUE
F
## [1] FALSE
c(T, F, T, F) # logicalはベクターにもできる
## [1] TRUE FALSE TRUE FALSE
1 < 3 # 3は1より大きいのでTRUE
## [1] TRUE
1 > 3 # 1は3より大きくないのでFALSE
## [1] FALSEプログラミングでは、ある条件のときはこの処理、別の条件のときはこの処理…、といった具合に、条件によって行う処理を変えたいことがよくあります。例えば、じゃんけんでは出した手の条件によって勝ち・負け・引き分けという3つの処理を行うことになります。このように、条件によって処理を変えることを、条件判断と呼びます。
条件として用いられるのは、論理型(logical)です。論理型はTRUE(真)とFALSE(偽)の2つの値を持ちます。論理型はそれそのものを用いる場合と、比較演算子の演算結果として得る場合があります。Rでは、TRUEをT、FALSEをFと表記することができます。
論理型
TRUE
## [1] TRUE
FALSE
## [1] FALSE
T
## [1] TRUE
F
## [1] FALSE
c(T, F, T, F) # logicalはベクターにもできる
## [1] TRUE FALSE TRUE FALSE
1 < 3 # 3は1より大きいのでTRUE
## [1] TRUE
1 > 3 # 1は3より大きくないのでFALSE
## [1] FALSE論理型は、Rの内部では数値として取り扱われています。RではTRUEは1、FALSEは0と同一です。ですので、ベクター中のTRUEの数を足し算で計算することができます。また、0以外がTRUE、0がFALSEとして扱われる場合もあります。条件判断では0をFALSEとして用いる場合もあります。
RではTRUEが1、FALSEが0ですが、他の言語ではFALSEが-1のものもあります。言語によりTRUE/FALSEの仕様は異なります。
3章で説明した通り、比較演算子とは、演算子の右と左を比較して、その関係が正しい(TRUE)のか、間違っているのか(FALSE)を返す演算子です。Rで利用できる比較演算子は以下の表の通りです。
| 比較演算子 | 比較演算子の意味 |
|---|---|
| == | 等しい |
| != | 等しくない |
| < | 小なり |
| <= | 小なりイコール |
| > | 大なり |
| >= | 大なりイコール |
比較演算子
1 == 1 # 等しいのでTRUE
## [1] TRUE
1 == 2 # 等しくないのでFALSE
## [1] FALSE
1 != 1 # 等しいのでFALSE
## [1] FALSE
1 != 2 # 等しくないのでTRUE
## [1] TRUE
1 < 2 # 1は2より小さいのでTRUE
## [1] TRUE
1 < 1 # 1は1より小さくないのでFALSE
## [1] FALSE
1 <= 2 # 2は1より小さいのでTRUE
## [1] TRUE
1 <= 1 # 1は1に等しいのでTURE
## [1] TRUE
3 > 2 # 3は2より大きいのでTRUE
## [1] TRUE
2 > 2 # 2は2より大きくないのでFALSE
## [1] FALSE
3 >= 2 # 3は2より大きいのでTRUE
## [1] TRUE
2 >= 2 # 2は2と等しいのでTRUE
