1~100の整数からランダムに20個取り出す
sample(1:100, 20, replace=TRUE)
## [1] 7 46 82 49 84 17 62 39 9 52 23 89 34 72 26 56 92 96 9 38プログラミングでは、ランダムに生成された数値、乱数を使った処理を行うことがあります。例えばゲームなどで偶然性を表現する場合には、整数の乱数が用いられています。
Rで整数の乱数を得る時には、sample関数を用います。sample関数は数列のベクターから引数で指定した数だけ要素をランダムに取り出し、ベクターとして返す関数です。
1~100の整数からランダムに20個取り出す
sample(1:100, 20, replace=TRUE)
## [1] 7 46 82 49 84 17 62 39 9 52 23 89 34 72 26 56 92 96 9 38乱数は完全にランダムな数値というわけではなく、ランダムに見える繰り返し計算から生成されています(疑似乱数)。この疑似乱数を生成するアルゴリズムにはいろいろなものがあるのですが、Rではデフォルトの乱数生成アルゴリズムとして、メルセンヌ・ツイスター法(mersenne twister) (Matsumoto and Nishimura 1998) が用いられています。メルセンヌ・ツイスターは乱数生成アルゴリズムの中でも偏りのない乱数を得られるもので、現在ではExcelでも用いられています。
Rでの乱数生成アルゴリズムを確認、設定する場合には、RNGkind関数を用います。RNGkind関数を用いて乱数生成アルゴリズムを変更することもできますが、メルセンヌ・ツイスターから変更する必要は特にないでしょう。
乱数生成アルゴリズムの確認
# ?RNGkindで利用可能な乱数生成アルゴリズムの一覧を確認できる
RNGkind()
## [1] "Mersenne-Twister" "Inversion" "Rejection"乱数生成アルゴリズムは繰り返し計算で乱数を生成するため、乱数を生成するときに乱数の初期値(のようなもの)が必要となります。この乱数の初期値のことを乱数の種(seed)と呼びます。Rでは乱数の種をset.seed関数で指定することができます。乱数の種をある値に設定しておくと、乱数を何度生成しても同じ結果を得ることができます。乱数を用いた計算で統計を行う場合には、計算の再現性を保つためにseedを設定しておく方がよいでしょう。
sample関数では、第1引数として設定したベクターからある値が選択された後、その値をもう一度選択することができる場合(復元抽出)と、できない場合(非復元抽出)の設定をreplace引数で設定することができます。replace=TRUEの場合は復元抽出、replace=FALSEの場合は非復元抽出となります。非復元抽出の場合には、第1引数の長さ以上には値を呼び出すことはできません。replace引数のデフォルトはFALSEですので、replece引数を指定しない場合には非復元抽出が行われます。
また、統計では乱数を使った計算(モンテカルロ法)を用いることがあります。特に確率分布に従った乱数を用いた計算が統計では有用です。このような確率分布に従った乱数計算を行う場合には、sample関数ではなく、確率分布に関連した一連の関数を用いるのが一般的です。
確率分布とは、ランダムに起こる事象(例えばコイントスや身長・体重の大きさなど)がそれぞれの値を取る確率を関数の形で表現したものです。もっとも一般的に用いられている確率分布は、正規分布(Normal distribution)です。正規分布は平均値と標準偏差をパラメータとした確率分布で、平均値を取る確率が最も高く、平均値から離れるほど確率が低くなっていく、釣鐘型の形を取る分布です。
Rでは、この正規分布の確率密度、累積分布、分位点での値、乱数をそれぞれdnorm、pnorm、qnorm、rnorm関数を用いて計算することができます。
確率密度は上で述べた通り、ランダムに起こる事象がそれぞれの値を取る確率を示したものです。この確率密度は確率密度関数(離散的な分布では確率質量関数)という関数で表現されます。この確率密度関数を返すのが、「d + 分布の名前」で示される関数です。正規分布の確率密度関数は、dnorm関数で計算することができます。このdnorm関数は、mean引数で指定した平均値、sd引数で指定した標準編差の正規分布において、第一引数で指定した値(x)における確率密度を返す関数です。ただし、確率密度はその値が確率なのではなく、確率密度の積分が確率となりますので、このdnormの返り値は確率ではありません(ただし、確率質量分布、つまり離散的な分布では確率質量分布の返り値が確率となります)。
確率密度には連続的なものと離散的なものがあり、確率分布ごとに値を取りうる範囲があります。例えば正規分布は\(+\infty\)から\(-\infty\)の範囲の実数すべてを取ることができる連続的な分布です。別の分布、例えばポアソン分布は正の整数のみを取ることができる、離散的な分布となります。
正規分布の確率密度
dnorm(x = 1, mean = 0, sd = 1) # 正規分布の確率密度
## [1] 0.2419707確率分布f(x)はその積分が確率となる関数で表されます。確率は合計すると必ず1となるため、確率分布をその分布の範囲で積分すると1になります。また、積分すると1となることが確率分布であることの条件にもなります。
\[\int_{-\infty}^{\infty}f(x)dx=1\]