## [1] TRUE論理型は、論理演算子による計算に使うことができます。論理演算子とは、論理型のオブジェクト2つ以上を用いた演算(論理演算)を行うために用いるものです。
論理演算として主要なものは、論理和(AとBのどちらか片方がTRUEならTRUE、どちらもFALSEならFALSE)、論理積(AとBのどちらもTRUEならTRUE、どちらかがFALSEならFALSE)、否定論理和(AとBのどちらかがTRUEならFALSE、どちらもFALSEならTRUE)、否定論理積(AとBのどちらもTRUEならFALSE、どちらかがFALSEならTRUE)、排他的論理和(AとBのどちらかがTRUEならTRUE、両方がFALSEまたはTRUEならFALSE)などで、これらを用いることで論理型を用いた様々な表現を行うことができます。
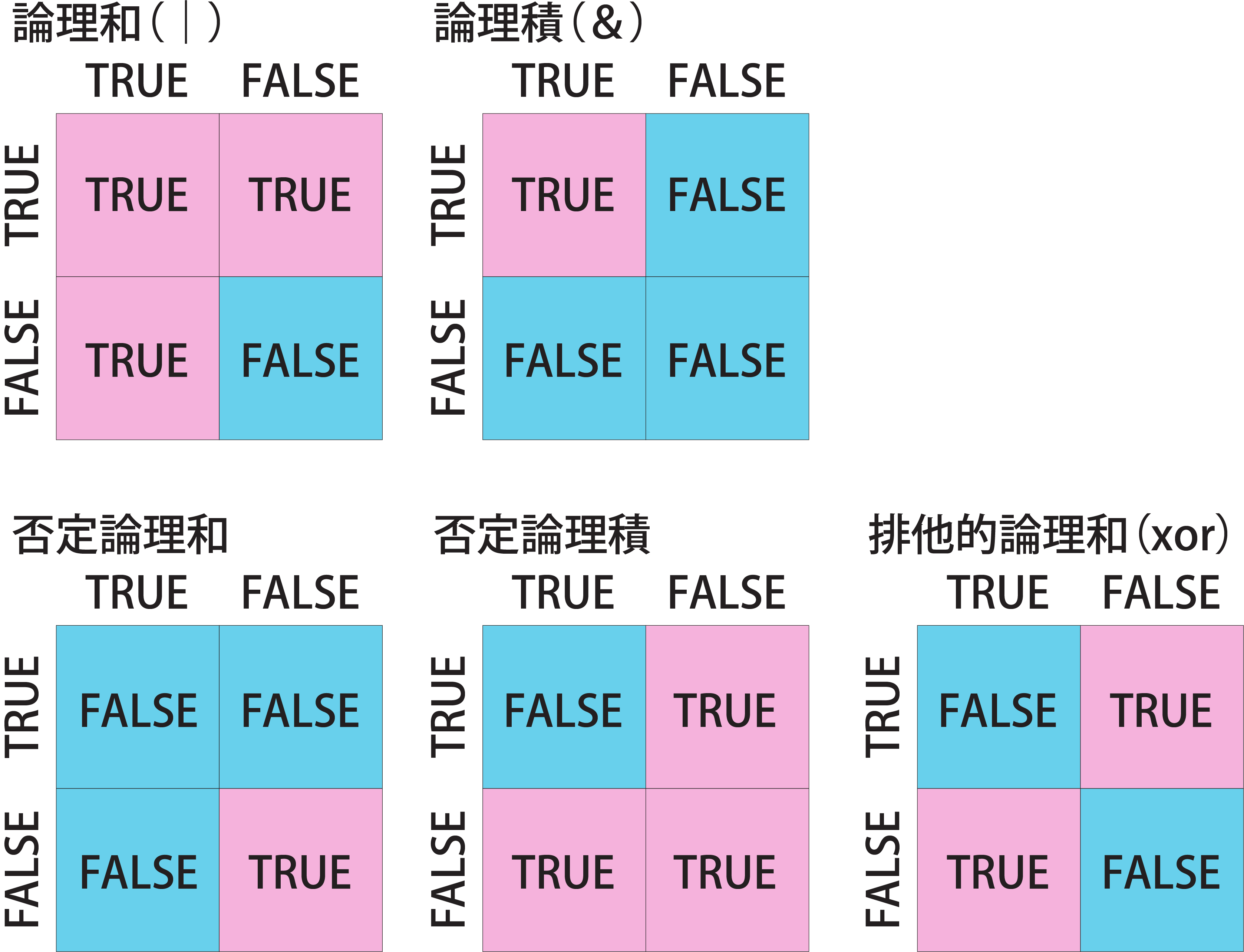
Rで最もよく用いられる論理演算子は&、|の2つです。&は論理積(A & BでAかB)、|は論理和(A | BでAまたはB)を示す演算子です。
この2つによく似た&&と||の演算子もありますが、これら2つはベクターの始めの値だけを評価するという特徴を持っています(Rのバージョン4.3以降では&&や||でベクターを比較するとエラーが出ます)。&&と||を用いるとプログラムが予想外の挙動を取ることがあるので、できるだけ&と|だけを用いたほうがよいでしょう。
| 論理演算子 | 演算子の意味 |
|---|---|
| & | 論理積(AかつB) |
| && | 論理積(ベクターの始めの要素のみ評価) |
| | | 論理和(AまたはB) |
| || | 論理和(ベクターの始めの要素のみ評価) |
| ! | 否定演算子(真偽を反転) |
| xor | 排他的論理和 |
| any | いずれかが真の時に真を返す |
| all | すべてが真の時に真を返す |
論理演算子による演算
logic1 <- c(T, F, T, F)
logic2 <- c(T, T, F, F)
logic1 & logic2 # & は論理積(AND)
## [1] TRUE FALSE FALSE FALSE
logic1 | logic2 # | は論理和(OR)
## [1] TRUE TRUE TRUE FALSE
# 比較する要素が1つでないとエラー
#(以前はインデックス1の要素のみを比較していた)
logic1 && logic2
## Error in `logic1 && logic2`:
## ! 'length = 4' in coercion to 'logical(1)'
logic1 || logic2
## Error in `logic1 || logic2`:
## ! 'length = 4' in coercion to 'logical(1)'RにはNAND(否定論理積)、NOR(否定論理和)などを表す専用の論理演算子はありませんが、XOR(排他的論理和)を表す関数(xor関数)はあります。また、要素のいずれか1つがTRUEならTRUEを返すany関数、すべてがTRUEの時だけTRUEを返すall関数などの関数も論理演算に用いることができます。
論理演算子として、!(エクスクラメーションマーク、否定演算子)も用いることができます。!は論理型の前に置くことで、論理型を反転(TRUEをFALSEに、FALSEをTRUEに)させます。
!による論理値の反転
!TRUE
## [1] FALSE
!FALSE
## [1] TRUE
!(1 < 3)
## [1] FALSE
!(1 > 3)
## [1] TRUE上記のように、比較演算子や論理演算子を用いると、論理型を得ることができます。この論理型に従い、行う処理を変えるものを、条件分岐と呼びます。条件分岐では、条件分岐の文(Control structures)というものが用いられます。Rでは、条件分岐の文として、if文とswitch文の2つが設定されています。
| 条件分岐 | 条件分岐の形式 |
|---|---|
| if文 | if(条件式){TRUEのときの演算}else{FALSEのときの演算} |