確率分布の平均値(\(E[f(x)]\))と分散(\(V[f(x)]\))は以下の積分で計算できます。
\[E[f(x)]=\int_{-\infty}^{\infty}x \cdot f(x)dx\]
\[V[f(x)]=\int_{-\infty}^{\infty}(x-\mu)^2 \cdot f(x)dx\]
また、分散は以下の式でも表すことができます。
\[V[X] = E[X^2] - (E[X])^2 \]
確率密度をx軸方向に積分して得られる関数のことを、累積分布関数と呼びます。上に述べた通り、確率密度を積分したものが確率となりますので、累積分布関数を用いると、正規分布する値がある一定の範囲を取る確率を計算することができます。Rで累積分布関数を返すのが、「p + 分布の名前」で示される関数です。
正規分布の累積分布関数は、pnorm関数で計算することができます。正規分布の累積分布関数では、正規分布する値が\(-\infty\)からその値までの範囲を取る確率が計算されるため、正規分布する値が第一引数qで指定した値以下となる確率を計算することになります。平均値をmean引数、標準偏差をsd引数で指定するのはすべてのnorm関数で共通しています。
正規分布の累積分布関数
pnorm(q = 1, mean = 0, sd = 1) # 正規分布の累積分布関数(q(1)以下となる確率)
## [1] 0.8413447
# 平均0、標準偏差1の正規分布での標準偏差の区間(-1 ~ 1)の値が得られる確率
pnorm(1, mean = 0, sd = 1) - pnorm(-1, mean = 0, sd = 1)
## [1] 0.6826895
# 平均0、標準偏差1の正規分布で、-1.96~1.96の値が得られる確率(95%区間)
pnorm(1.96, mean = 0, sd = 1) - pnorm(-1.96, mean = 0, sd = 1)
## [1] 0.9500042
# 累積分布関数の形(正規分布)
plot(seq(-3, 3, by = 0.1), pnorm(seq(-3, 3, by = 0.1)), type = "l")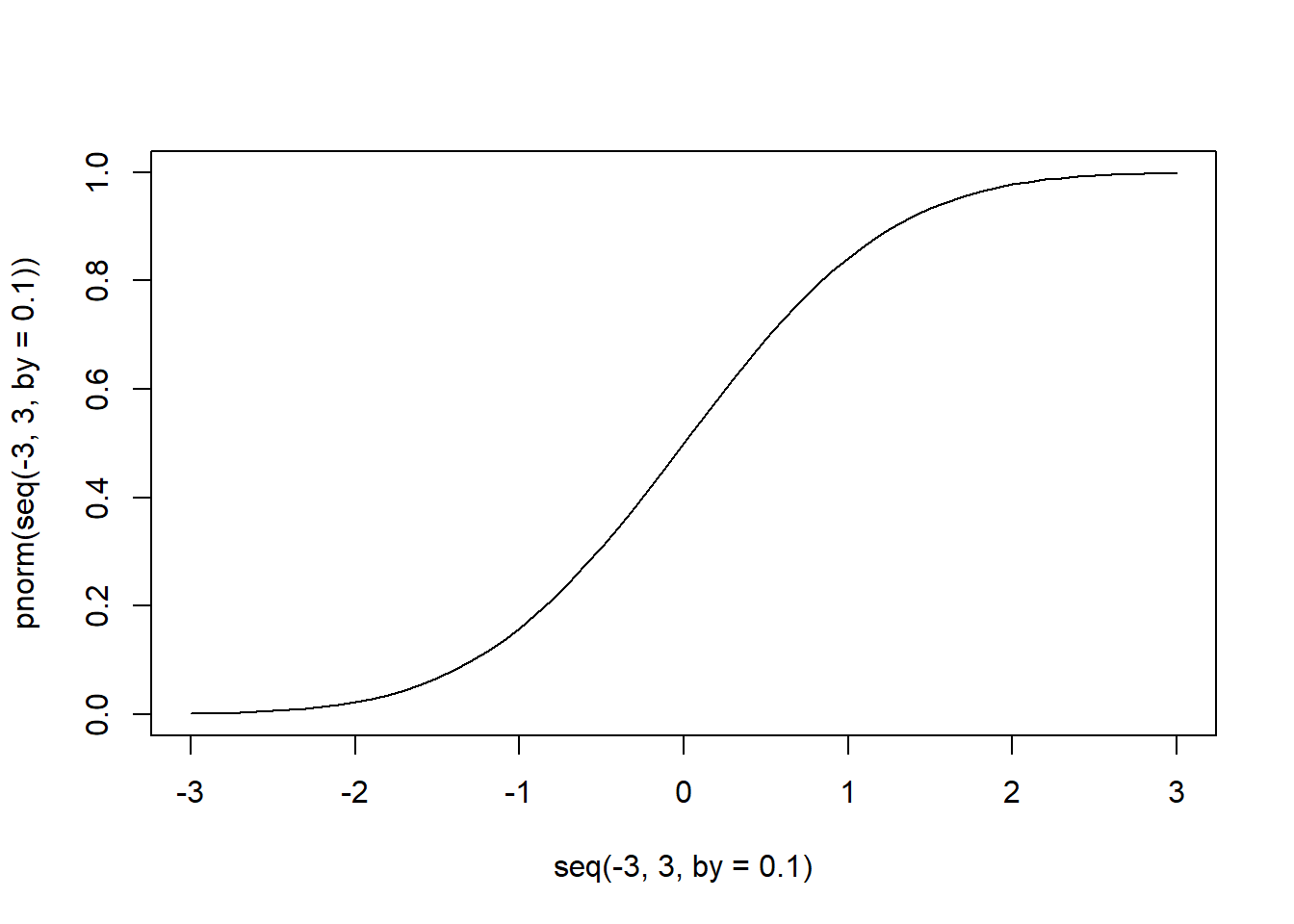
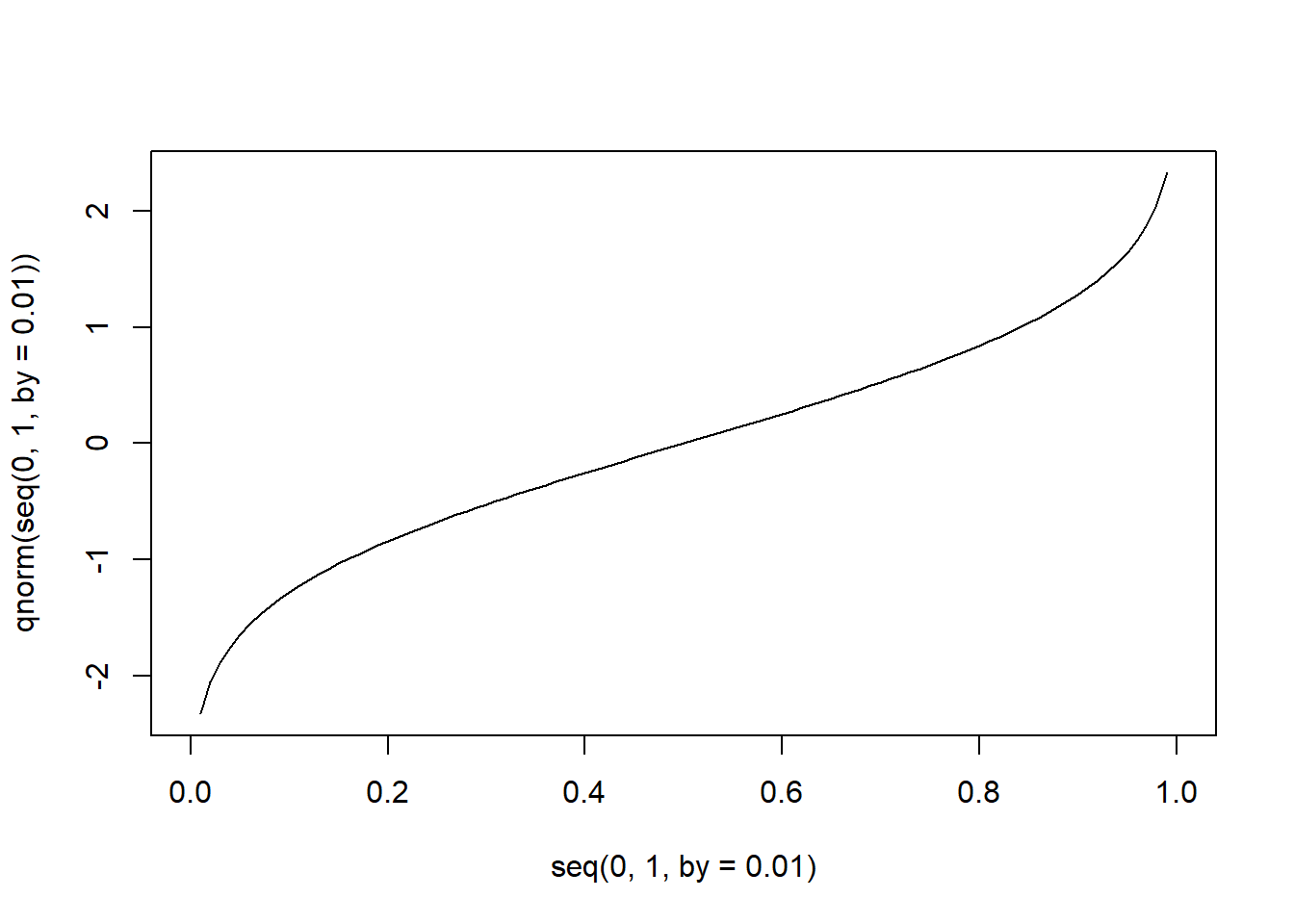
逆に、累積分布関数で求まる確率から、その確率となる値を求める関数が、「q + 分布の名前」で示される関数です。第一引数であるpには確率(0~1)を指定し、その確率が得られる累積分布関数でのx軸上の値を得ることができます。正規分布では、qnorm関数でこの計算を行うことができます。pnorm関数とqnorm関数では、第一引数と返り値の関係がちょうど逆になります。
引数pに対して、qnorm関数で得られる値のことを、「100*p%分位点」と呼ぶのが一般的です。p=0.25なら25%分位点、p=0.75なら75%分位点が得られることになります。
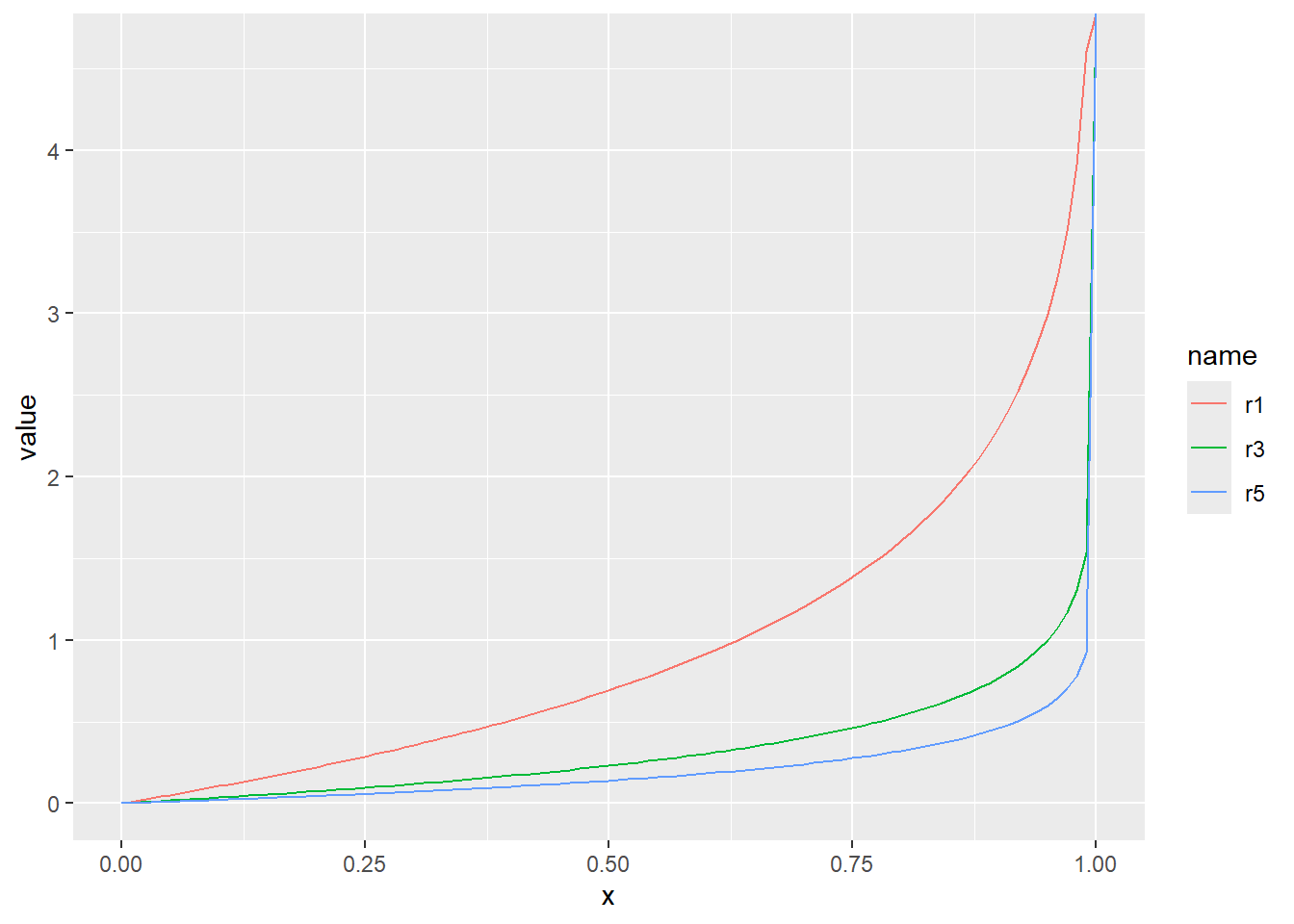
正規分布の分位点
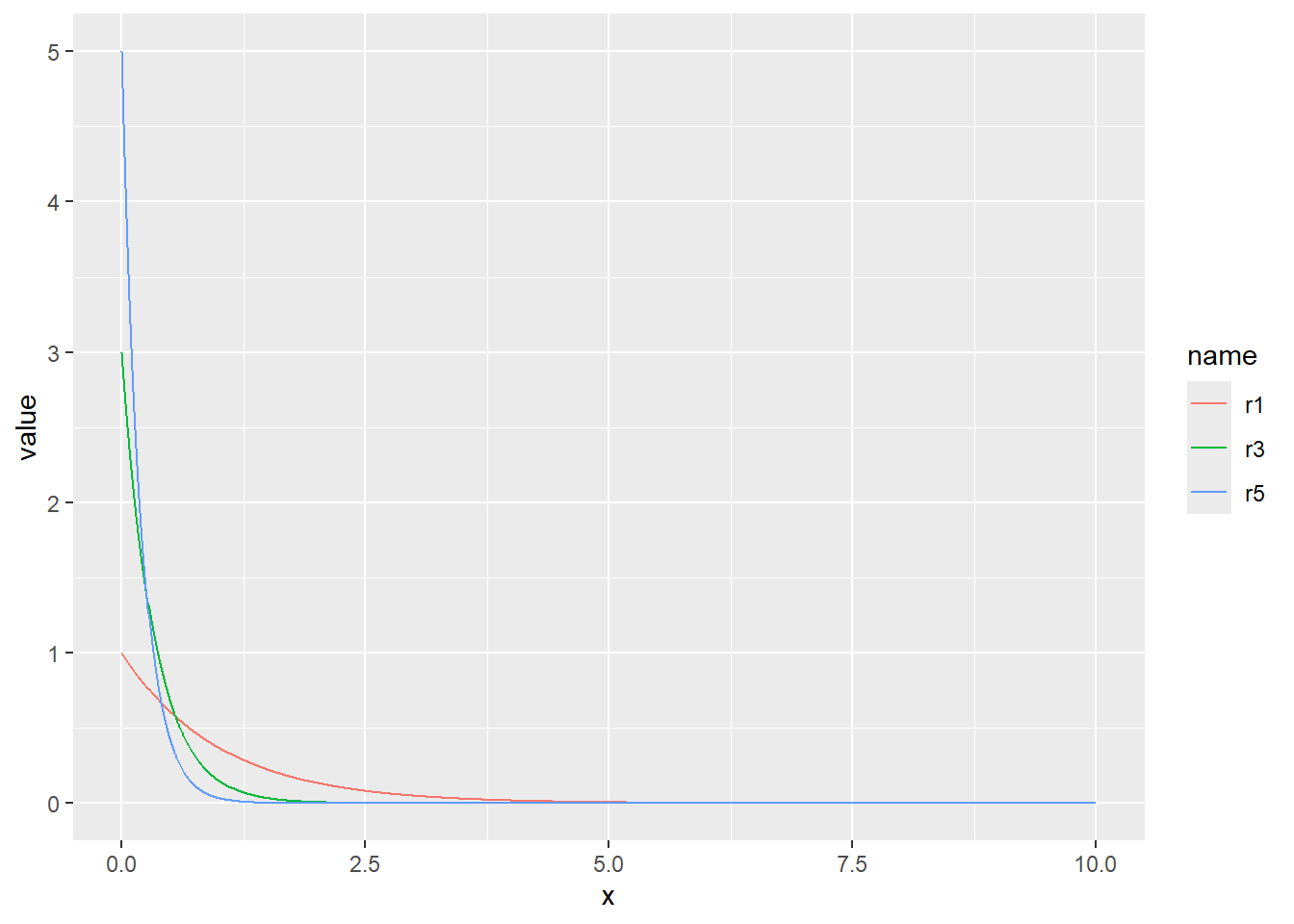
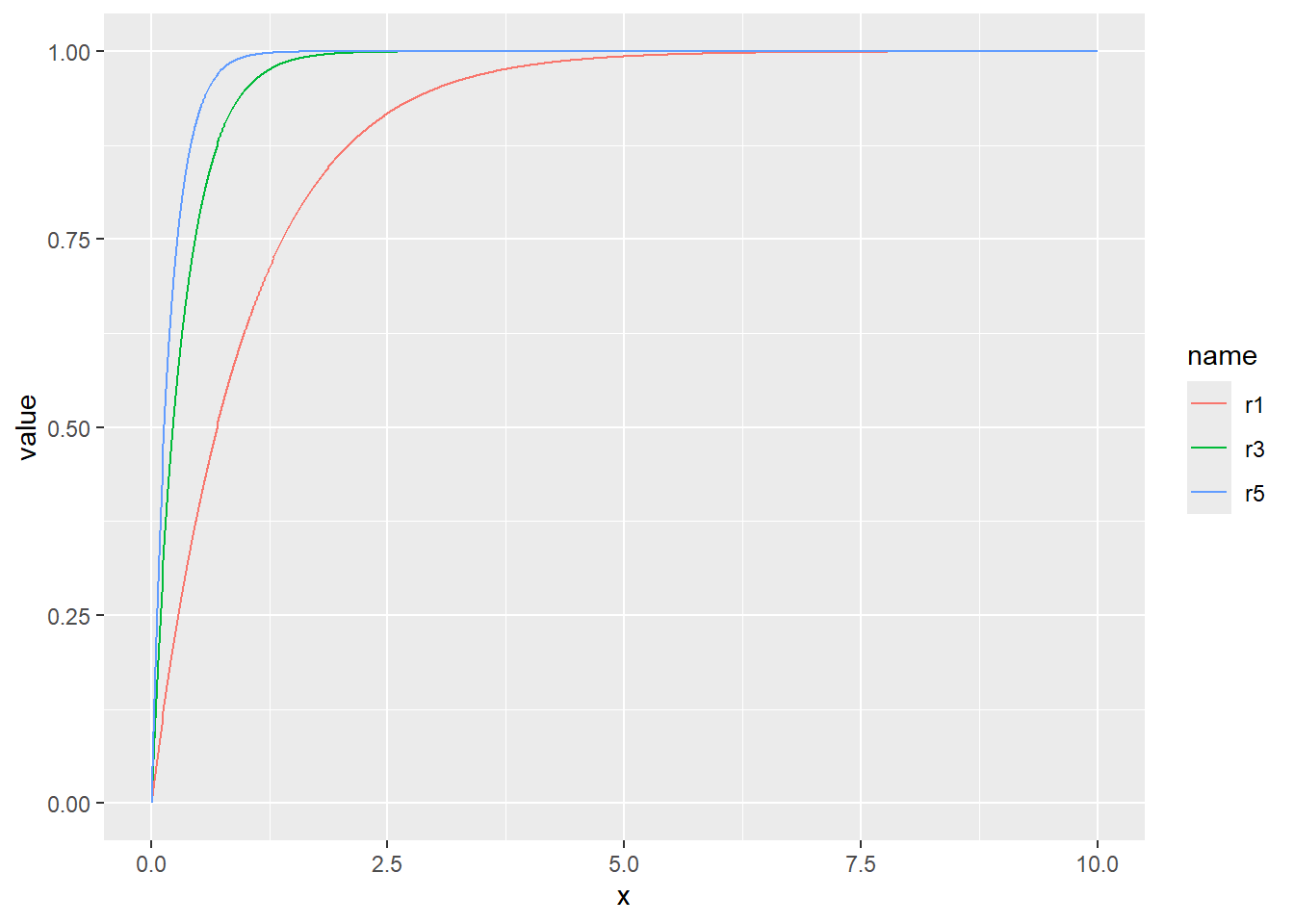
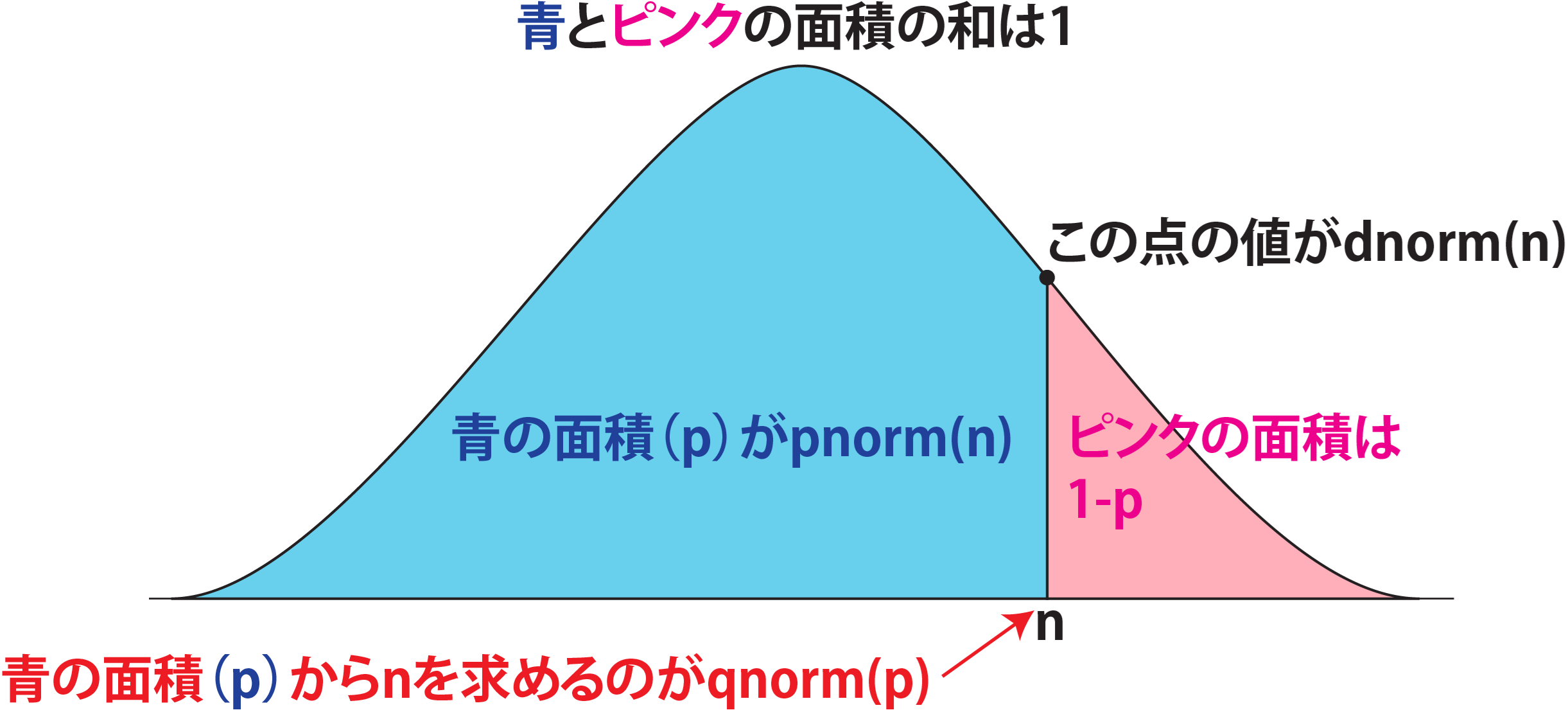
確率密度(dnorm)、累積分布(pnorm)、分位点(qnorm)の関係を図で示すと、以下のような関係になっています。
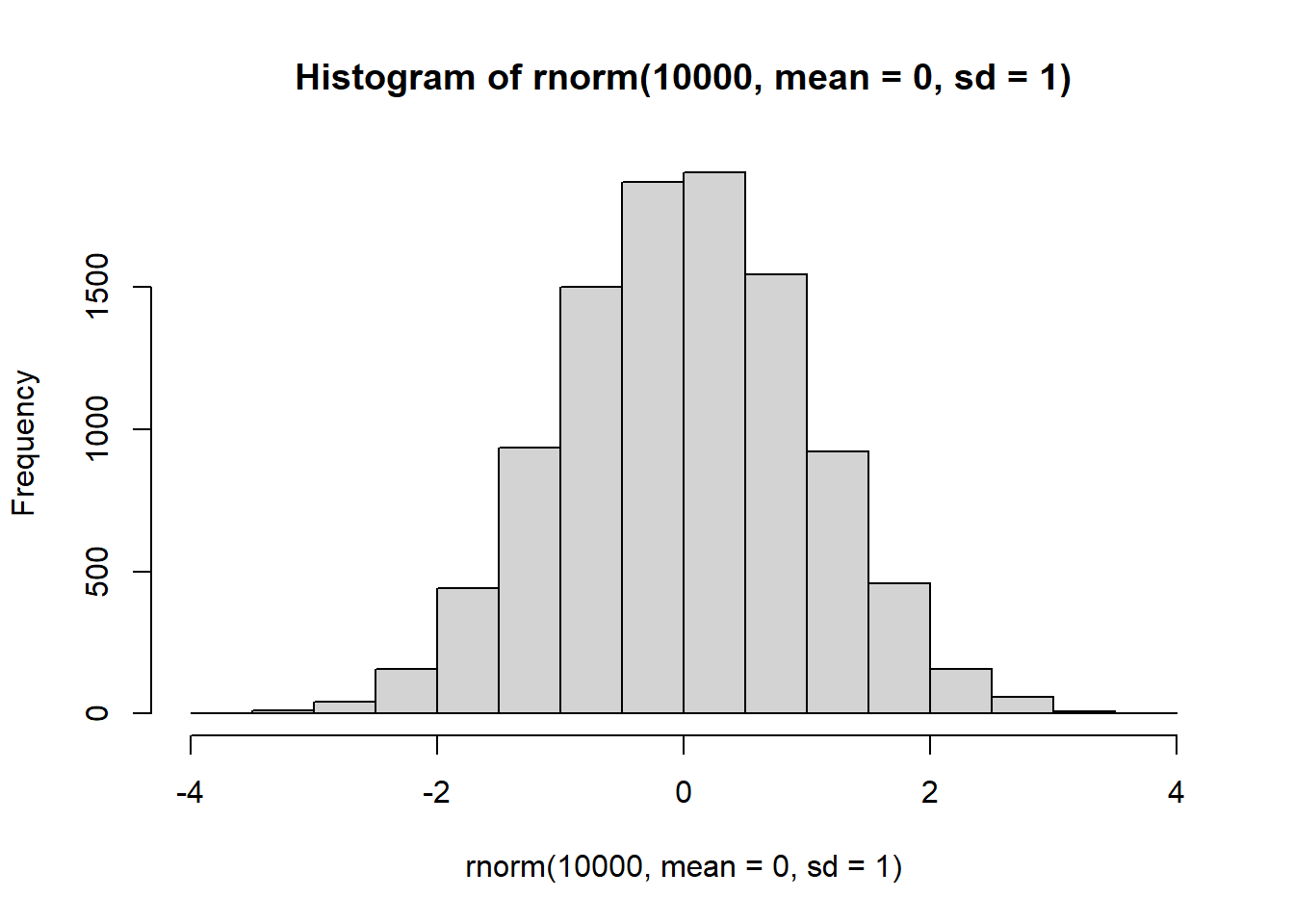
確率分布に従った乱数を得ることができれば、その確率分布に従う現象をシミュレートすることができます。Rで確率分布に従った乱数を求める関数が、「r + 分布の名前」で示される関数です。正規分布では、rnorm関数で乱数(正規乱数)を得ることができます。第一引数(n)で、乱数の個数を指定します。
正規分布の確率密度
通常、確率分布に従う形の乱数を得る場合には、累積分布関数の逆関数というものを用います。逆関数はy=f(x)の関数をx=g(y)という形に、xについて解いたものを指します。確率密度関数の逆関数に一様乱数を入れると、確率分布に従った乱数を得ることができます。rnormなどの乱数生成アルゴリズムはC言語で記載されていて、逆関数を用いているのかはわかりませんが、メルセンヌ・ツイスターで生成されるのは一様乱数ですので、内部的には同様の変換が行われているのだと思います。
Rでは、norm(正規分布)の他に、以下の表1で示す確率分布に関する関数が登録されています。各確率分布の「記号」の前にdを付けると確率密度関数、pを付けると累積分布関数、qを付けると分位点、rを付けると乱数を得る関数となります。
| 記号 | 分布 | 英語での分布名 | パラメータ |
|---|---|---|---|
| binom | 二項分布 | binomial | size, prob |
| geom | 幾何分布 | geometric | prob |
| hyper | 超幾何分布 | hypergeometric | m, n, k |
| nbinom | 負の二項分布 | negative binomial | size, prob |
| pois | ポアソン分布 | Poisson | lambda |
| norm | 正規分布 | normal | mean, sd |
| t | Studentのt分布 | Student’s t | df |
| cauchy | コーシー分布 | Cauchy | location, scale |
| logis | ロジスティック分布 | logistic | location, scale |
| lnorm | 対数正規分布 | log-normal | meanlog, sdlog |
| beta | ベータ分布 | beta | shape1, shape2 |
| chisq | カイ二乗分布 | chi-squared | df |
| f | F分布 | F | df1, df2 |
| gamma | ガンマ分布 | gamma | shape, scale |
| exp | 指数分布 | exponential | rate |
| weibull | ワイブル分布 | Weibull | shape, scale |
| unif | 一様分布 | uniform | min, max |
| multinom | 多項分布 | multinomial | size, prob |
上記の表1に示した以外にも、Rではパッケージを用いることで様々な確率分布の関数を用いることができます。パッケージの一覧に関しては、CRAN Task ViewのProbability Distributionsが参考になります。また、それぞれの確率分布の関係については、Univariate Distribution Relationshipsに詳しく記載されているので、興味のある方は一読するとよいでしょう。日本語では、こちらの三中先生の解説ページに書かれています。また、確率分布を表示するWebアプリを触ってみるのも良いでしょう。
以下に、各確率分布の簡単な説明と、各関数を用いたグラフを示します。
二項分布はベルヌーイ試行(コイントスのように、1と0だけが確率的に結果として得られる試行)の試行回数(size)と成功確率(prob、コイントスであれば表を成功として、表が出る確率)から、成功回数xが得られる確率を示したものです。二項分布の確率質量関数は以下の式で表されます。
\[Binom(x,n,p)=_{n}C_{x} \cdot p^{x} \cdot (1-p)^{n-x}\]
nが試行回数、pが成功確率、xが成功回数を表しています。Rでは、nをsize引数、pをprob引数で指定します。コイントスですので、整数でない成功回数(4.21回成功など)が起こることはありませんし、マイナスの試行数も取りません。ですので、二項分布は成功回数xが正の整数のみの離散的な確率分布になります。分布の範囲は0~試行回数です。
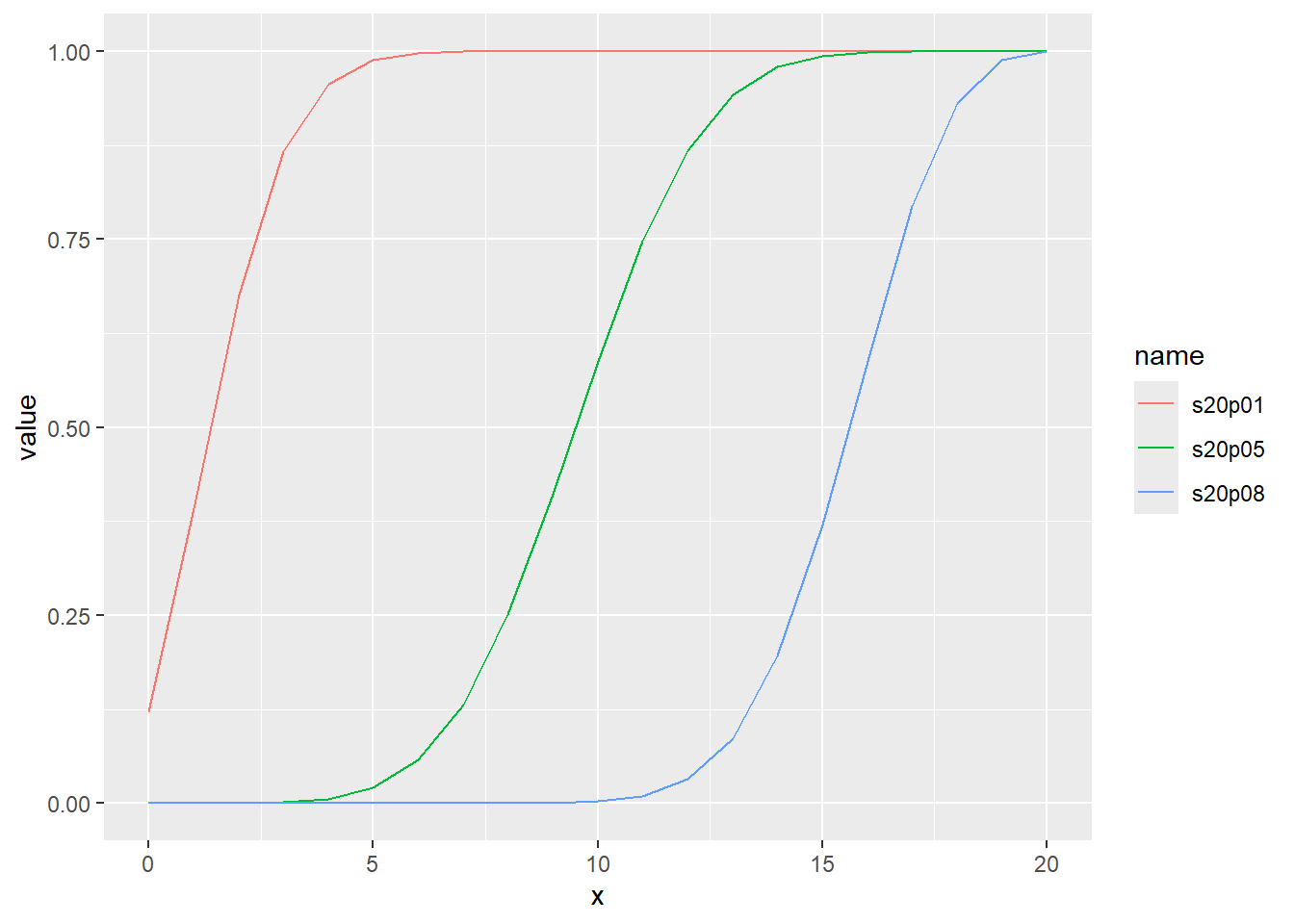
累積分布関数の分位点と値の関係をqbinomでプロット
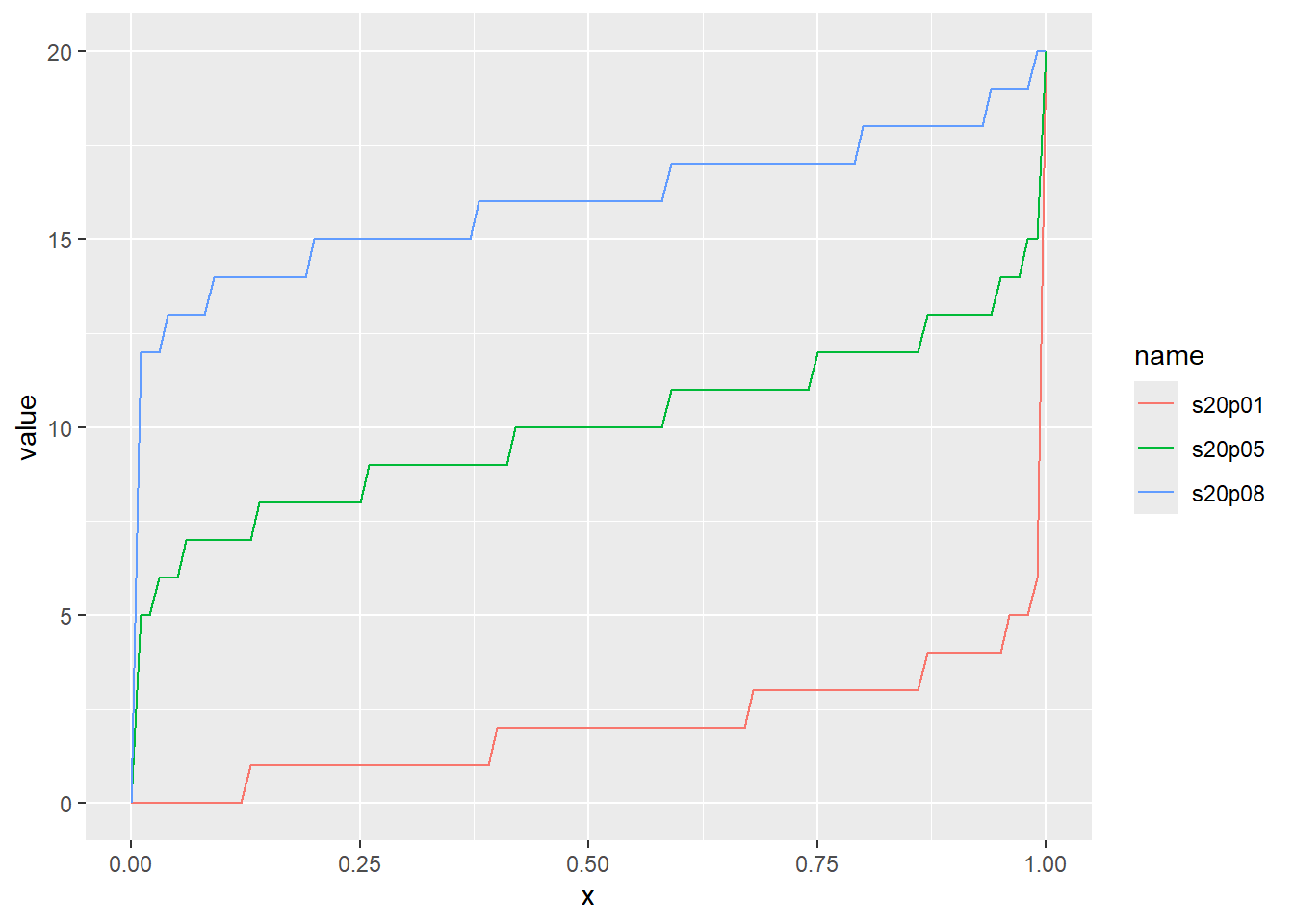
乱数のヒストグラムをプロット
d <- tibble(
s20p01 = rbinom(1000, size = 20, prob = 0.1), # サイズ20、確率0.1
s20p05 = rbinom(1000, size = 20, prob = 0.5), # サイズ20、確率0.5
s20p08 = rbinom(1000, size = 20, prob = 0.8) # サイズ20、確率0.8
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")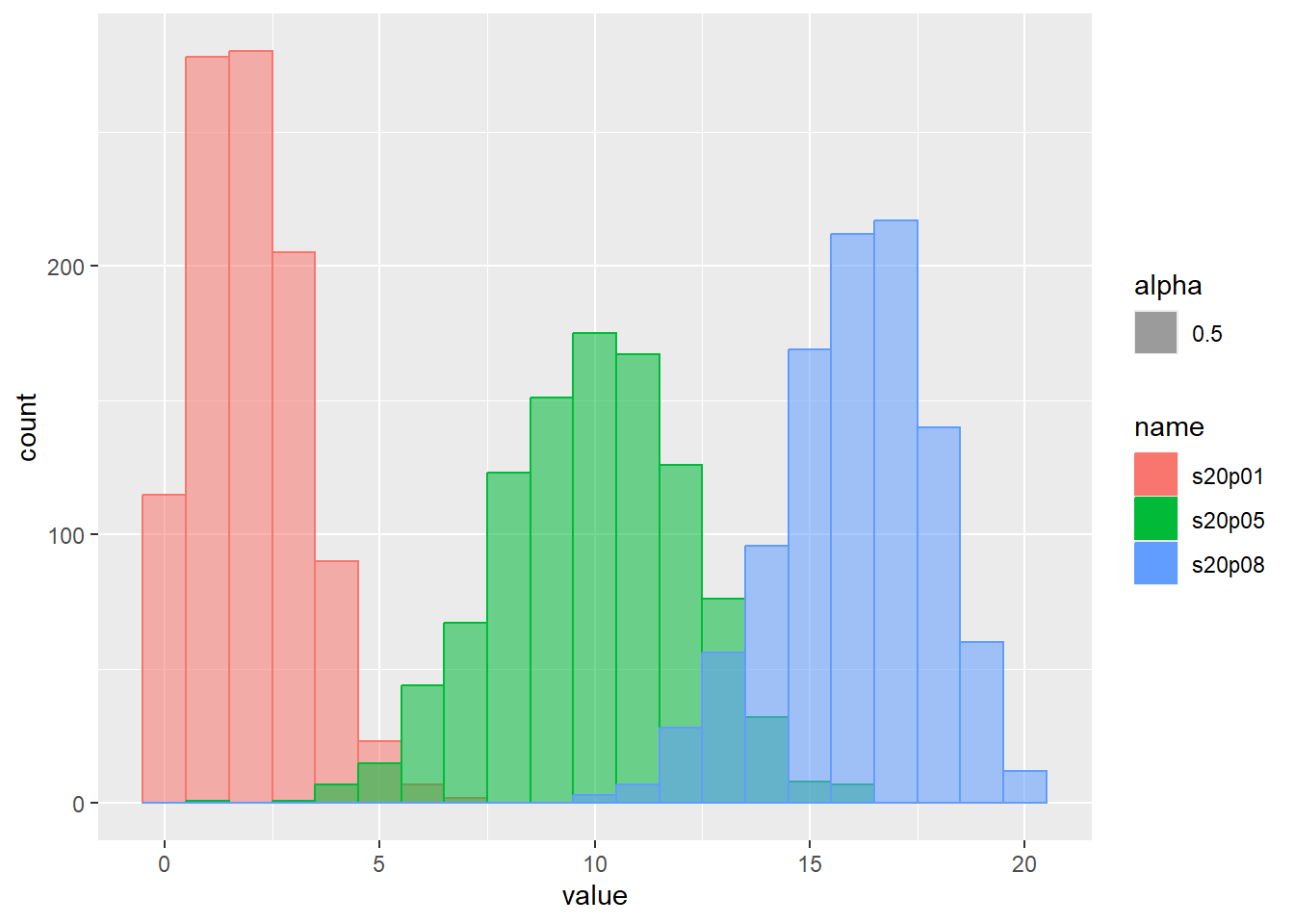
幾何分布は、ベルヌーイ試行を始めて成功させたときの試行数がxとなる確率を指します。二項分布との違いは、成功回数が必ず1回であるところになります。x以外には、成功確率(prob)のみをパラメータとして設定します。分布の範囲は0~\(+\infty\)です。幾何分布の確率質量関数は以下の式で表されます。
\[Geom(x,p)=p \cdot (1-p)^{x-1}\]
Rでは、pをprob引数で設定します。
1回成功するまでに失敗した回数も同じく幾何分布で表現することができます。失敗した回数とする場合には、上の式のx-1をxとするだけです。Rのgeom関数で計算されるのは上の式の結果です。
\[Geom(x,p)=p \cdot (1-p)^{x}\]
試行数xは必ず整数となるため、幾何分布も二項分布と同じく、離散的な分布で、xは正の整数を取ります。
超幾何分布は、ツボの中に白と黒のボールが入っていて、このツボからボールを取り出す試行(非復元抽出)を表現した確率分布です。超幾何分布の確率質量関数は以下の式で表されます。
\[ Hyper(x,m,n,k)= \frac{_{m}C_{k} \cdot _{n}C_{x-k}}{_{m+n}C_{x}}\]
Rのhyper関数では、白ボールm個、黒ボールn個が入ったツボからk個ボールを取ったとき、x個の白ボールが取れる確率を計算します。dhyper関数の引数はm、n、kで、xは整数のみを取る離散的な分布です。分布の範囲は0~kとなります。
超幾何分布の確率密度をプロット
x <- 1:6
d <- tibble(
x,