| ifelse関数 | ifelse(条件式, TRUEのときの演算, FALSEのときの演算) |
| switch文 | switch(評価する値, 評価の既定値=既定値のときの演算) |
if文は最もシンプルな条件分岐の文です。if文では、条件式に従い、実行する処理が変わります。Rでのif文は、以下の形を取ります。
if(条件式){TRUEのときに実施する処理}
条件式をif()のカッコの中に書きます。if文は1行で書くこともできますし、複数行に渡って書くこともできます。複数行に処理を書くときには、中括弧({})を条件式の後に書き、中括弧の中に処理を書きます。
if文の使い方
if(TRUE) "Hello R" # 1行で書く場合("Hello R"が返ってくる)
## [1] "Hello R"
if(FALSE) "Hello FALSE" # 条件式がFALSEなので、何も返ってこない
if(TRUE){ # 複数行で書く時には中括弧({})を用いる
"Hello R"
}
## [1] "Hello R"
if(FALSE){"Hello FALSE"} # 1行のif文で中括弧を使ってもよいif文の条件が0のときには、0がFALSEであると判断されて、処理が実行されません。一方で条件が0以外である場合には、TRUEであると判断されて処理が実行されます。if(0)とするとその処理が行われないので、Rではif(0)がコメントアウトに使われることもあります。
条件式が数値の時のif文
if(0){"0はFALSEなので、これは表示されません"}
if(-1){"-1はTRUE扱いなので、表示されます"}
## [1] "-1はTRUE扱いなので、表示されます"
if(-0.005){"0以外はTRUEとして処理されます"}
## [1] "0以外はTRUEとして処理されます"if文ではさらに条件を分岐させることもできます。条件を追加する場合には、if文の後に、else if()を繋げます。else if()のカッコの中に2つ目の条件を書くことで、条件を分離させることができます。elseだけを書いて、if()の条件式をつけない場合には、どの条件にも合わない時に実行する処理になります。ですので、if else文は以下の形を取ります。
if(条件式1){
式1がTRUEのときの処理
}else if(条件式2){
式1がFALSE、式2がTRUEのときの処理
}else{
式1、2がFALSEのときの処理
}
if else文
x <- 2 # xは2
# xは2なので、2番目の処理が返ってくる
if(x == 1){ # =が1つだと代入になるのでエラーが出る
"first"
} else if(x == 2){
"second"
} else {
"others"
}
## [1] "second"条件分岐が2つしかない場合には、ifelse関数を用いることもできます。ifelse関数は3つの引数、「(条件式)、(TRUEのときの処理)、(FALSEのときの処理)」を取ります。条件が1つだけで、簡単な処理のみを行うのであればifelse関数で十分な場合もあります。
条件式ではなく、特定の値に対応して処理を変えたい場合には、switch文を用います。switch文では、始めの引数が条件を指定する値、それに続く引数が条件に対応した処理となります。条件を指定する値には、数値または文字列を用いることができます。条件が数値の場合と文字列の場合では、やや使い方が異なります。
インストールしたばかりのRでは、上記のif文、if else文、ifelse関数、switch文しか使えませんが、パッケージというものを用いると、他の条件分岐(if_else関数やcase_which文、case_when文)を用いることもできます。詳細については20章で説明します。