m5n5k5 = dhyper(x, m = 5, n = 5, k = 5), # 白 5, 黒 5, 取るボールの数 5
m10n5k5 = dhyper(x, m = 10, n = 5, k = 5), # 白 10, 黒 5, 取るボールの数 5
m5n20k10 = dhyper(x, m = 5, n = 20, k = 10) # 白 5, 黒 20, 取るボールの数 10
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()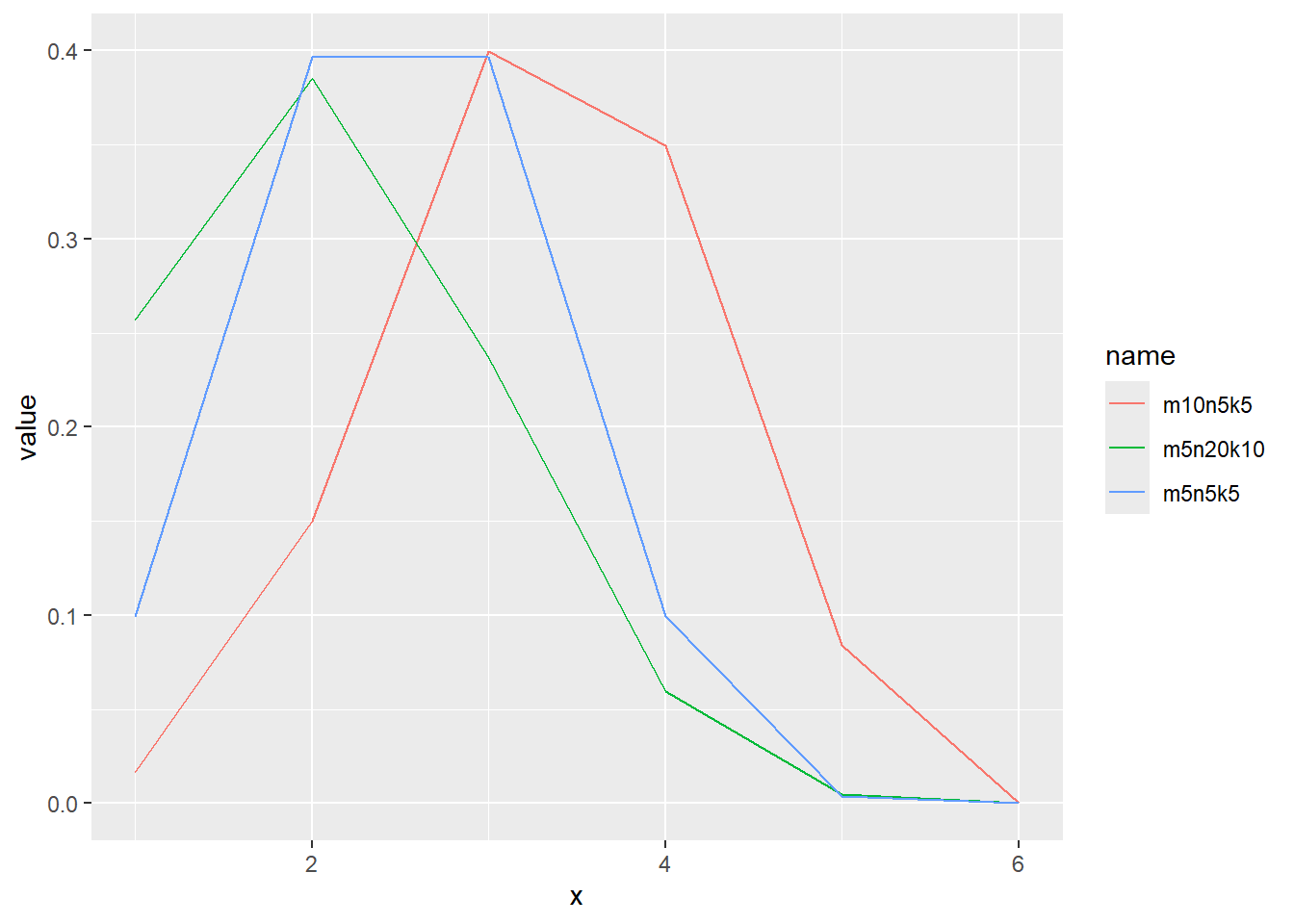
超幾何分布の累積分布関数をプロット
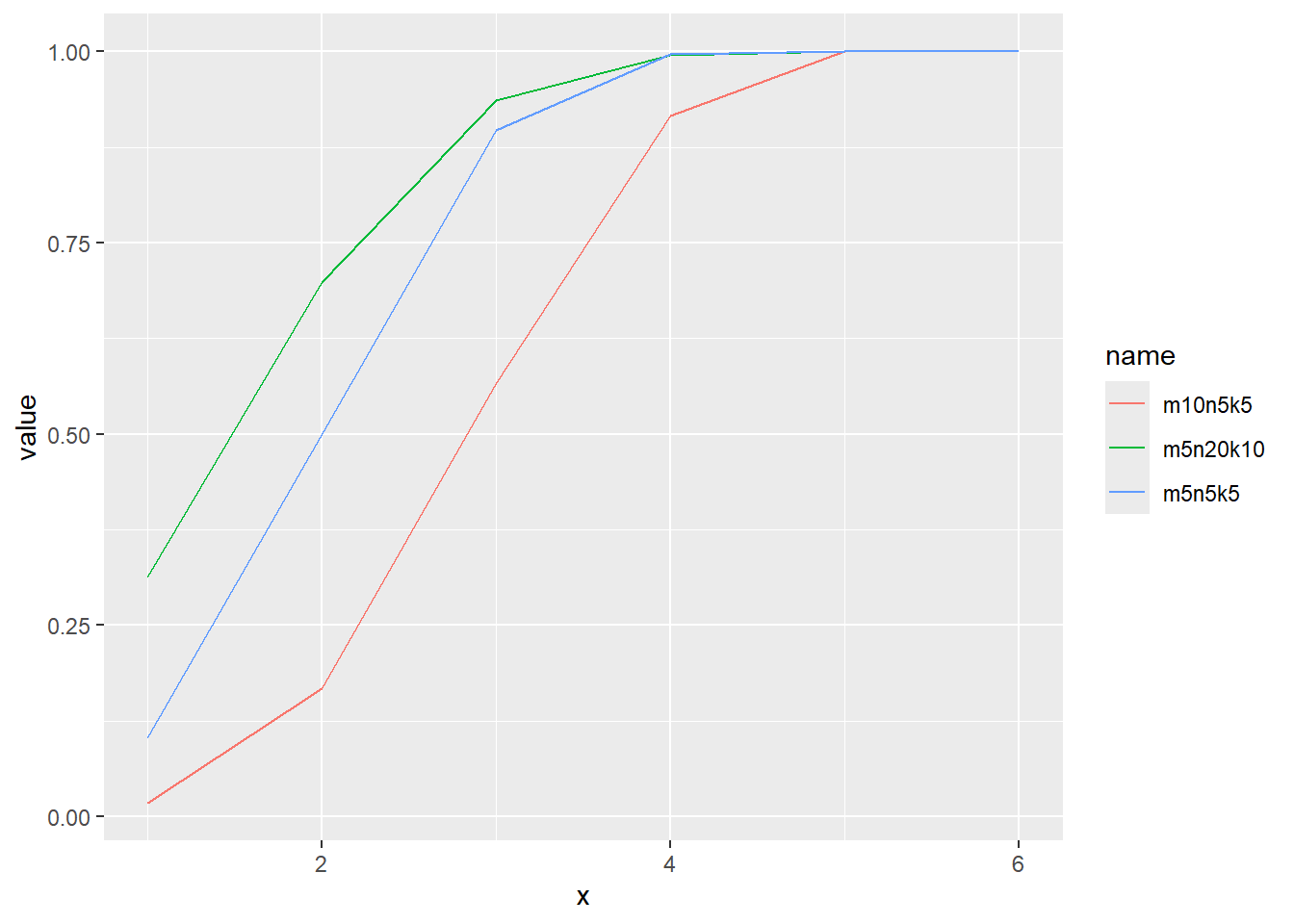
累積分布関数の分位点と値の関係をqfでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
m5n5k5 = qhyper(x, m = 5, n = 5, k = 5), # 白 5, 赤 5, 取るボールの数 5
m10n5k5 = qhyper(x, m = 10, n = 5, k = 5), # 白 10, 赤 5, 取るボールの数 5
m5n20k10 = qhyper(x, m = 5, n = 20, k = 10) # 白 5, 赤 20, 取るボールの数 10
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()
乱数の確率密度をプロット
d <- tibble(
m5n5k5 = rhyper(1000, m = 5, n = 5, k = 5), # 白 5, 赤 5, 取るボールの数 5
m10n5k5 = rhyper(1000, m = 10, n = 5, k = 5), # 白 10, 赤 5, 取るボールの数 5
m5n20k10 = rhyper(1000, m = 5, n = 20, k = 10) # 白 5, 赤 20, 取るボールの数 10
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 0.1, position = "identity")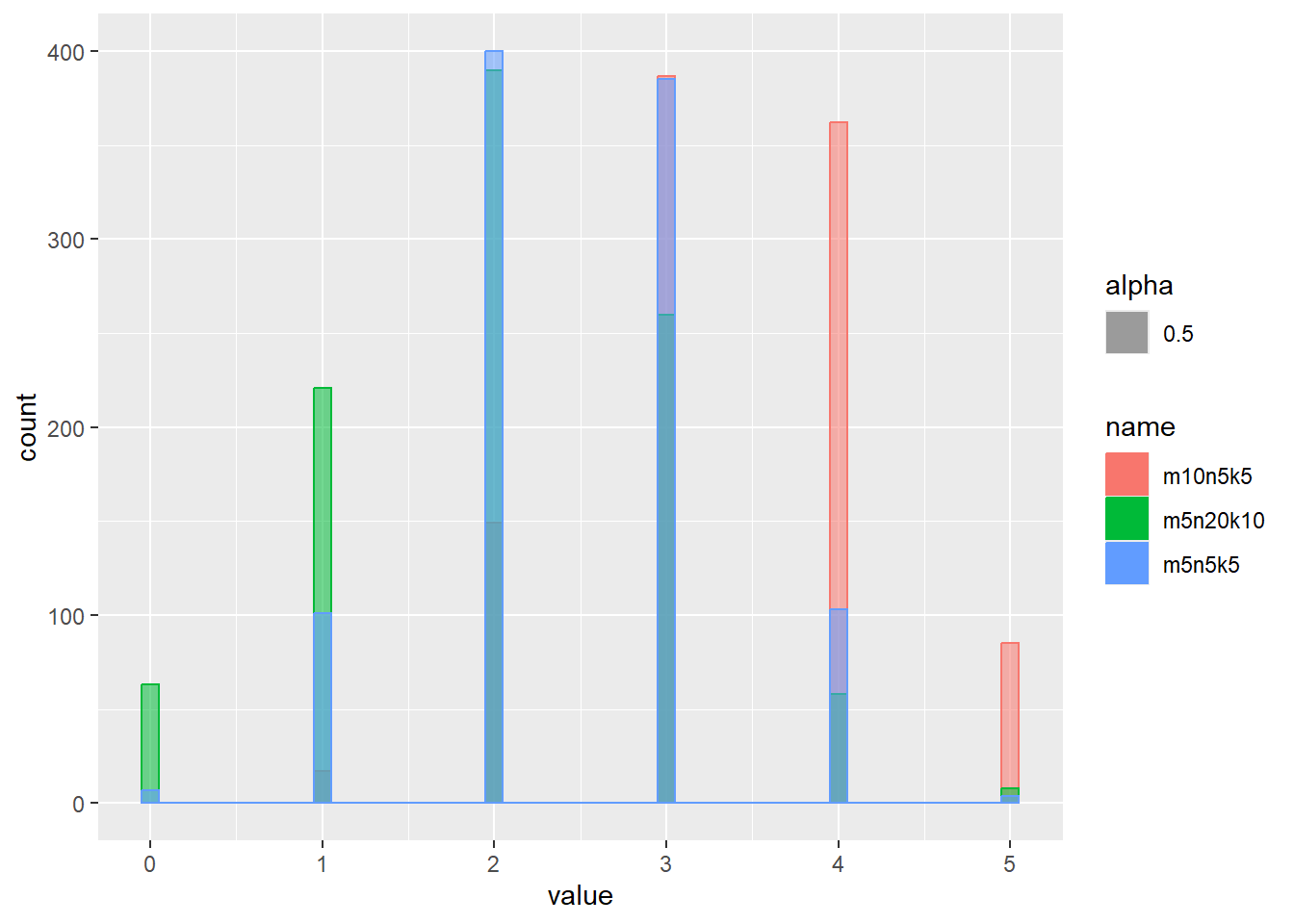
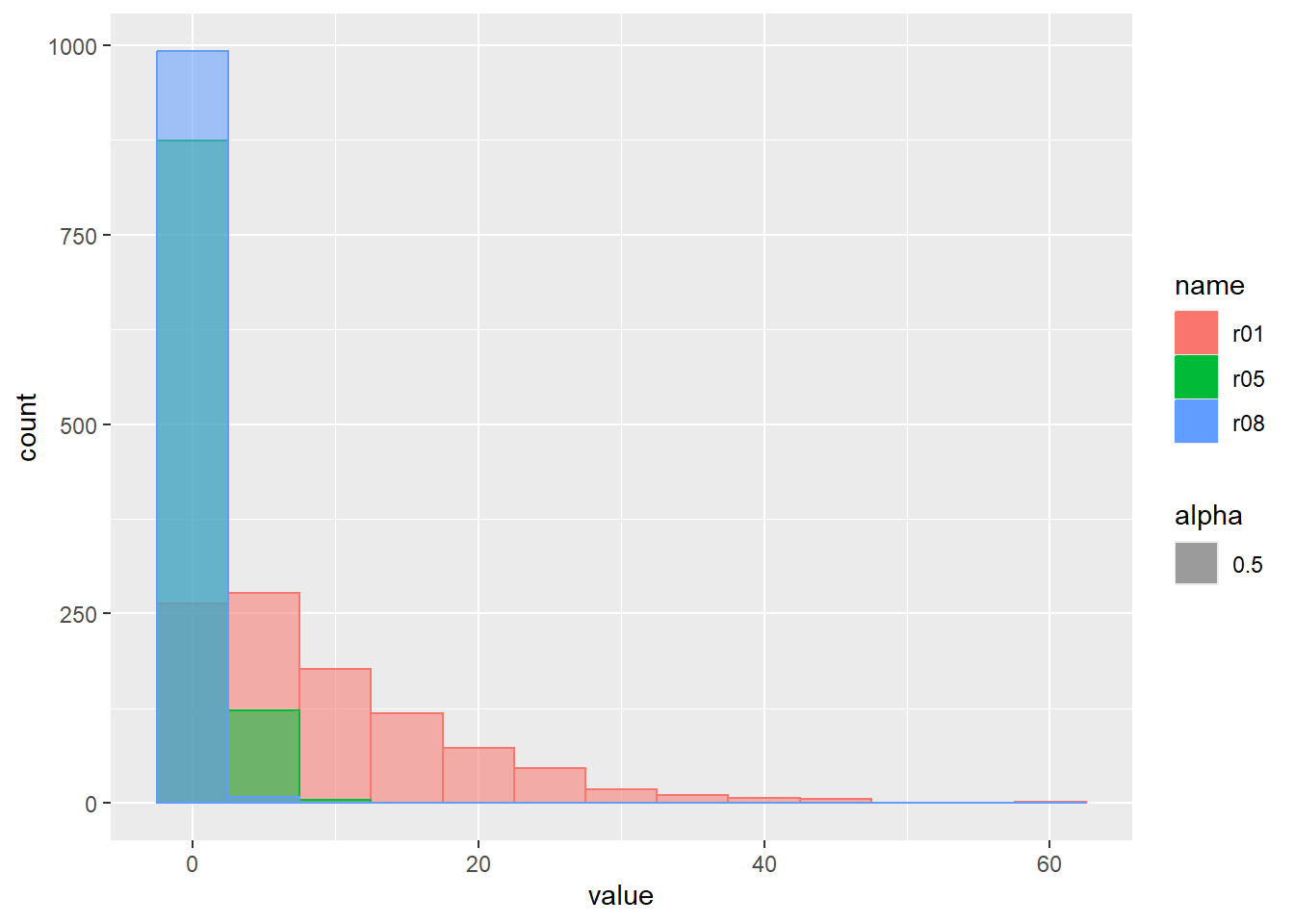
負の二項分布は、ベルヌーイ試行を行ったとき、n回成功する間にx回失敗する確率を反映した確率分布です。成功の回数がn、失敗回数をx、成功確率をpとしたとき、負の二項分布の確率質量関数は以下の式で表されます。
\[Nbinom(x,n,p)=_{x+n+1}C_{x} \cdot p^x(1-p)^n\]
Rでの負の二項分布の確率質量関数はdnbinom関数で計算することができます。成功の回数nはsize引数、成功確率pはprob引数で設定します。負の二項分布は正の整数のみを取る離散的な分布で、その範囲は0~\(\infty\)となります。
累積分布関数の分位点と値の関係をqfでプロット
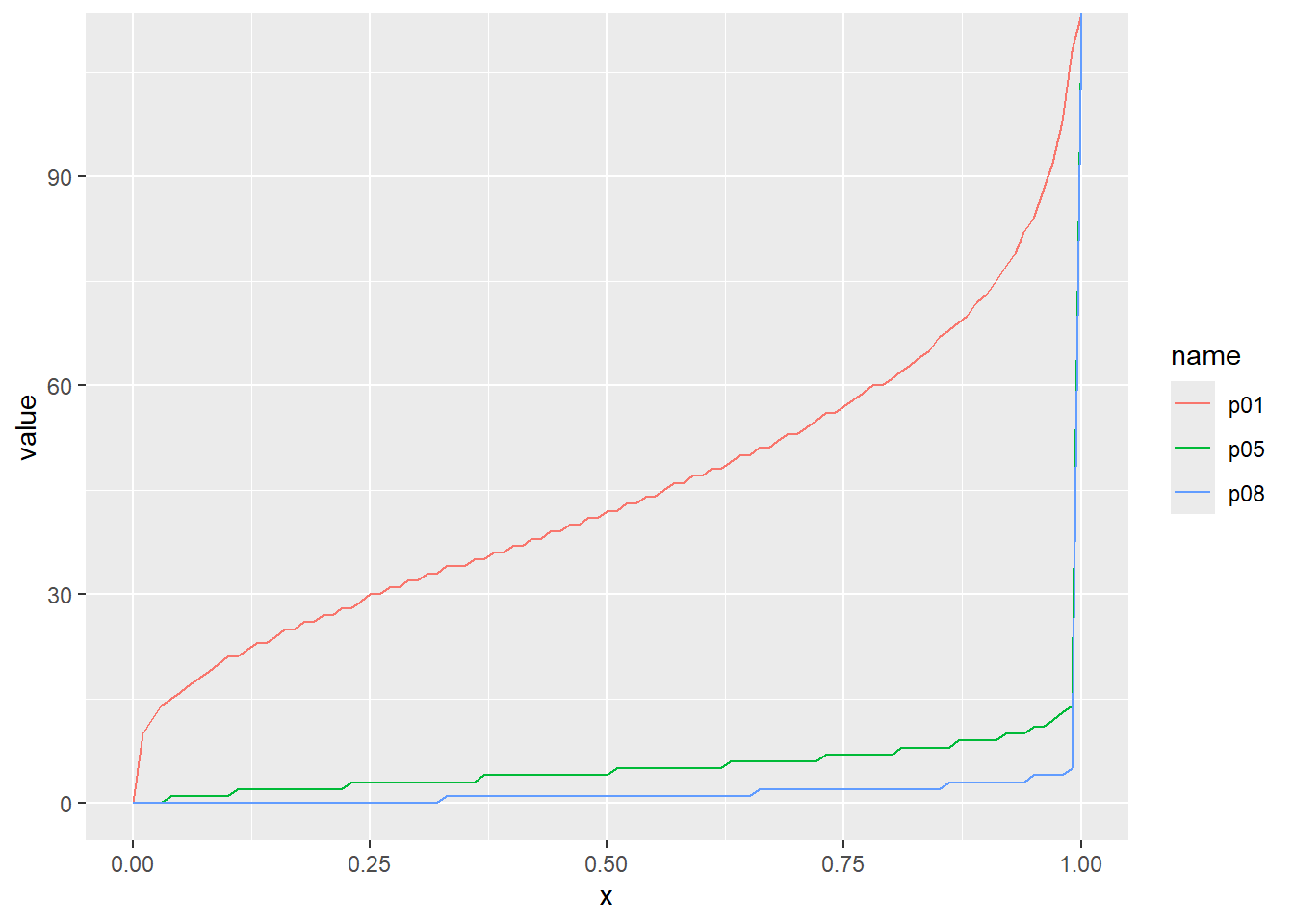
乱数の確率密度をプロット
d <- tibble(
p01 = rnbinom(1000, size = 5, prob = 0.1), # サイズ5、確率0.1
p05 = rnbinom(1000, size = 5, prob = 0.5), # サイズ5、確率0.5
p08 = rnbinom(1000, size = 5, prob = 0.8) # サイズ5、確率0.8
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 10, position = "identity")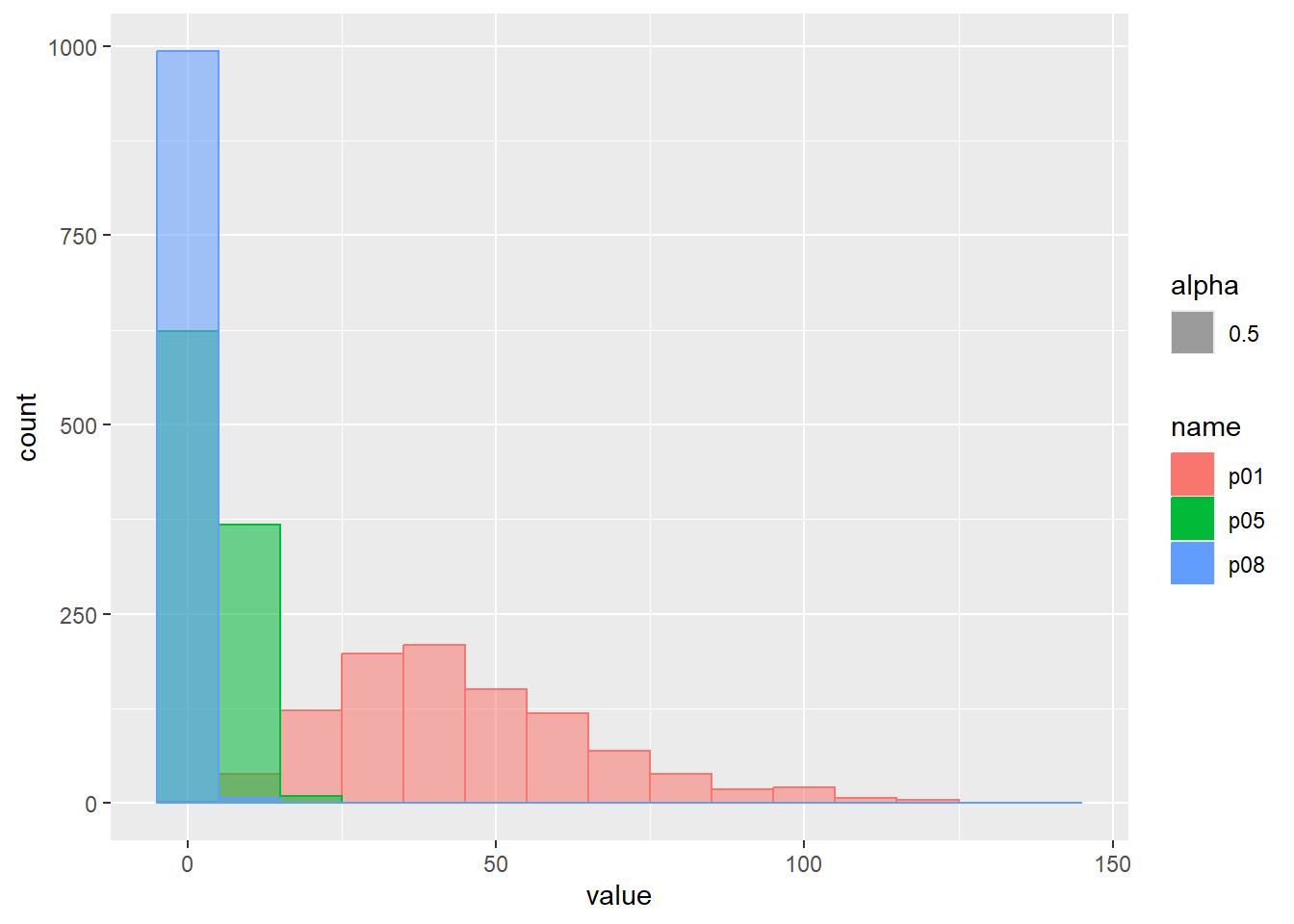
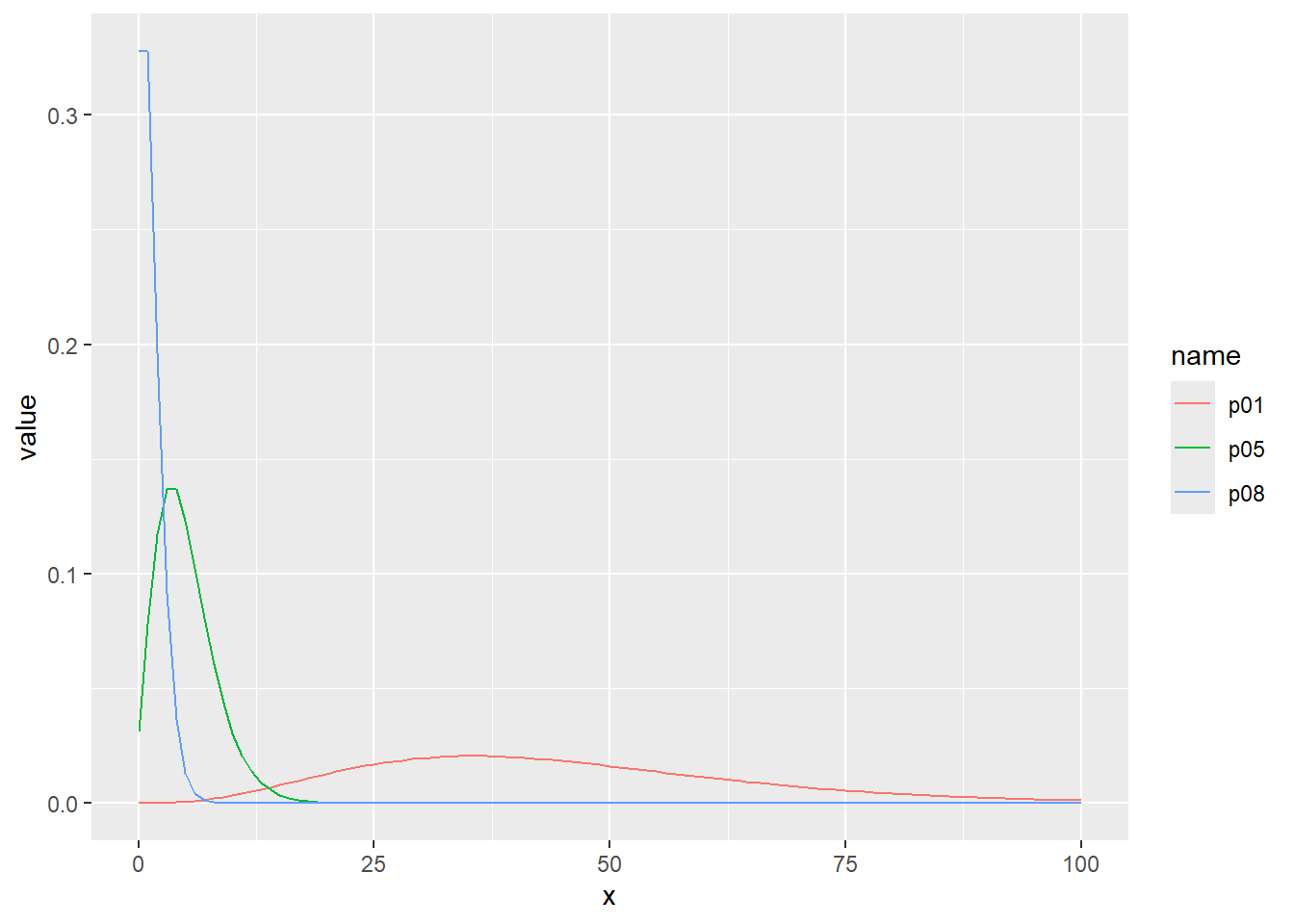
ポアソン分布は、起こる確率が非常に低い現象が、ある一定の時間に何回起こるかを確率として表した確率分布です。ポアソン分布の確率質量関数は二項分布の確率を0に、試行回数を\(\infty\)に近づけた極限として計算されます。ポアソン分布のパラメータはλのみで、ポアソン分布は平均値も標準偏差もλとなる特徴があります。ポアソン分布の確率質量関数は以下の式で表されます。分布が取りうる範囲は0~\(\infty\)となります。
\[Poisson(x, \lambda)=\frac{\lambda^x \cdot \exp(-\lambda)}{x!}\]
Rではポアソン分布の確率質量関数はdpois関数で計算することができます。dpois関数のλは引数lambdaで設定します。
正規分布は、様々な分布での値の平均値の分布を反映したもので(中心極限定理)、統計では最も一般的に用いられているものです。正規分布のパラメータは平均値(μ)と標準偏差(σ)です。正規分布の確率密度関数は以下の式で表されます。
\[ Norm(x, \mu, \sigma)=\frac{1}{\sqrt{2\pi \sigma^2}} \cdot \exp \left( \frac{(x-\mu)^2}{2\sigma^2} \right) \]
Rでは、正規分布の確率密度関数はdnorm関数で計算することができます。dnorm関数では、平均値はmean引数、標準偏差はsd引数で設定します。
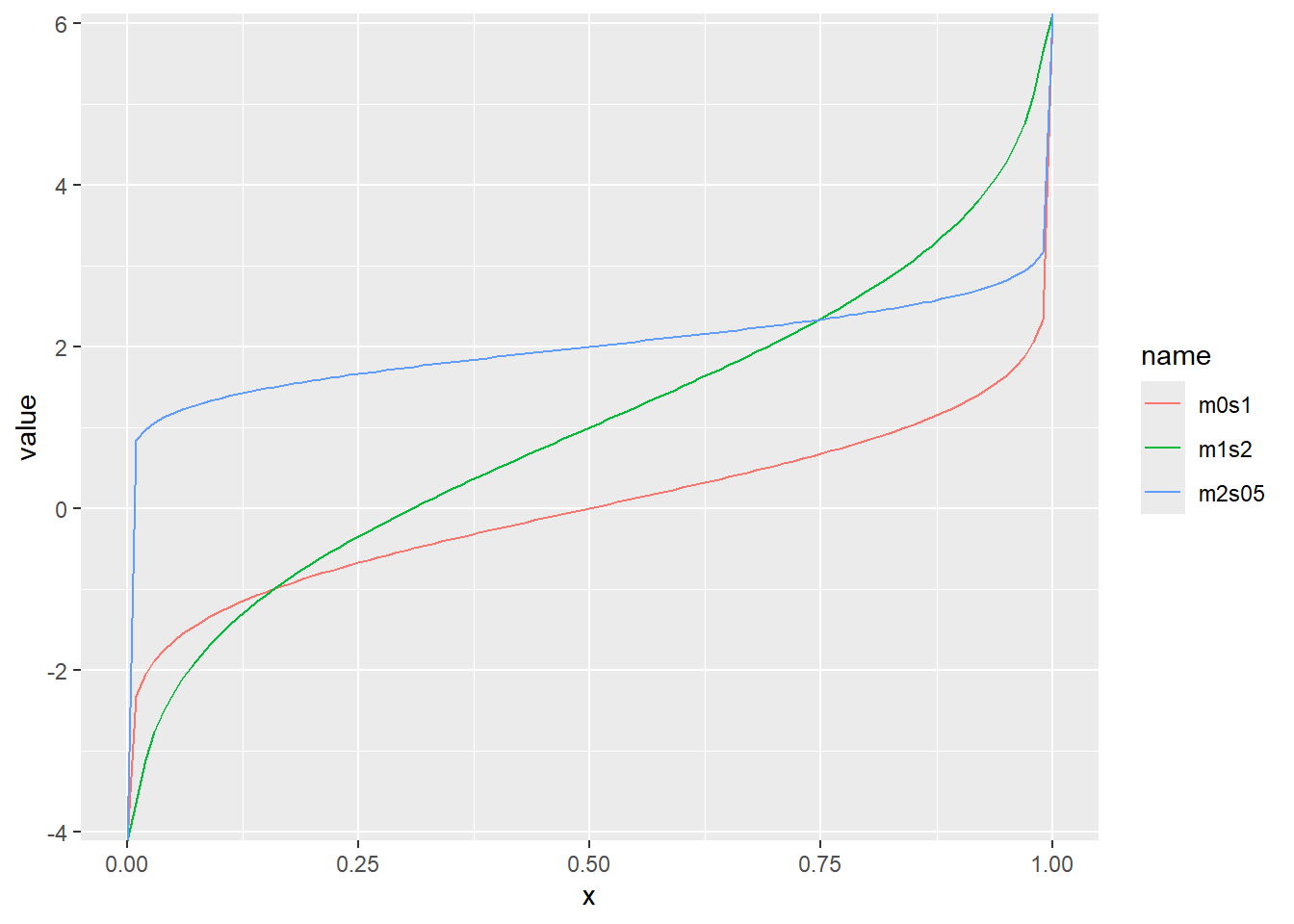
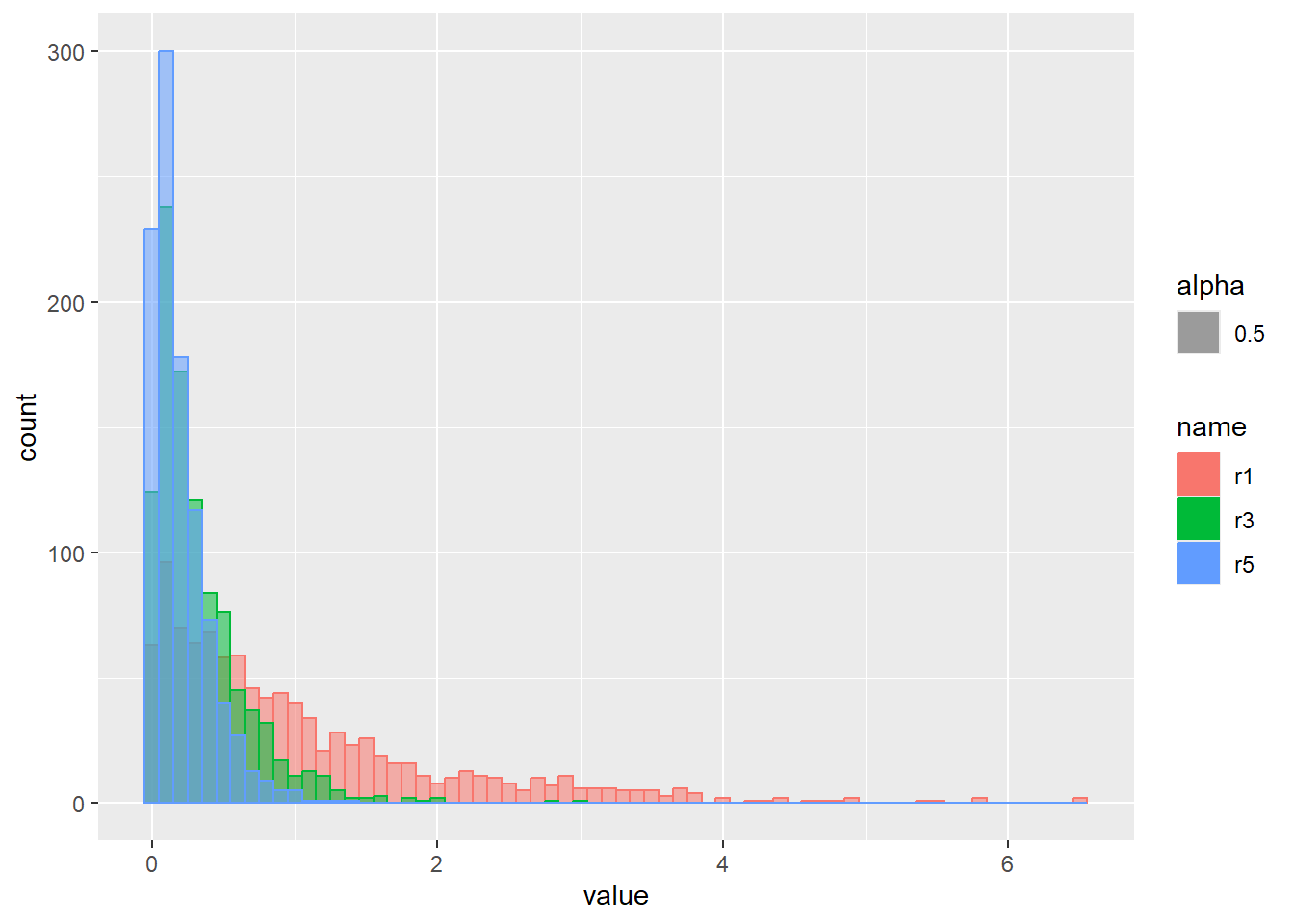
乱数の確率密度をプロット
d <- tibble(
m0s1 = rnorm(1000, mean = 0, sd = 1), # 平均0、標準偏差1
m1s2 = rnorm(1000, mean = 1, sd = 2), # 平均1、標準偏差2
m2s05 = rnorm(1000, mean = 2, sd = 0.5) # 平均2、標準偏差0.5
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")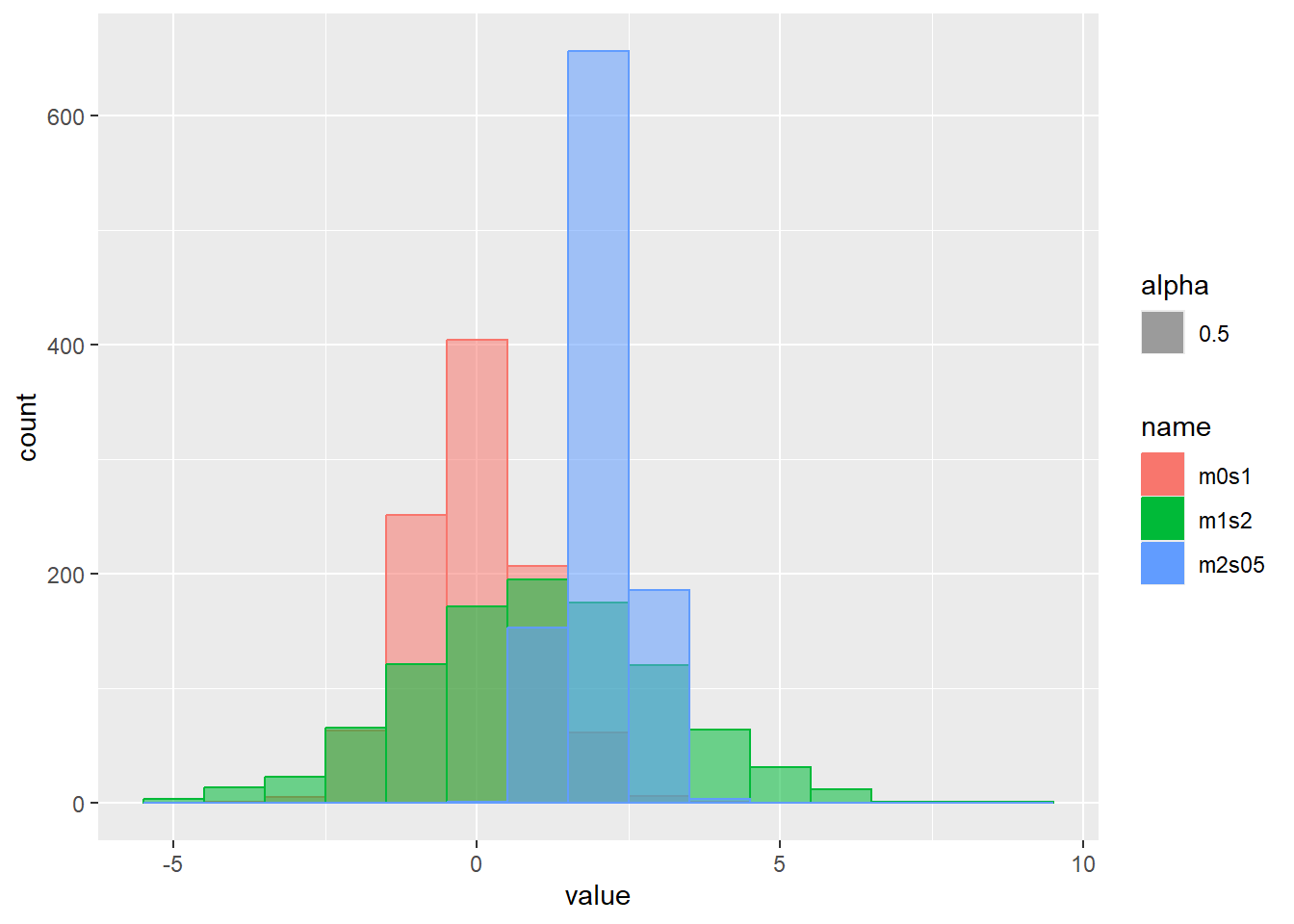
t分布は標本サイズが小さいときの母平均と標本平均の差の分布を反映した確率分布です。t分布はt統計量と呼ばれるものの分布を示します。t統計量は以下の式で計算できます。
\[t=\frac{x-\mu}{s/ \sqrt n}\]
この式で、xはサンプルの平均値、μは母平均値、sは標準偏差、nはサンプルの数を指します。t分布は主にt検定(平均値の差の検定)に用いられます。t分布の確率密度関数は以下の式で表されます。
\[t(x, \nu)=\frac{\Gamma(\nu+1)/2}{\sqrt{\nu \pi} \cdot \Gamma(\nu/2)} \cdot (1+x^2/\nu)^{-(\nu+1)/2}\]
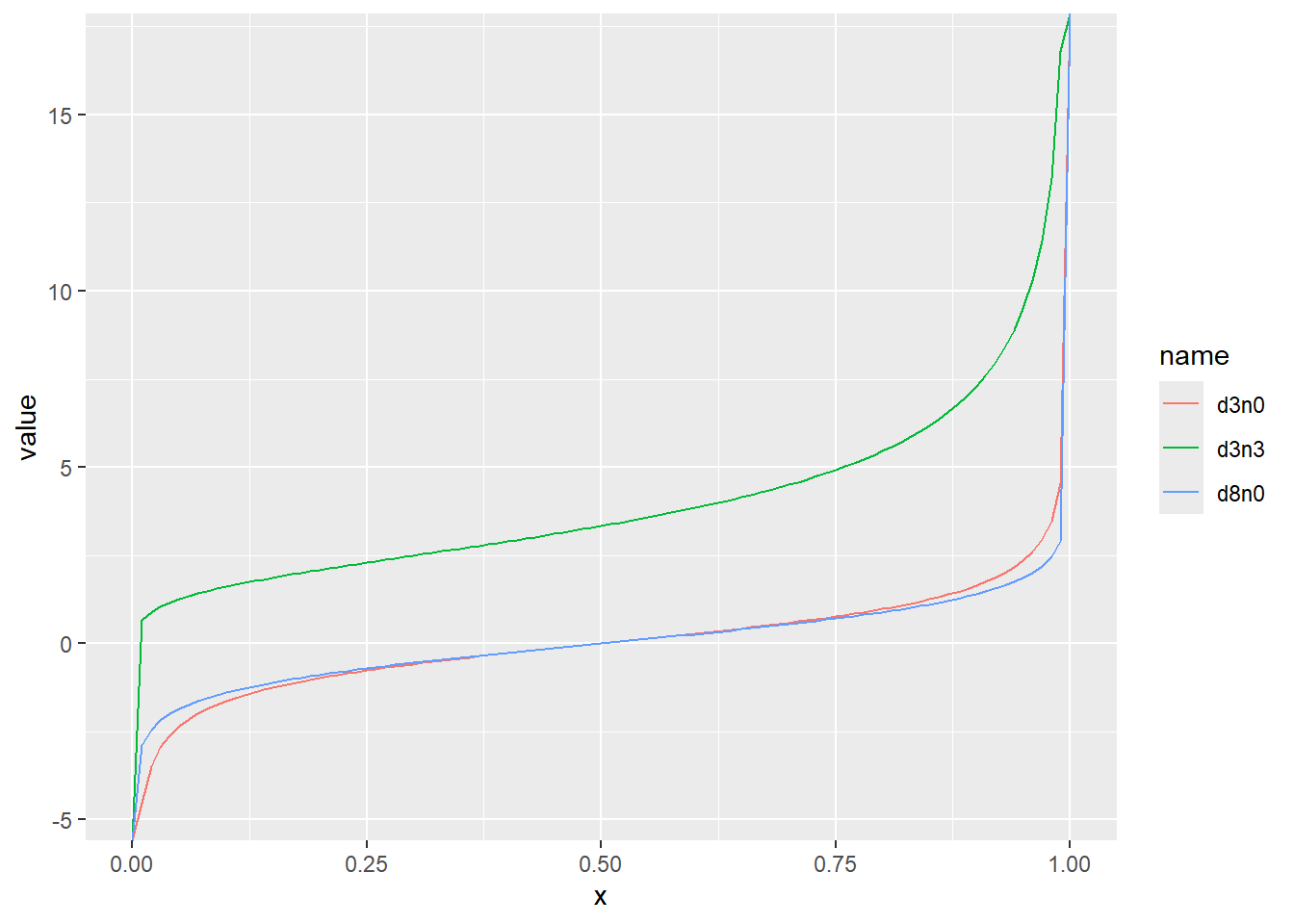
上の式のνは自由度で、サンプル数から1を引いたものとなります。Rでは、dt関数でt分布の確率密度関数を計算することができます。dt関数の引数には、自由度dfを設定します。t分布は\(-\infty\)~\(\infty\)の範囲を持つ連続値を取り、平均値は0です。t分布は正規分布とよく似た釣鐘型の分布ですが、正規分布と比較して裾が重い、0から遠い値の確率が大きくなる性質を持ちます。自由度dfが\(-\infty\)に近づくと、t分布の形は正規分布と一致します。
また、t分布には検出力の計算等に用いられる非心パラメータと呼ばれるものがあり、ncpという引数で非心パラメータを指定することもできます。非心パラメータを0よりも大きく設定すると、t分布は左にゆがみ、平均値が0よりも大きくなります。
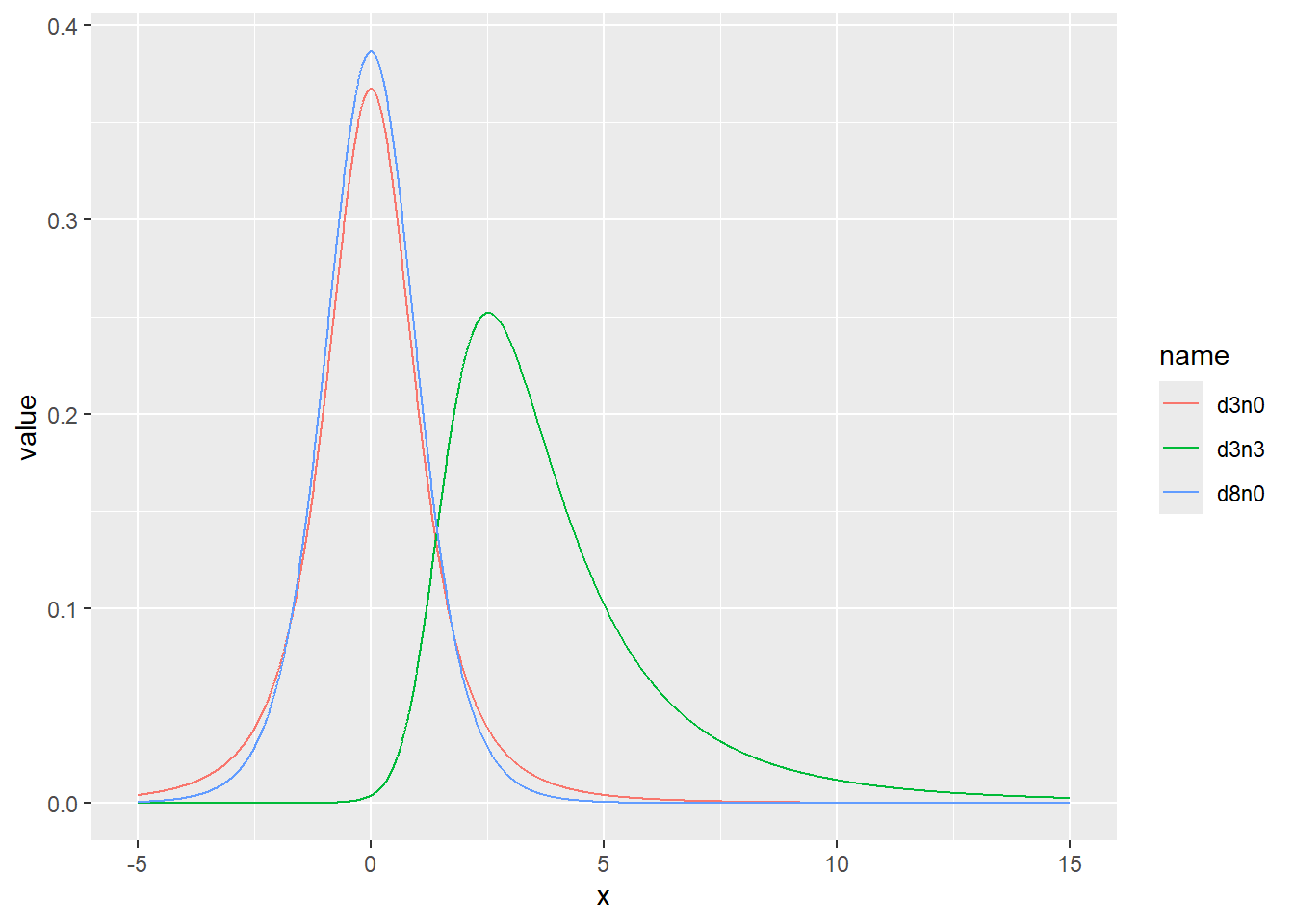
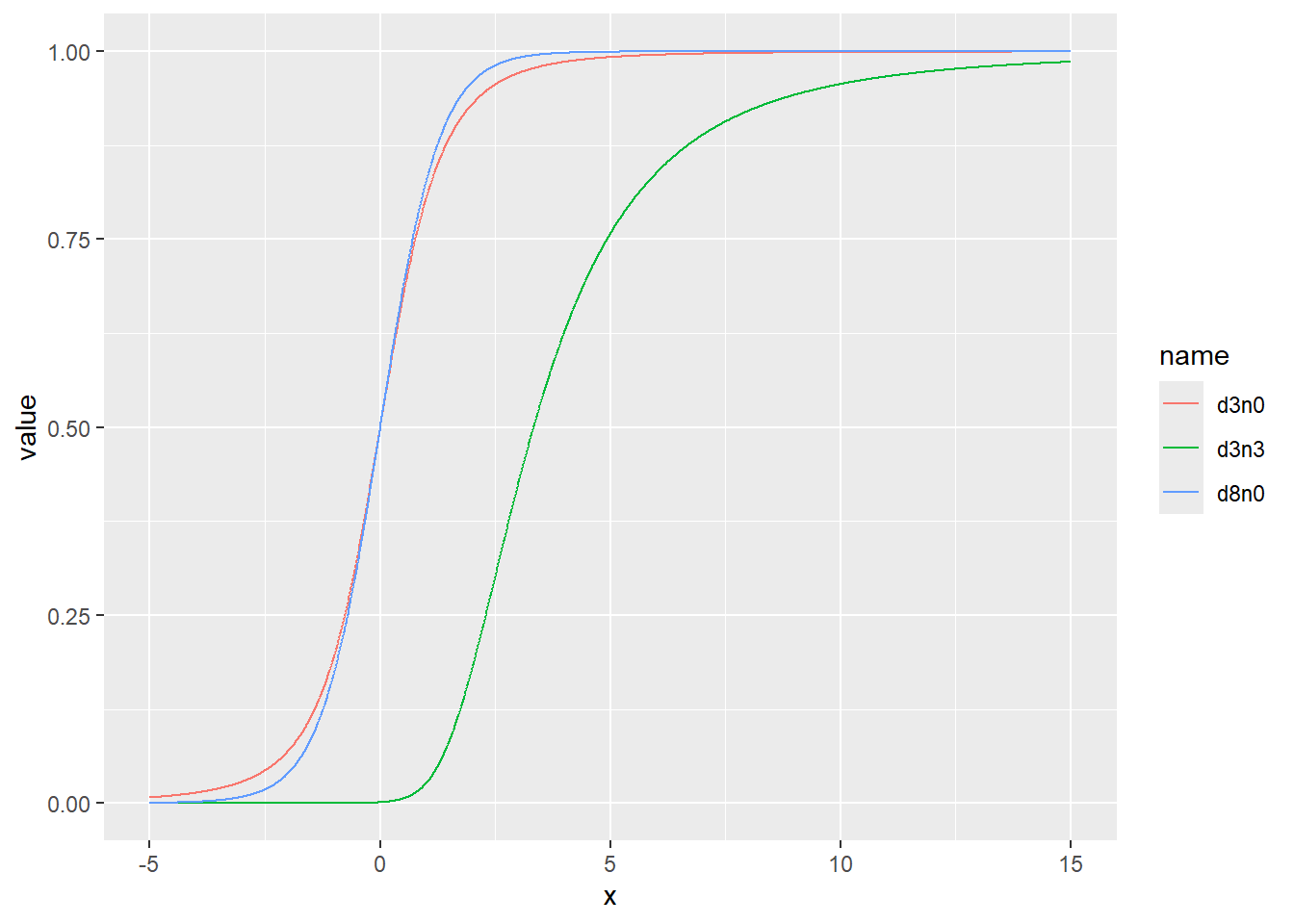
乱数の確率密度をプロット
d <- tibble(
d3n0 = rt(1000, df = 3, ncp = 0), # 自由度3、非心パラメータ0
d8n0 = rt(1000, df = 8, ncp = 0), # 自由度8、非心パラメータ0
d3n3 = rt(1000, df = 3, ncp = 3) # 自由度3、非心パラメータ3
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")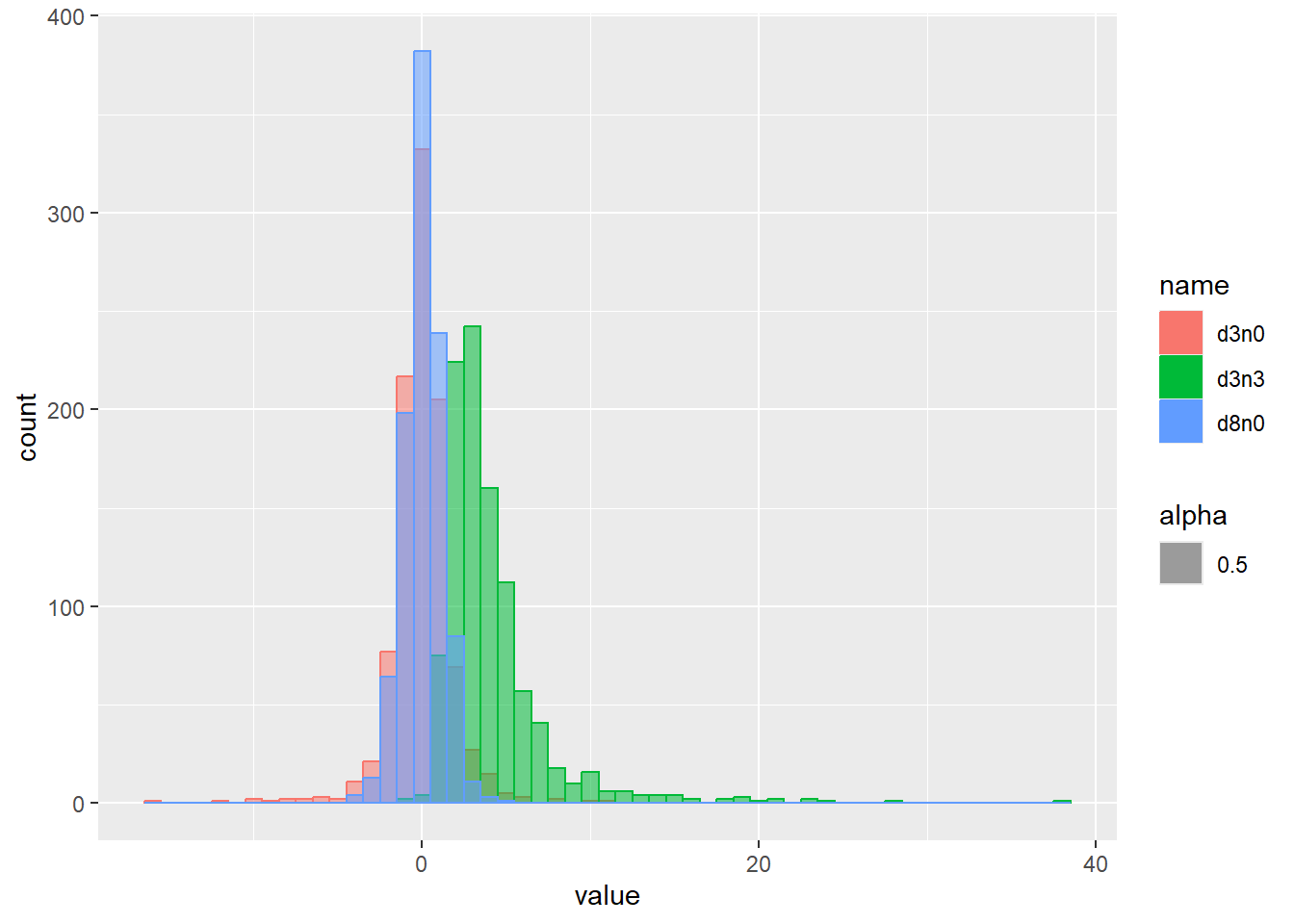
コーシー分布はt分布で自由度が1のときの分布です。コーシー分布はt分布よりもさらに裾が重く、平均値も標準偏差も定義できない分布です。コーシー分布のパラメータは中央値であるtとスケールパラメータであるsの2つです。コーシー分布の確率密度関数は以下の式で表されます。
\[Cauchy(x, t, s)=\frac{1}{s \cdot \pi (1+((x-t)/s)^2)} \]
Rでは、コーシー分布の確率密度関数はdcauchy関数で計算することができます。dcauchy関数の引数は中央値tであるlocationとスケールパラメータsであるscaleの2つです。コーシー分布も正規分布やt分布と同じく、\(-\infty\)~\(\infty\)の範囲を持つ連続値を取ります。
コーシー分布の確率密度をプロット
x <- seq(-5, 5, by = 0.01)
d <- tibble(
x,
l0s1 = dcauchy(x, location = 0, scale = 1), # 中央値0、スケール1
lm2s05 = dcauchy(x, location = -2, scale = 0.5), # 中央値-2、スケール0.5
l2s2 = dcauchy(x, location = 2, scale = 2) # 中央値2、スケール2
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()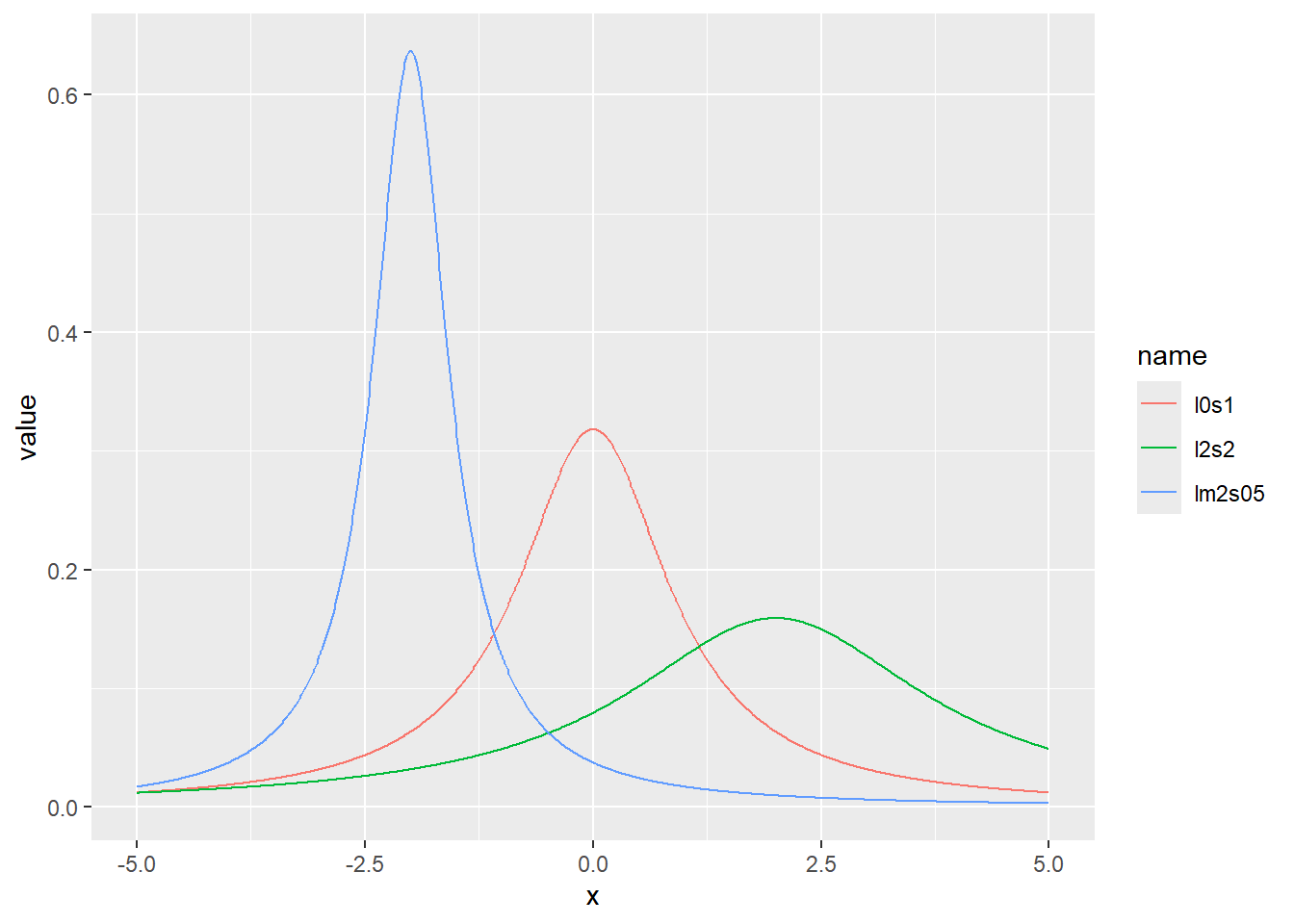
コーシー分布の累積分布関数をプロット
d <- tibble(
x,
l0s1 = pcauchy(x, location = 0, scale = 1), # 中央値20、スケール0.1
lm2s05 = pcauchy(x, location = -2, scale = 0.5), # 中央値20、スケール0.5
l2s2 = pcauchy(x, location = 2, scale = 2) # 中央値20、スケール0.8
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()+
expand_limits(y=0)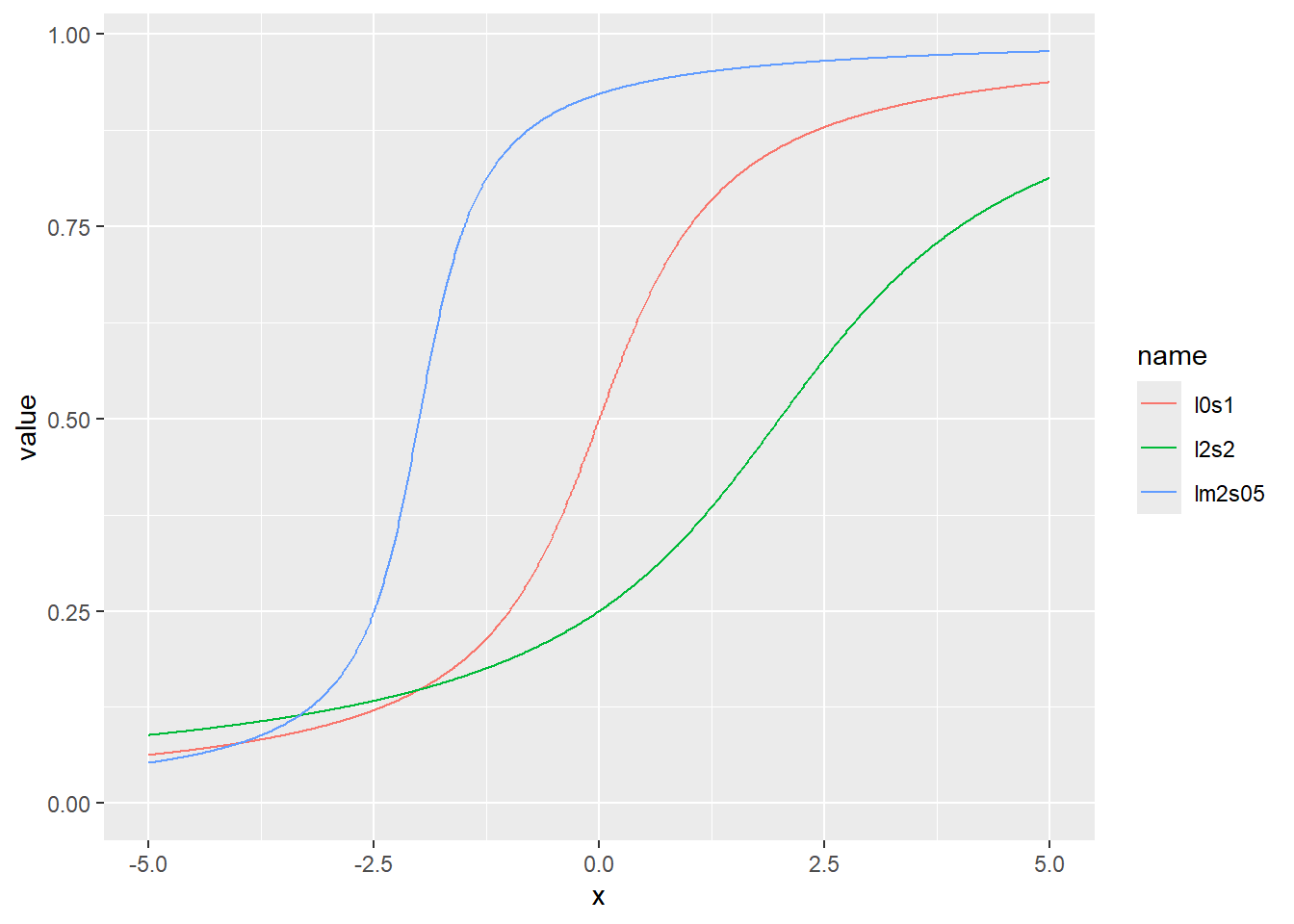
累積分布関数の分位点と値の関係をqcauchyでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
l0s1 = qcauchy(x, location = 0, scale = 1), # 中央値20、スケール0.1
lm2s05 = qcauchy(x, location = -2, scale = 0.5), # 中央値20、スケール0.5
l2s2 = qcauchy(x, location = 2, scale = 2) # 中央値20、スケール0.8
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()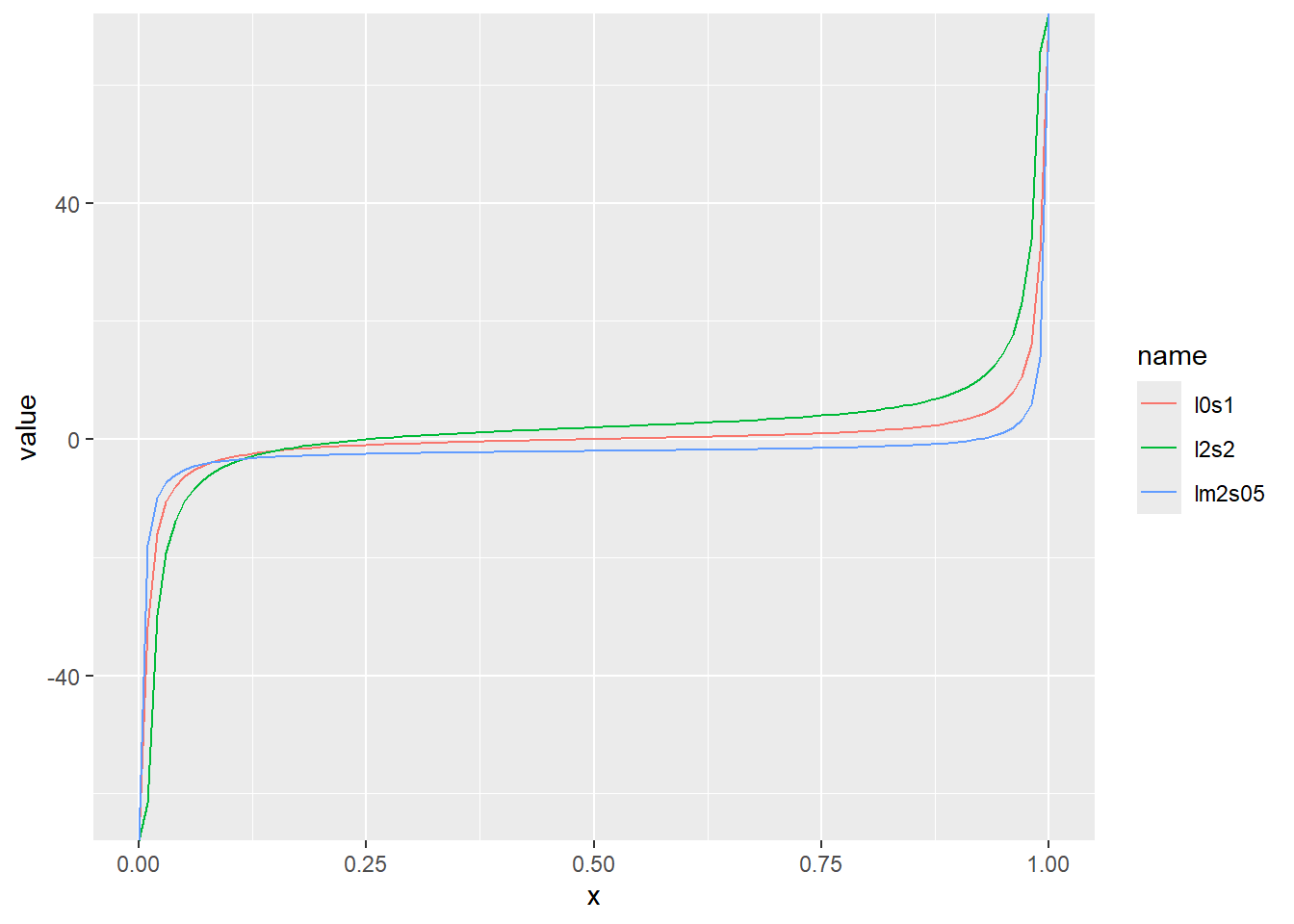
乱数のヒストグラムをプロット
set.seed(0)
d <- tibble(
l0s1 = rcauchy(1000, location = 0, scale = 1), # 中央値20、スケール0.1
lm2s05 = rcauchy(1000, location = -2, scale = 0.5), # 中央値20、スケール0.5
l2s2 = rcauchy(1000, location = 2, scale = 2) # 中央値20、スケール0.8
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.2)) +
geom_histogram(binwidth = 50, position = "identity")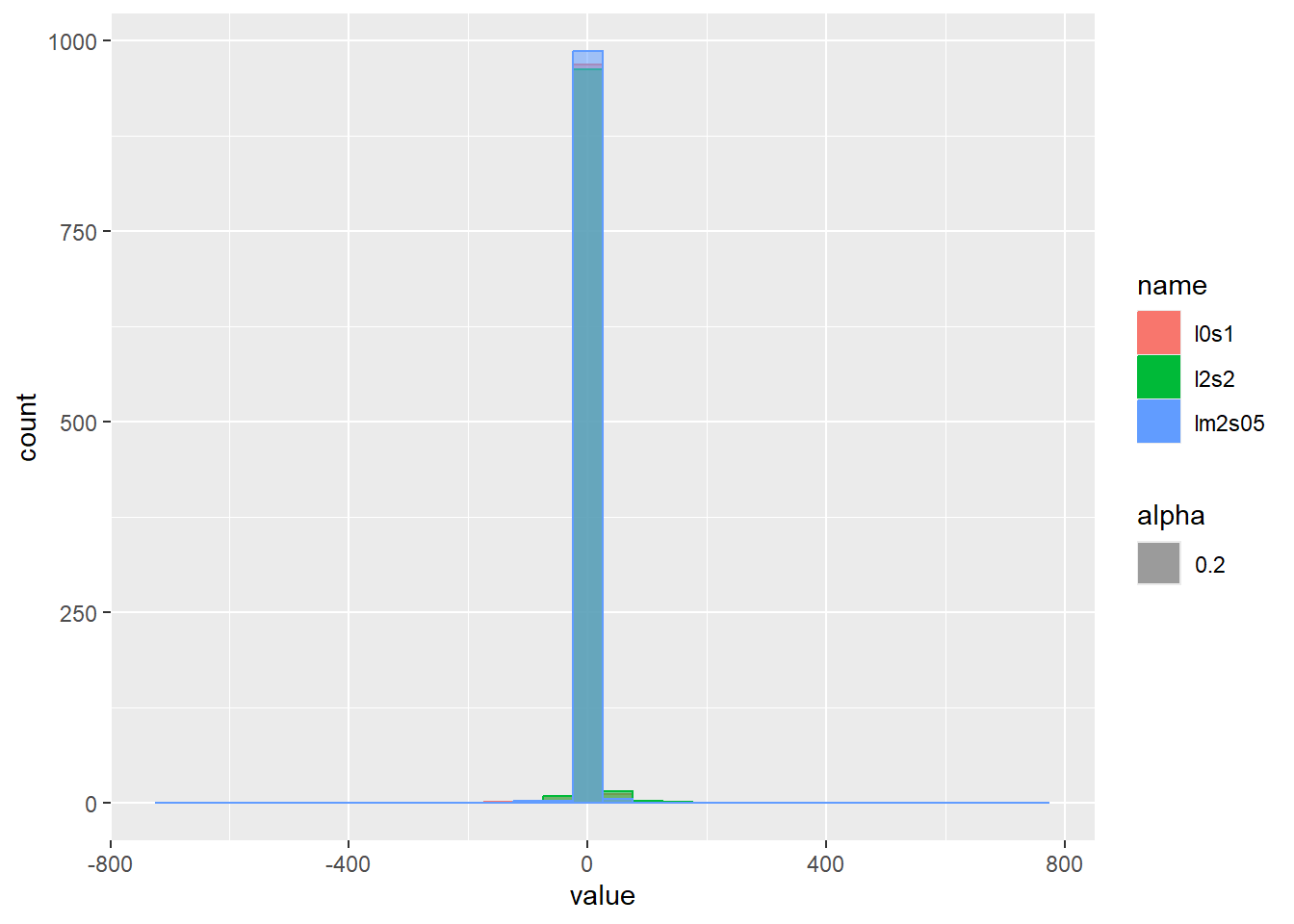
ロジスティック分布はロジスティック関数を微分したものを分布としたもの、つまり、ロジスティック分布の積分である累積分布関数がロジスティック関数を取る分布のことを指します。ロジスティック関数は線形回帰で用いられる関数で、以下の式で表されます。
\[logis(x)=\frac{1}{(1+\exp(-(ax+b))}\]
ロジスティック関数は個体群モデルの数式化と関連のある関数です。統計では、逆関数であるロジット関数から導出されます。ロジット関数は以下の式で表されます。
\[log(\frac{p}{1-p})=ax+b\]
ロジット関数のpはベルヌーイ試行の成功確率p、ax+bは線形回帰の式です。\(p/1-p\)はオッズ比と呼ばれるもので、成功確率と失敗確率の比を指します。
ロジスティック分布は以下の式で表されます。
\[Logistic(x, \mu, s)=\frac{\exp(-x)}{s(1+\exp(-(x-\mu)/s)^2)}\]
上の式のμは中央値、sはスケールパラメータです。Rでは、ロジスティック分布の確率密度関数はdlogis関数で計算することができます。dlogis関数の引数には、中央値μであるlocationとスケールパラメータsであるscaleを指定します。ロジスティック分布は\(-\infty\)~\(\infty\)の範囲を持つ連続値を取ります。
ロジスティック分布の確率密度をプロット
x <- seq(-5, 5, by = 0.01)
d <- tibble(
x,
l0s1 = dlogis(x, location = 0, scale = 1), # location 0、scale1
l1s2 = dlogis(x, location = 1, scale = 2), # location 1、scale2
l2s05 = dlogis(x, location = 2, scale = 0.5) # location 2、scale0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()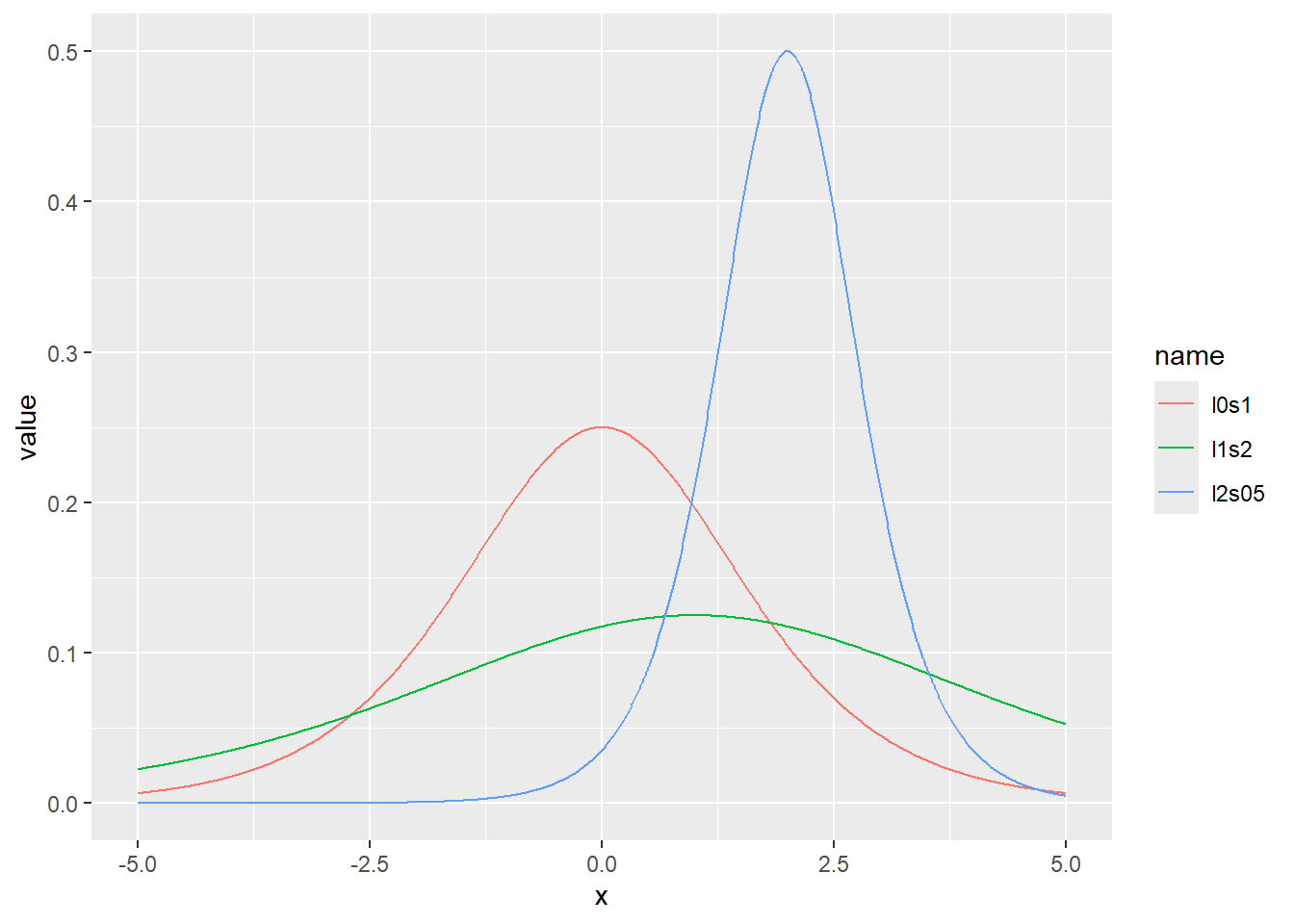
ロジスティック分布の累積分布関数をプロット
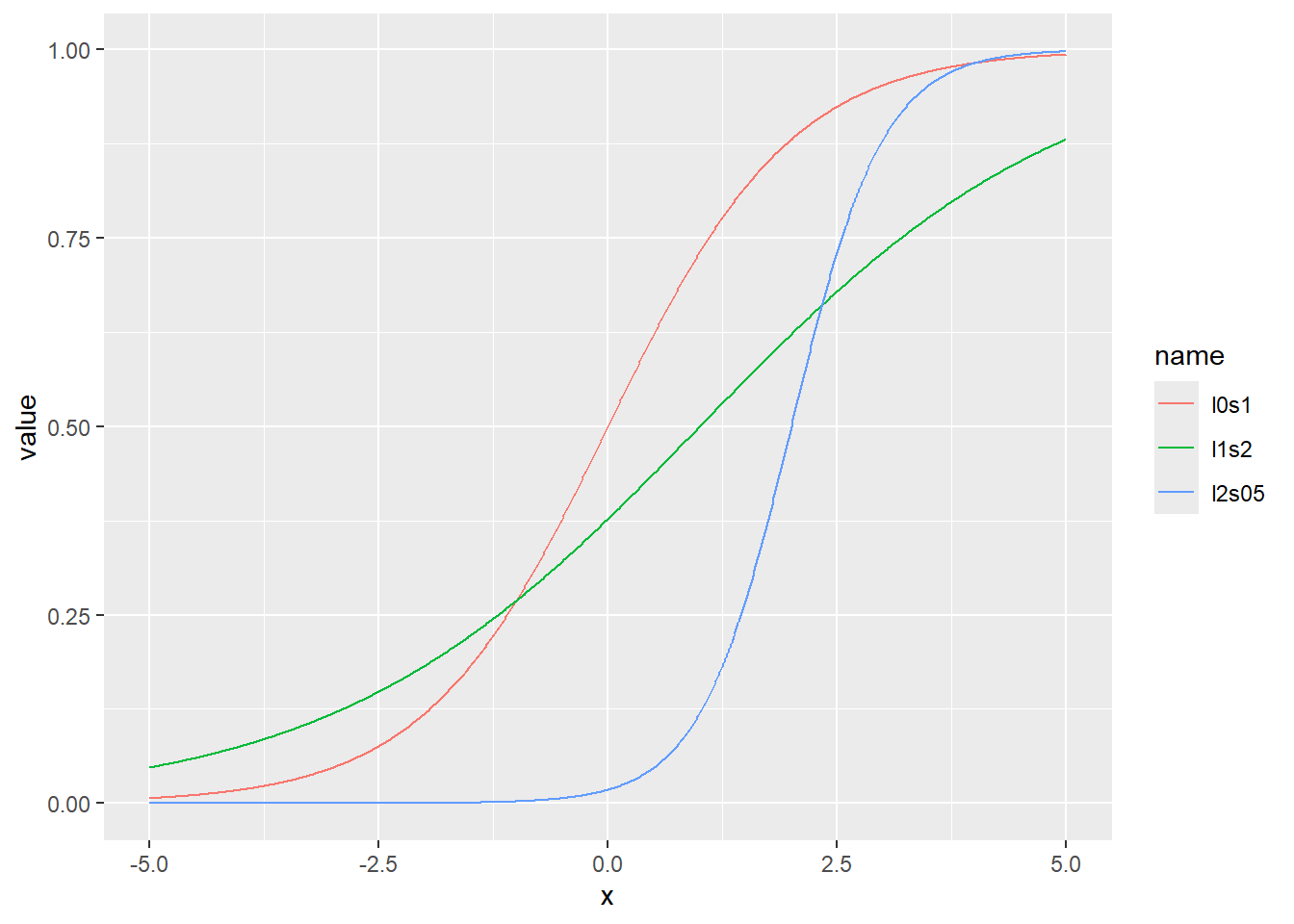
累積分布関数の分位点と値の関係をqlogisでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
l0s1 = qlogis(x, location = 0, scale = 1), # location 0、scale1
l1s2 = qlogis(x, location = 1, scale = 2), # location 1、scale2
l2s05 = qlogis(x, location = 2, scale = 0.5) # location 2、scale0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()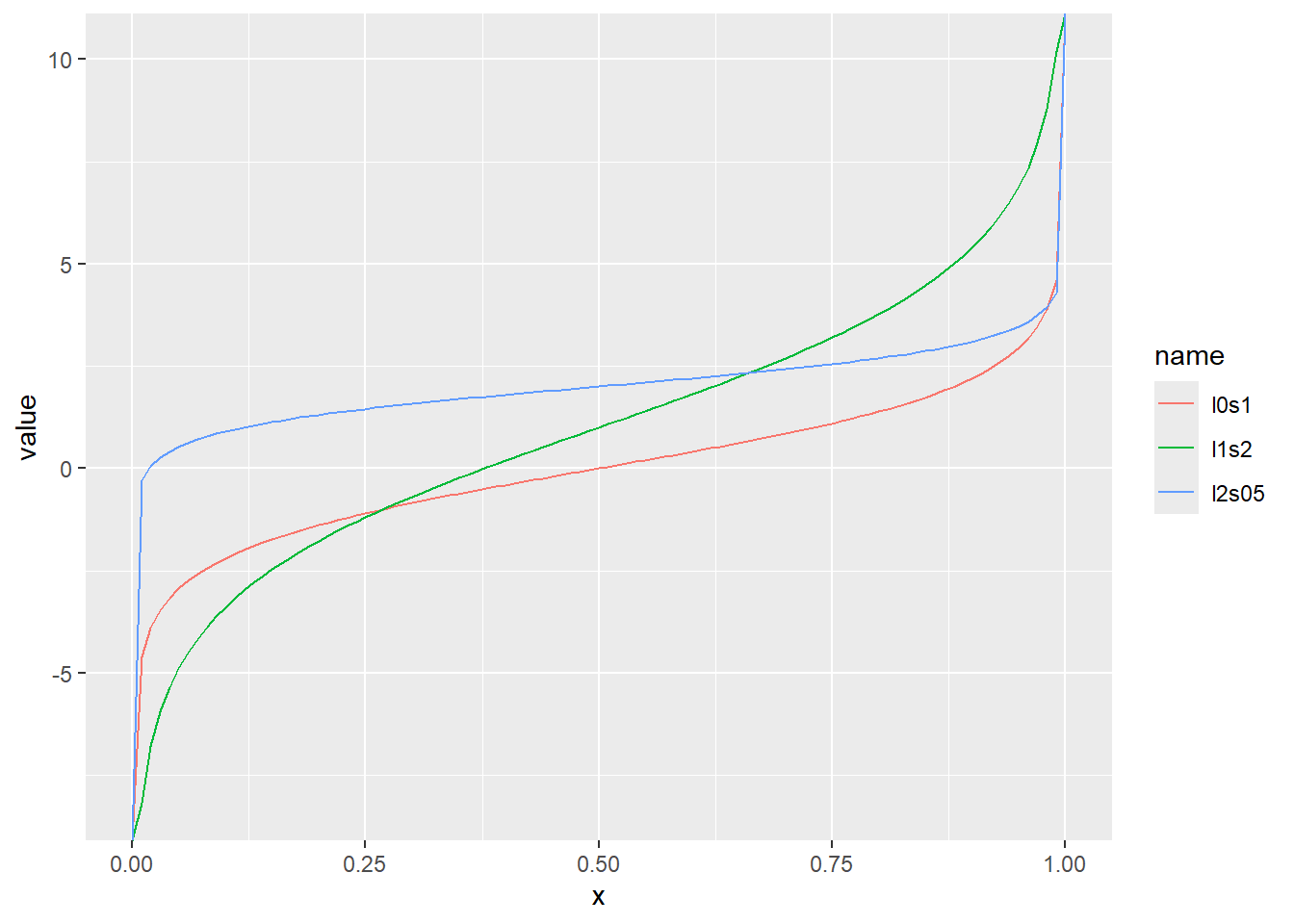
乱数の確率密度をプロット
d <- tibble(
l0s1 = rlogis(1000, location = 0, scale = 1), # location 0、scale1
l1s2 = rlogis(1000, location = 1, scale = 2), # location 1、scale2
l2s05 = rlogis(1000, location = 2, scale = 0.5) # location 2、scale0.5
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")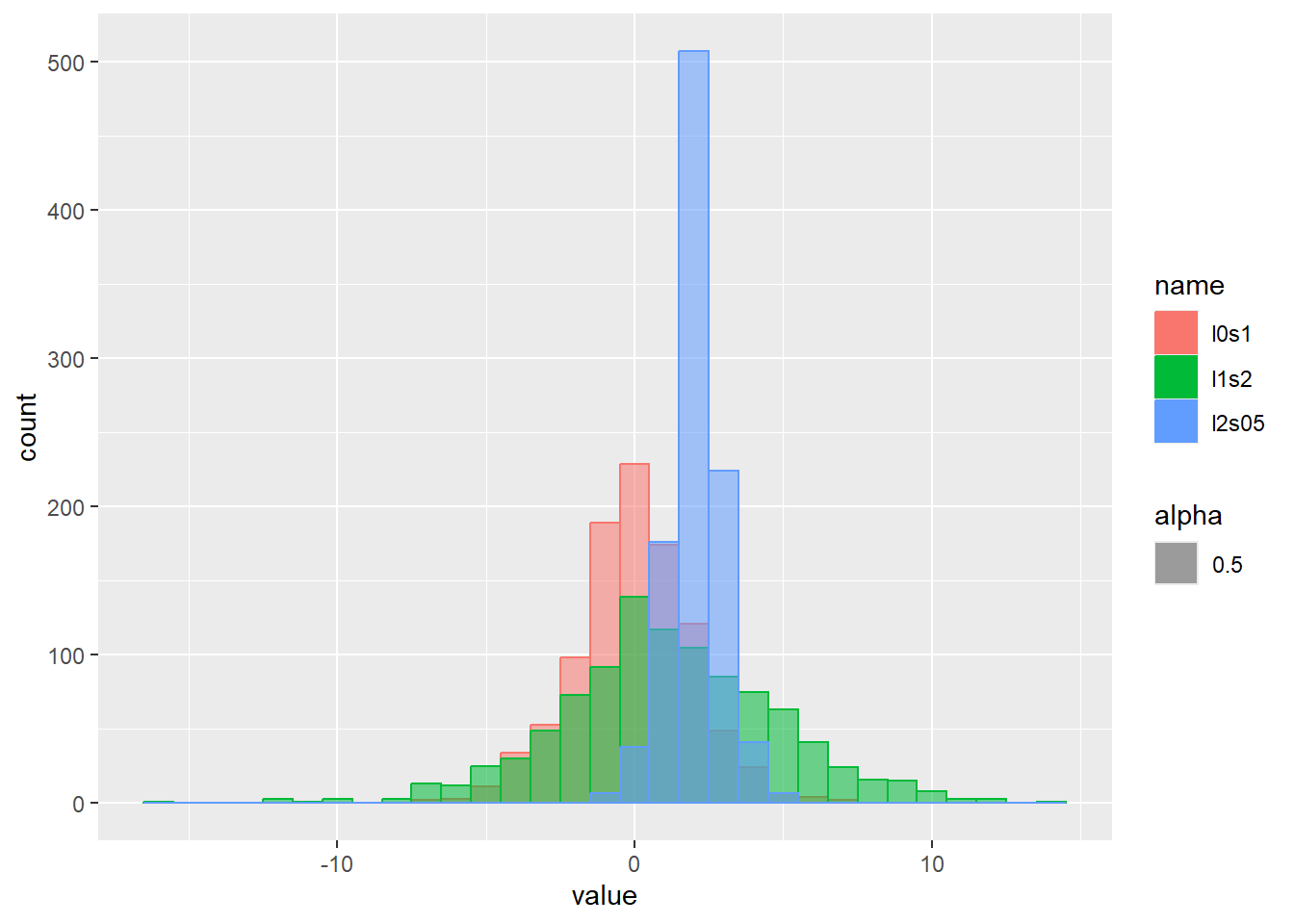
対数正規分布は正規分布を指数変換した分布です。年収がこの分布に従うことで有名です。パラメータは正規分布と同じくμとσですが、μとσは分布の平均値・標準偏差ではありません。対数正規分布の確率密度関数は以下の式で表されます。
\[Lognorm(x, \mu, \sigma)=\frac{1}{x\sigma\sqrt{2\pi}} \cdot \exp(-\frac{(\ln x-\mu)^2}{2\sigma^2})\]
Rで対数正規分布の確率密度関数を計算するには、dlnorm関数を用います。dlnorm関数の引数には、μとしてmeanlog、σとしてsdlogを指定します。対数正規分布は左に歪み、右側の裾が長い分布を示し、0~\(\infty\)の範囲を持つ連続値を取ります。
対数正規分布の確率密度をプロット
x <- seq(0, 5, by = 0.01)
d <- tibble(
x,
m0s1 = dlnorm(x, meanlog = 0, sdlog = 1), # 平均(対数)0、標準偏差(対数)1
m2s2 = dlnorm(x, meanlog = 2, sdlog = 2), # 平均(対数)2、標準偏差(対数)2
mm2s05 = dlnorm(x, meanlog = -2, sdlog = 0.5) # 平均(対数)-2、標準偏差(対数)0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()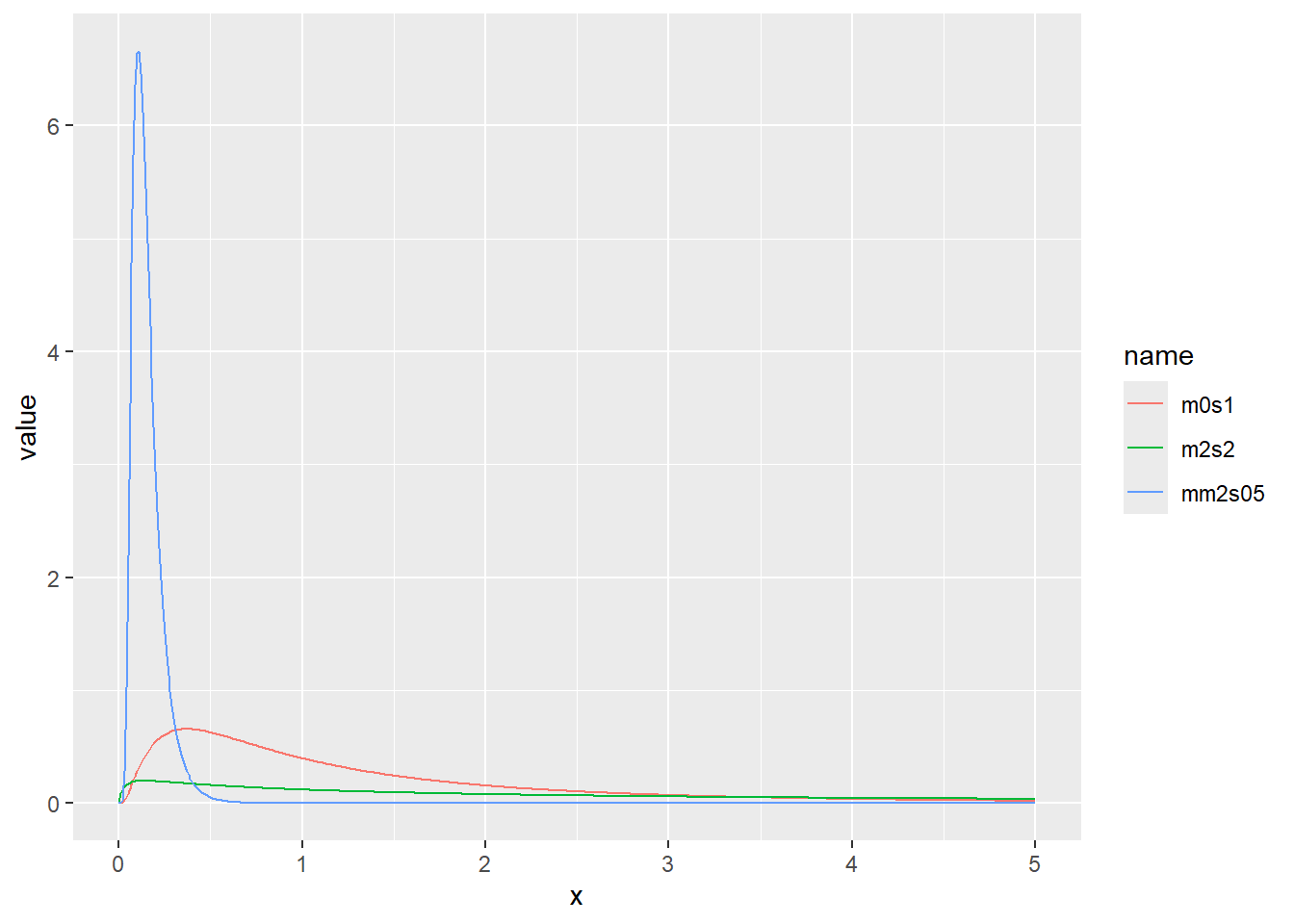
対数正規分布の累積分布関数をプロット
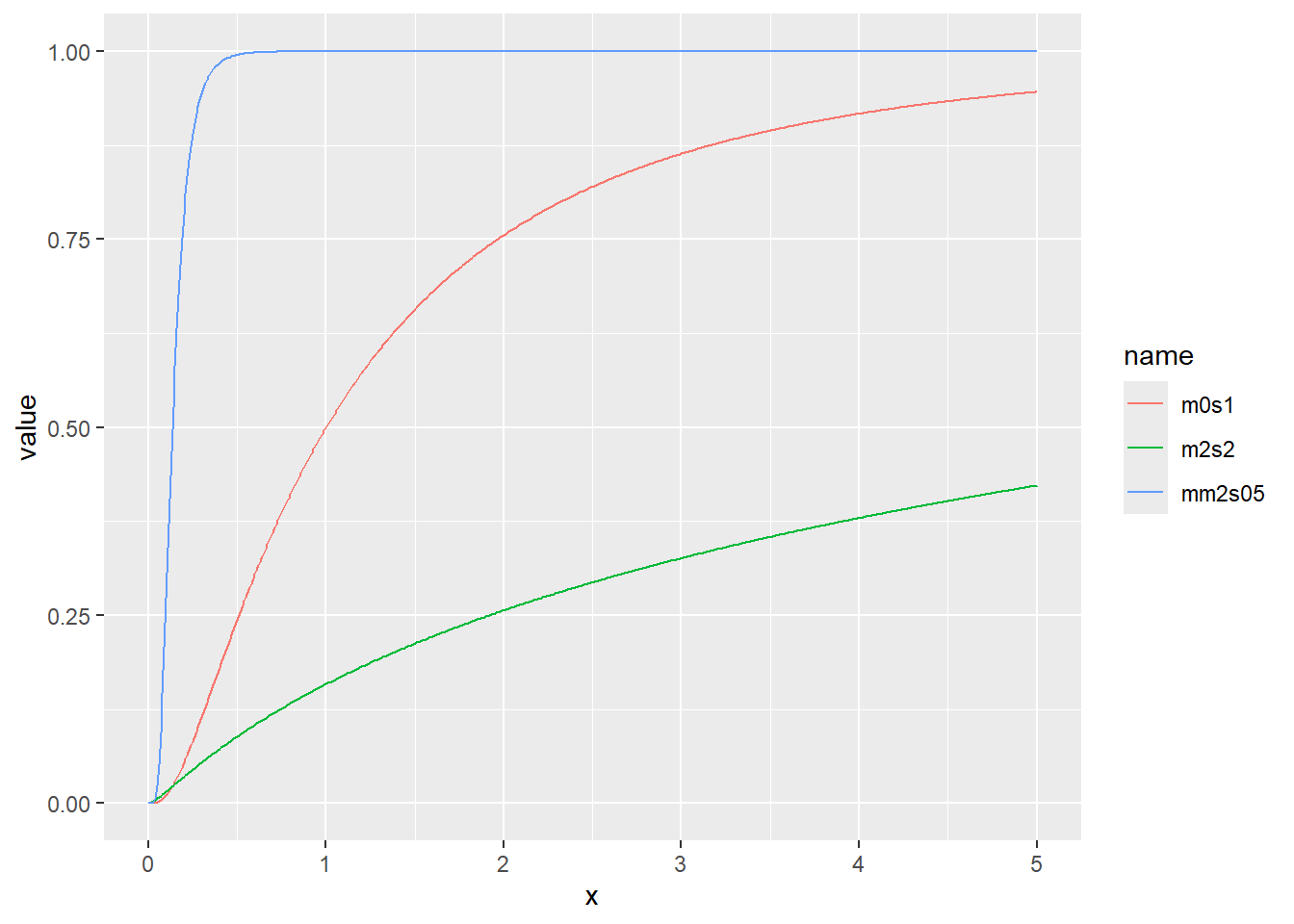
累積分布関数の分位点と値の関係をqfでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
m0s1 = qlnorm(x, meanlog = 0, sdlog = 1), # 平均(対数)0、標準偏差(対数)1
m2s2 = qlnorm(x, meanlog = 2, sdlog = 2), # 平均(対数)2、標準偏差(対数)2
mm2s05 = qlnorm(x, meanlog = -2, sdlog = 0.5) # 平均(対数)-2、標準偏差(対数)0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()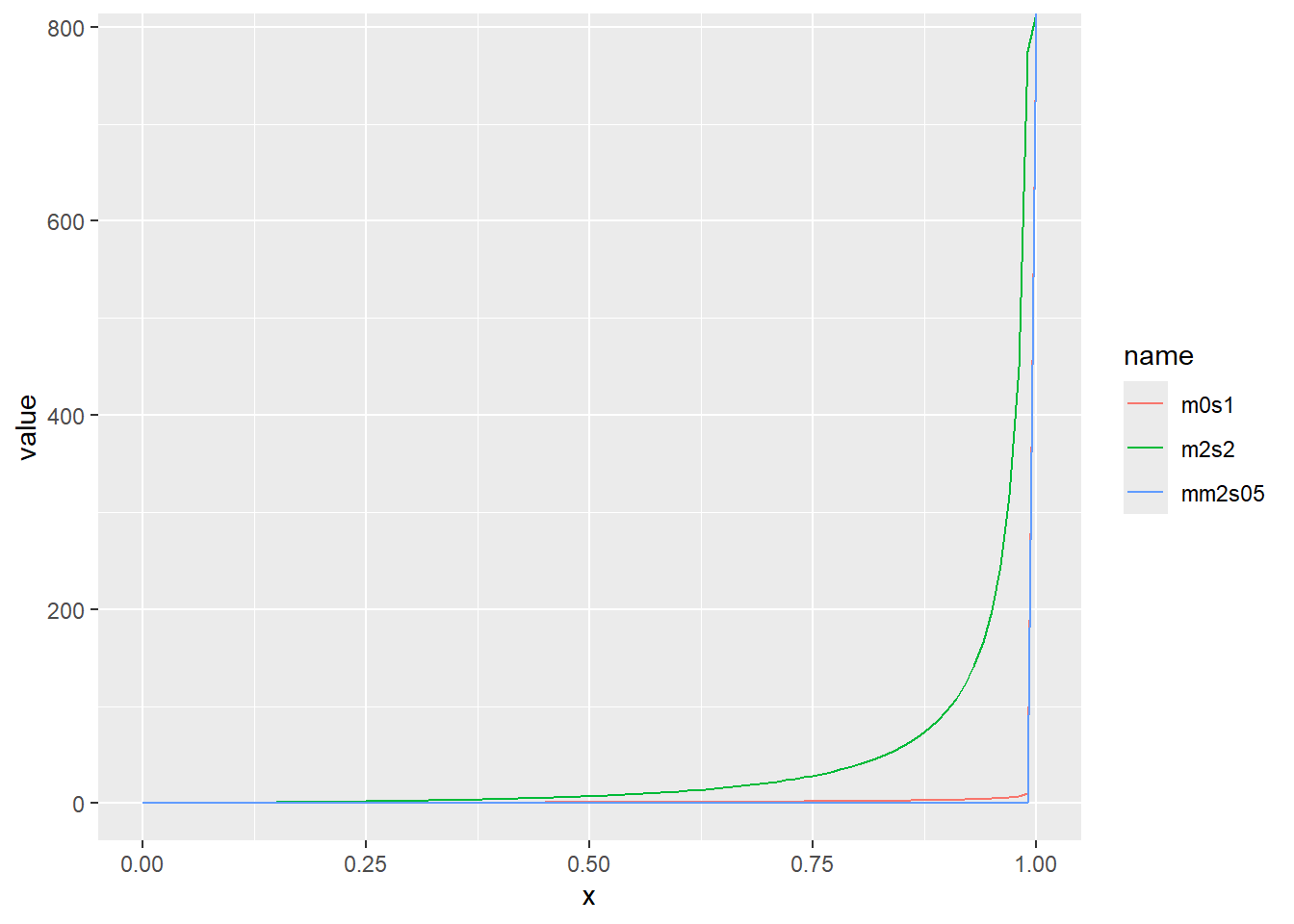
乱数の確率密度をプロット
d <- tibble(
m0s1 = rlnorm(1000, meanlog = 0, sdlog = 1), # 平均(対数)0、標準偏差(対数)1
m2s2 = rlnorm(1000, meanlog = 2, sdlog = 2), # 平均(対数)2、標準偏差(対数)2
mm2s05 = rlnorm(1000, meanlog = -2, sdlog = 0.5) # 平均(対数)-2、標準偏差(対数)0.5
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 100, position = "identity")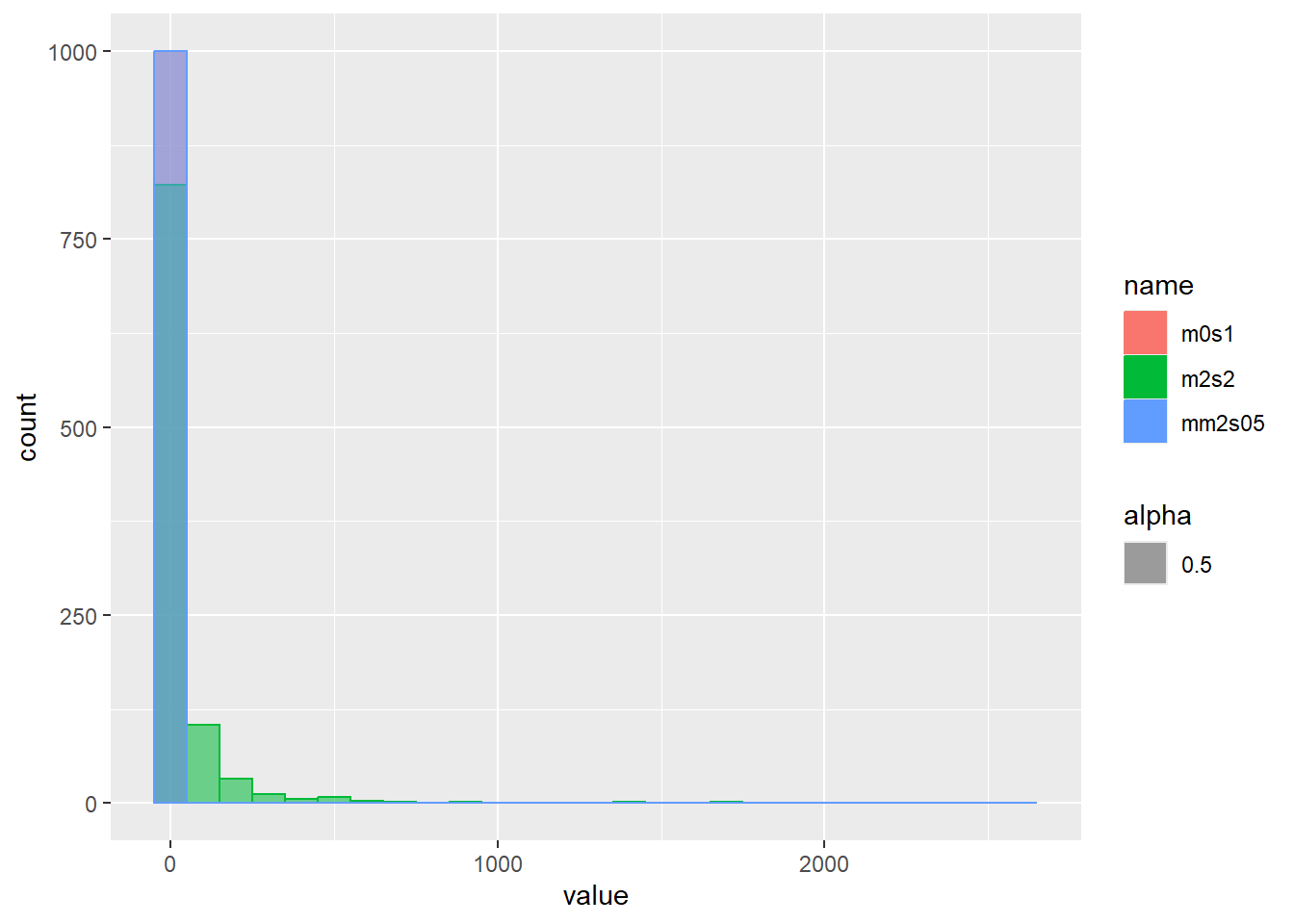
ベータ分布は、ベルヌーイ試行などの成功確率をモデル化する際に用いられる分布です。ベータ分布の確率密度関数には2つのパラメータがあり、それぞれα、βと呼ばれます。どちらも形状パラメータを意味しています。ベータ分布の確率密度関数は以下の式で表されます。
\[Beta(x, \alpha, \beta)=\frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot x^{\alpha-1} \cdot (1-x)^{\beta-1}\]
Rでは、ベータ分布の確率密度関数はdbeta関数で計算することができます。dbeta分布の引数として、αをshape1、βをshape2として指定します。ベータ分布は0~1までの連続値を取ります。
ベータ分布の確率密度をプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
s05s075 = dbeta(x, shape1 = 0.5, shape2 = 0.75), # shape1が0.5、shape2が0.75
s1s1 = dbeta(x, shape1 = 1, shape2 = 1), # shape1が1、shape2が1
s3s2 = dbeta(x, shape1 = 3, shape2 = 2) # shape1が3、shape2が2
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()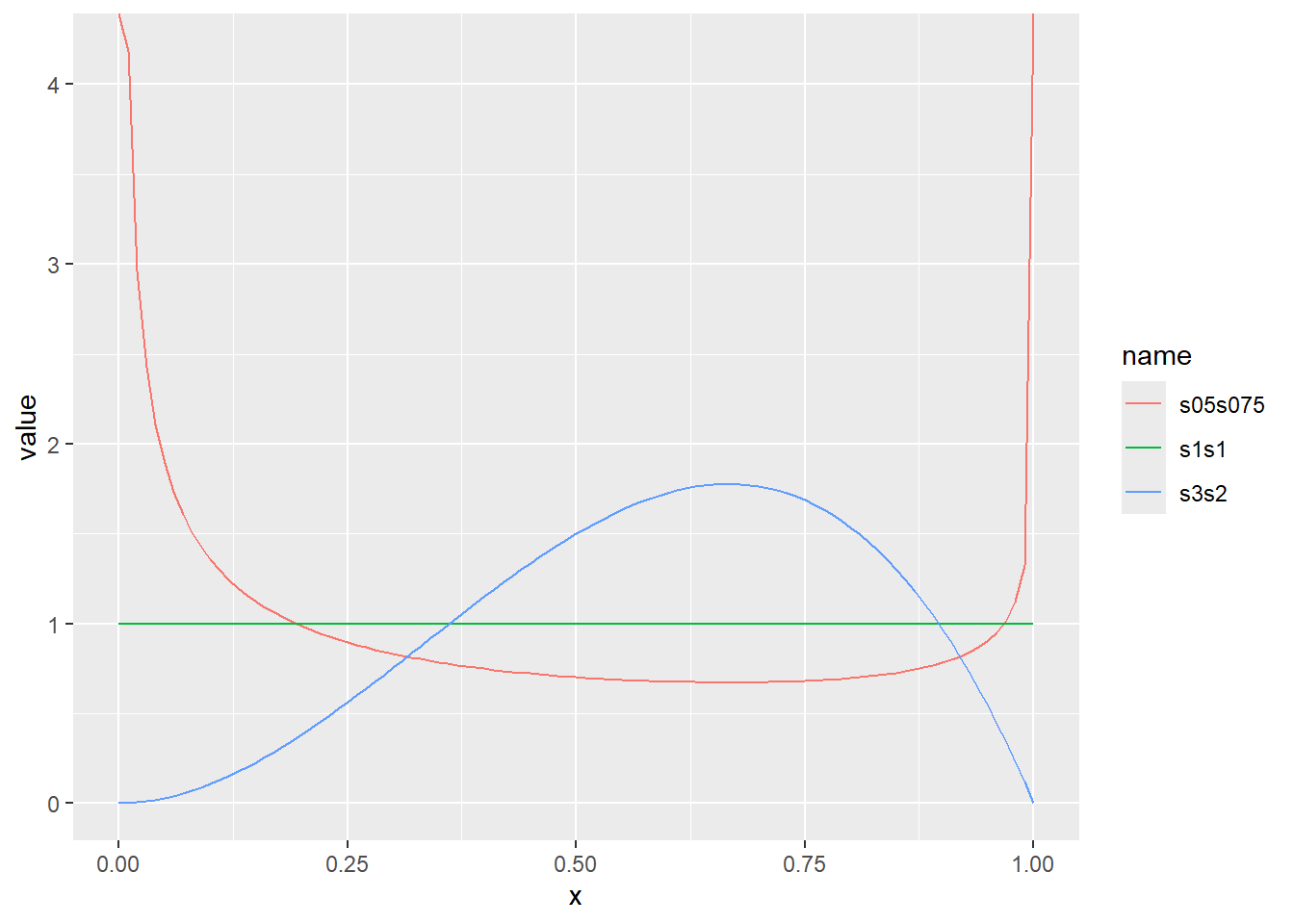
ベータ分布の累積分布関数をプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
s05s075 = pbeta(x, shape1 = 0.5, shape2 = 0.75), # shape1が0.5、shape2が0.75
s1s1 = pbeta(x, shape1 = 1, shape2 = 1), # shape1が1、shape2が1
s3s2 = pbeta(x, shape1 = 3, shape2 = 2) # shape1が3、shape2が2
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()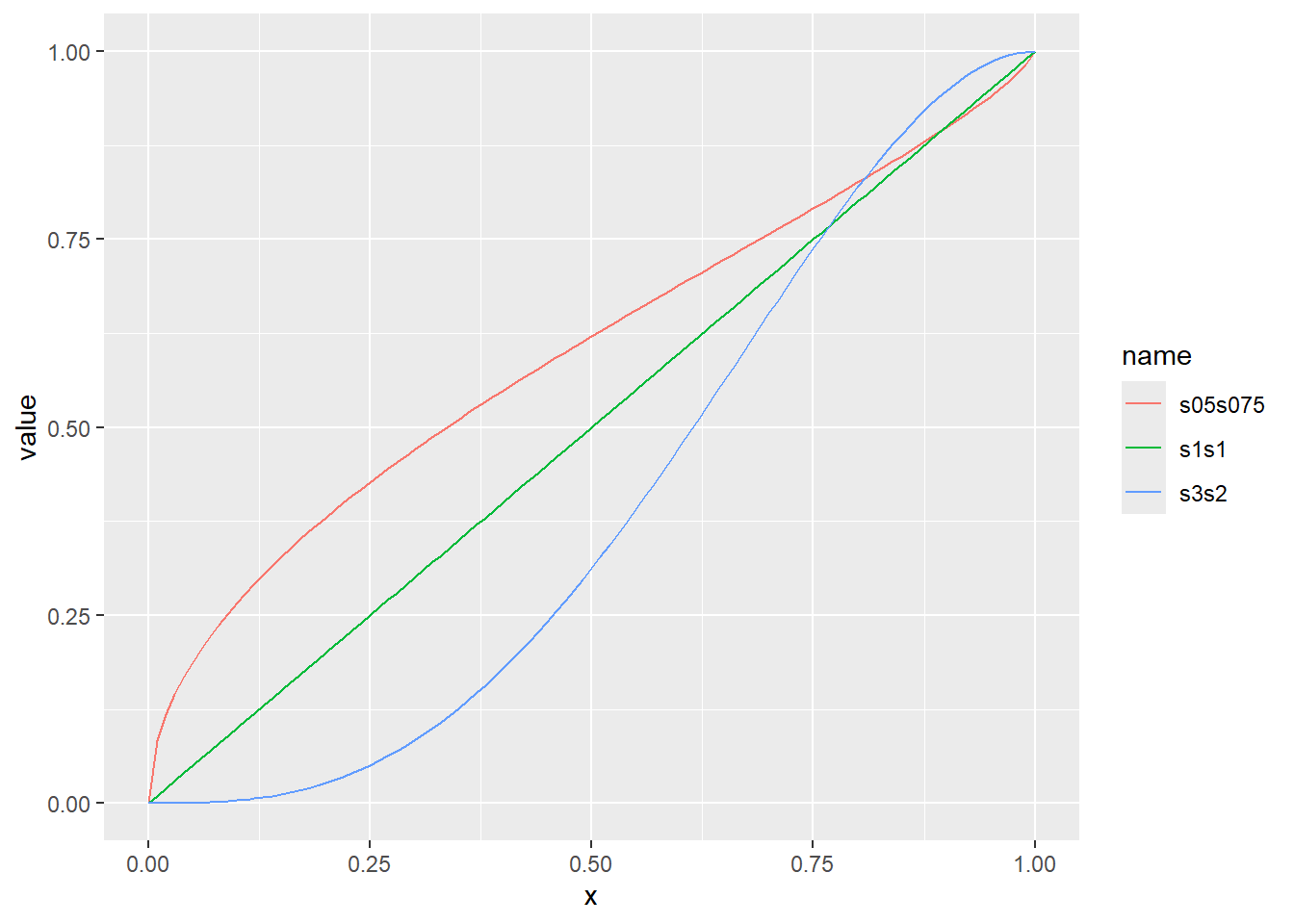
累積分布関数の分位点と値の関係をqbetaでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
s05s075 = qbeta(x, shape1 = 0.5, shape2 = 0.75), # shape1が0.5、shape2が0.75
s1s1 = qbeta(x, shape1 = 1, shape2 = 1), # shape1が1、shape2が1
s3s2 = qbeta(x, shape1 = 3, shape2 = 2) # shape1が3、shape2が2
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()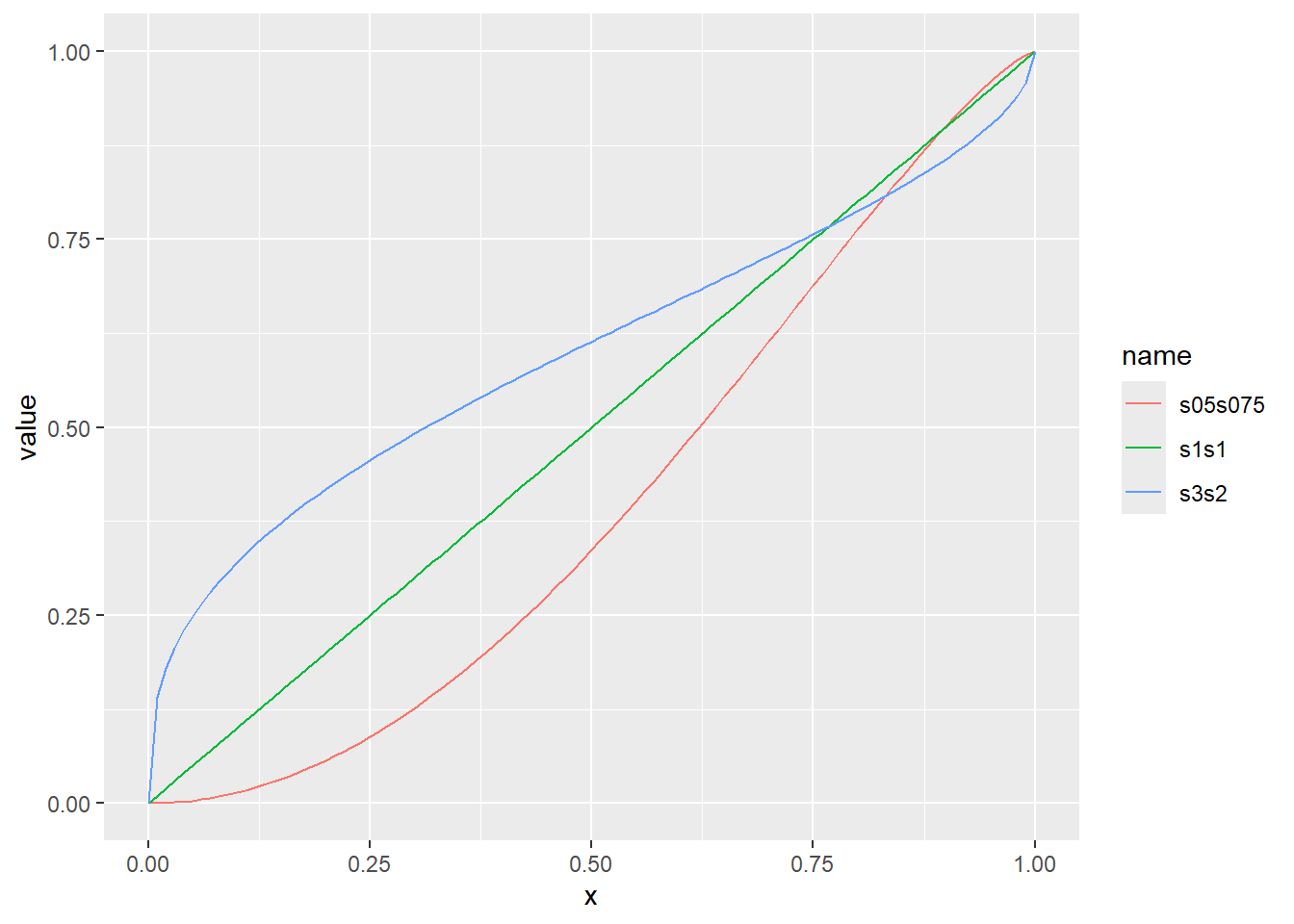
乱数のヒストグラムをプロット
d <- tibble(
s05s075 = rbeta(1000, shape1 = 0.5, shape2 = 0.75), # shape1が0.5、shape2が0.75
s1s1 = rbeta(1000, shape1 = 1, shape2 = 1), # shape1が1、shape2が1
s3s2 = rbeta(1000, shape1 = 3, shape2 = 2) # shape1が3、shape2が2
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 0.1, position = "identity")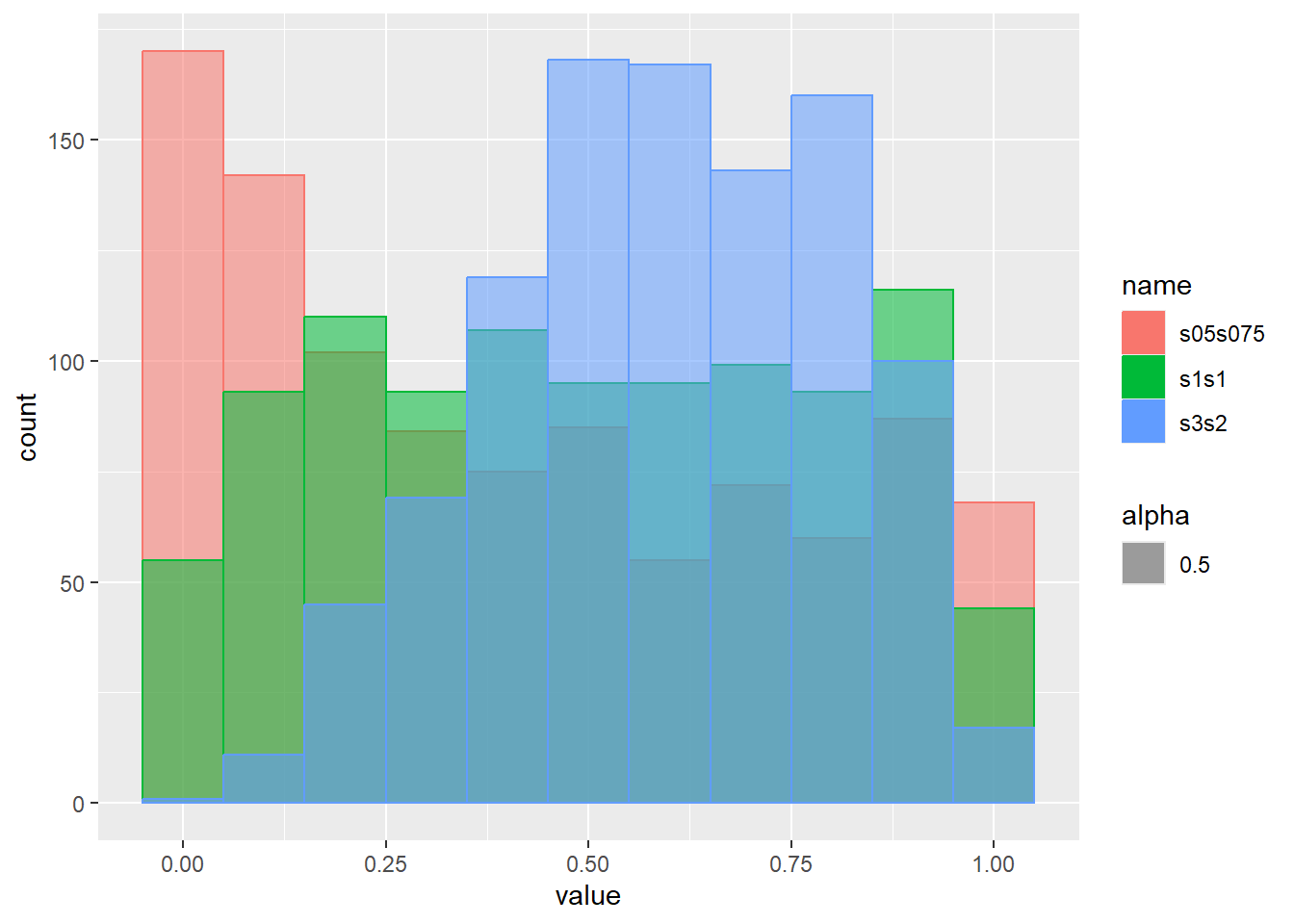
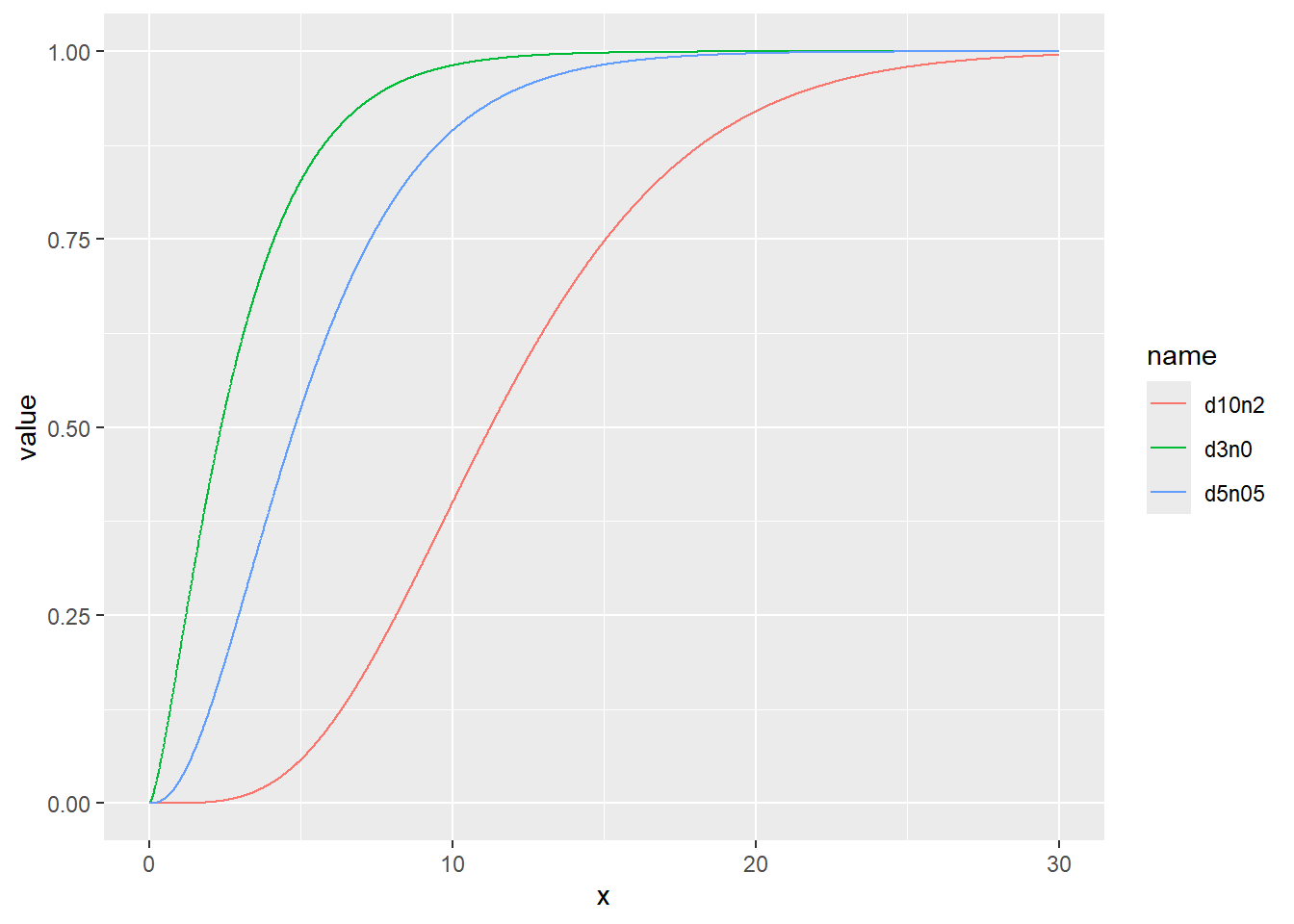
カイ二乗分布は正規分布に従う確率変数の二乗和の確率分布です。カイ二乗分布は度数の検定に用いられる分布で、そのパラメータは自由度νのみです。カイ二乗分布の確率密度関数は以下の式で表されます。
\[Chisq(x, \nu)=\frac{\exp(-x/2) \cdot \exp(\nu/2-1)}{2^{\nu/2} \cdot \Gamma(\nu/2)}\]
Rでは、カイ二乗分布はdchisq関数で計算することができます。dchisq関数の引数として、自由度νをdfとして指定します。カイ二乗分布は右側の裾が長い分布を示し、0~\(\infty\)の範囲を持つ連続値を取ります。
また、t分布と同様に非心度を引数ncpとして指定することもできます。
カイ二乗分布の確率密度をプロット
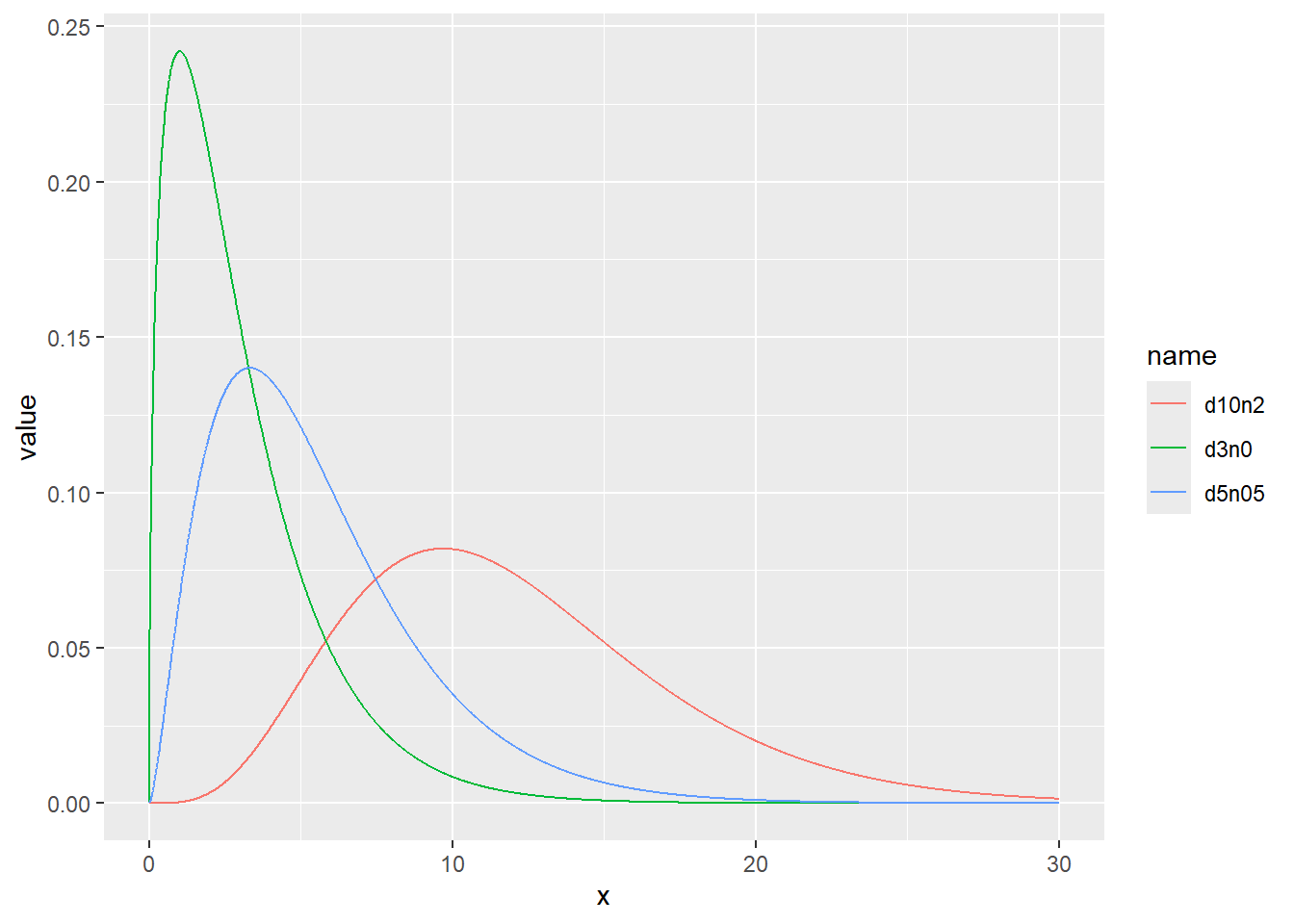
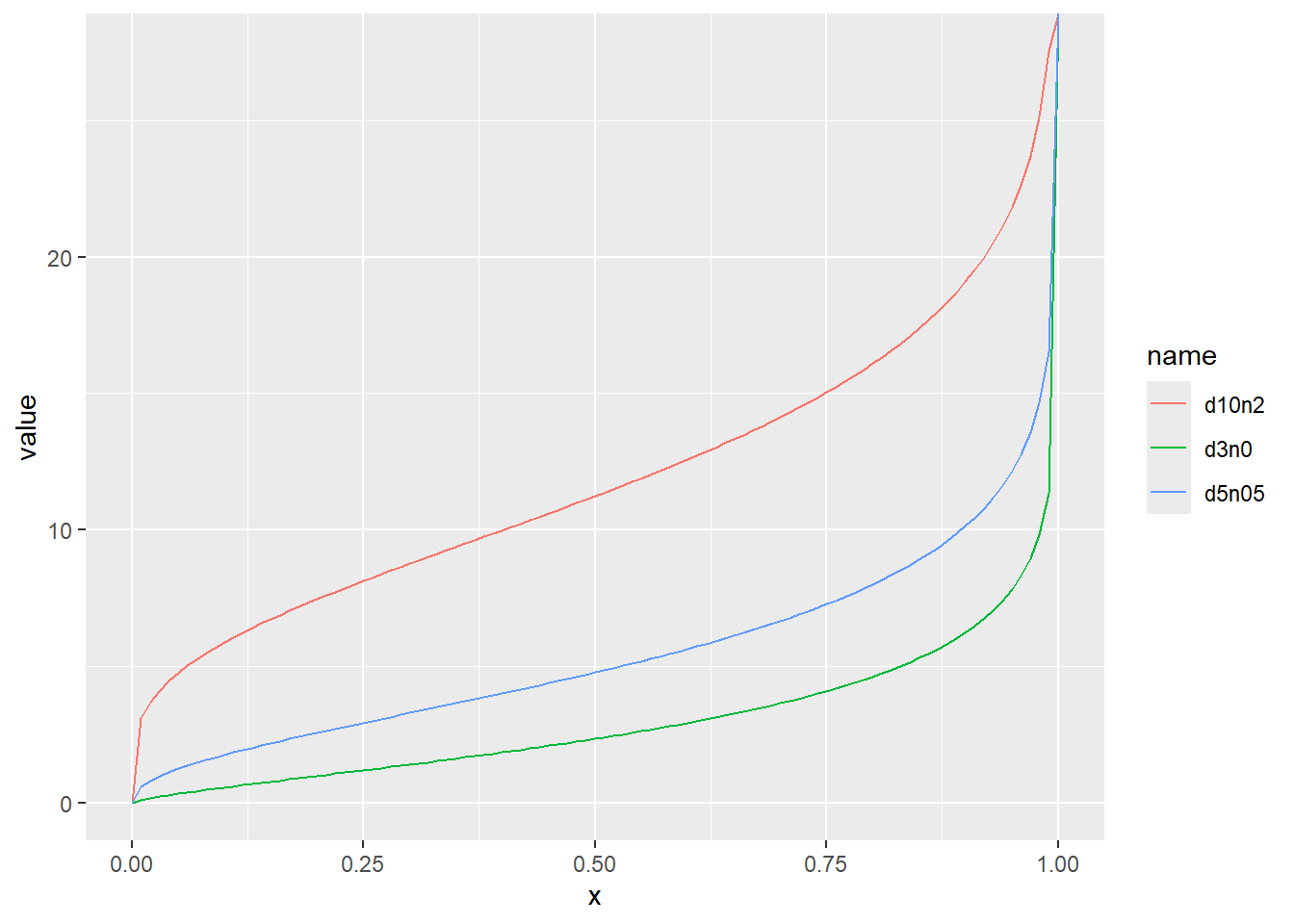
累積分布関数の分位点と値の関係をqchisqでプロット
乱数のヒストグラムをプロット
d <- tibble(
d3n0 = rchisq(1000, df = 3, ncp = 0), # 自由度3、非心パラメータ0
d5n05 = rchisq(1000, df = 5, ncp = 0.5), # 自由度5、非心パラメータ0.5
d10n2 = rchisq(1000, df = 10, ncp = 2) # 自由度10、非心パラメータ2
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")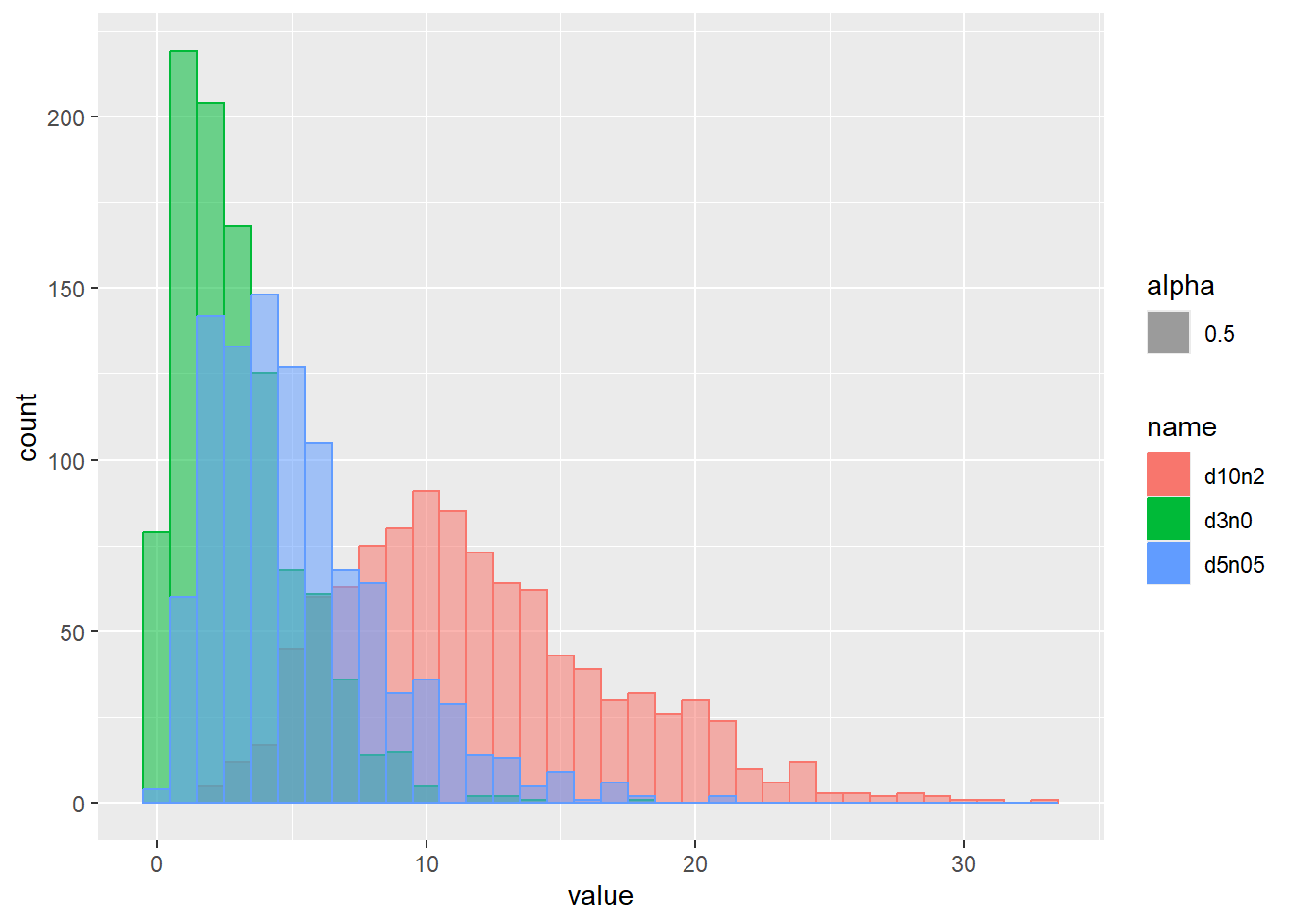
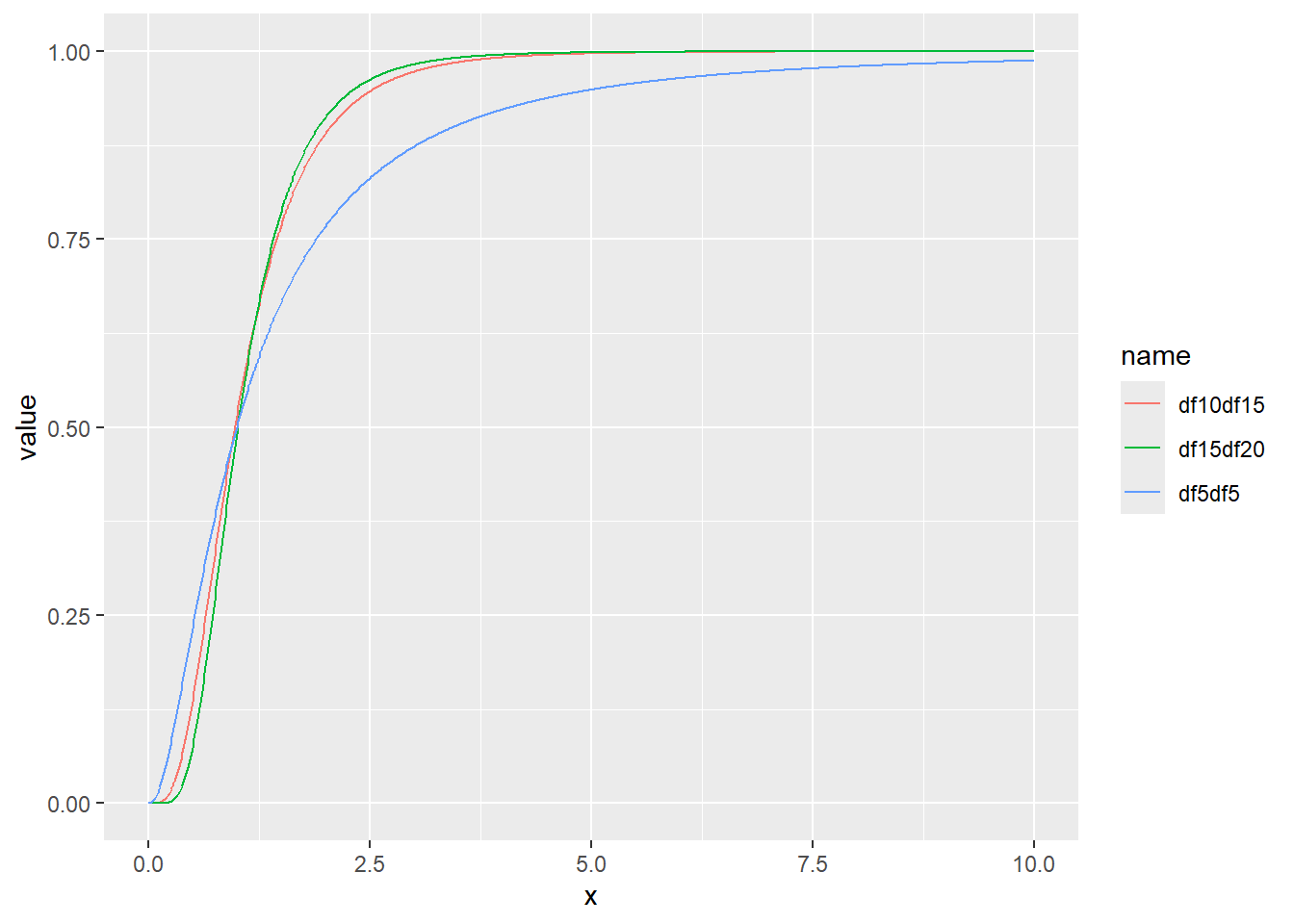
F分布はカイ二乗に従う2つの独立な変数の比の分布です。F分布は分散分析で用いられる分布です。F分布のパラメータは独立の2変数それぞれの自由度(ν1とν2)です。F分布の確率密度関数は以下の式で表されます。
\[F(x, \nu_{1}, \nu_{2})= \frac{\Gamma(\frac{\nu_{1}+\nu_{2}}{2}) \cdot (\frac{\nu_{1}}{\nu_{2}})^{\nu_{1}/2 \cdot x^{\nu_{1}/2-1}}} {\Gamma(\frac{\nu_{1}}{2}) \cdot \Gamma(\frac{\nu_{2}}{2}) \cdot (1+\frac{\nu_{1}x}{\nu_{2}})^{\frac{\nu_{1}+\nu_{2}}{2}}}\]
RではF分布の確率密度関数をdf関数で計算することができます。df関数では自由度2つをそれぞれdf1、df2引数として指定します。F分布も右側の裾が長い分布を示し、0~\(\infty\)の範囲を持つ連続値を取ります。
F分布の確率密度をプロット
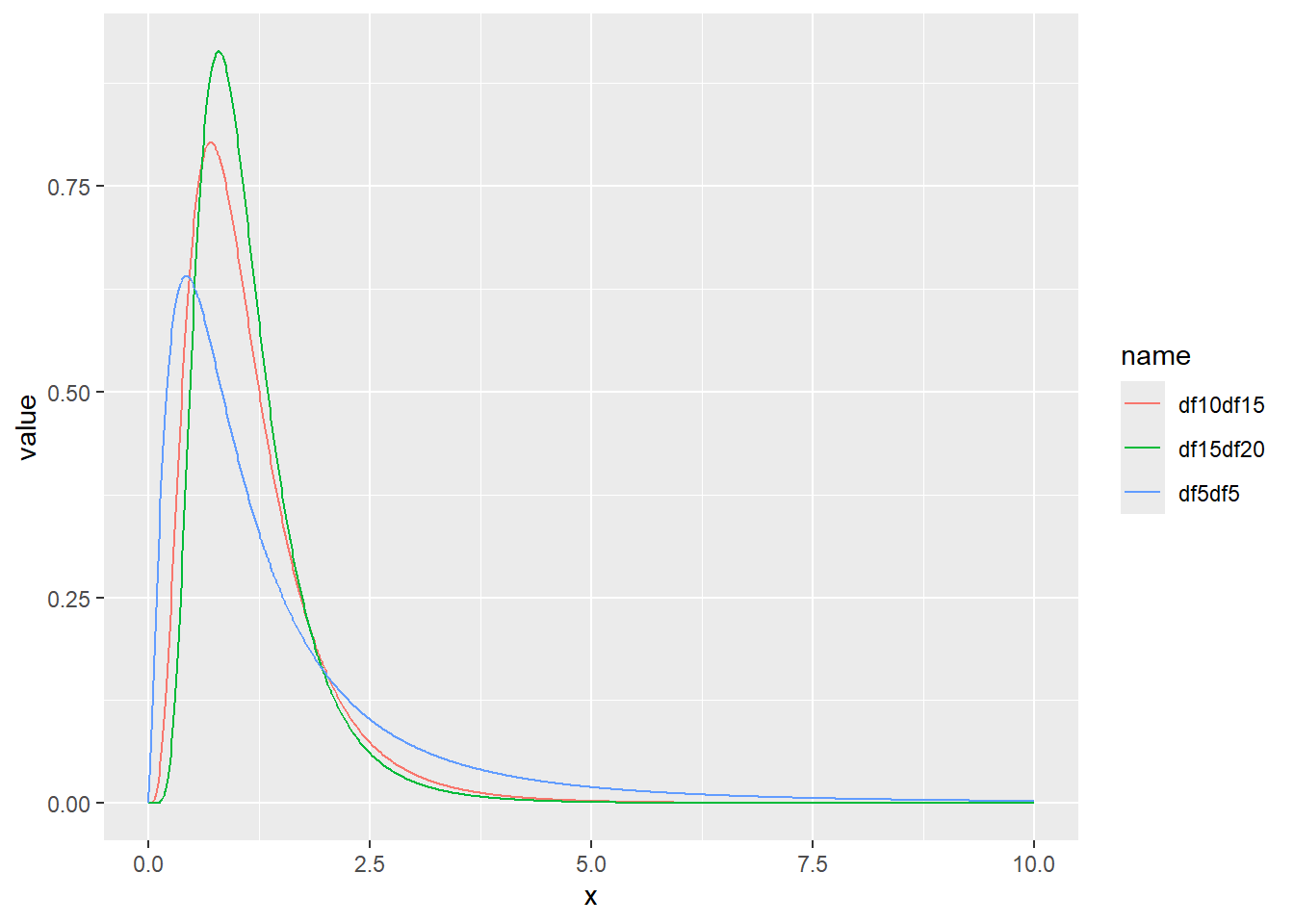
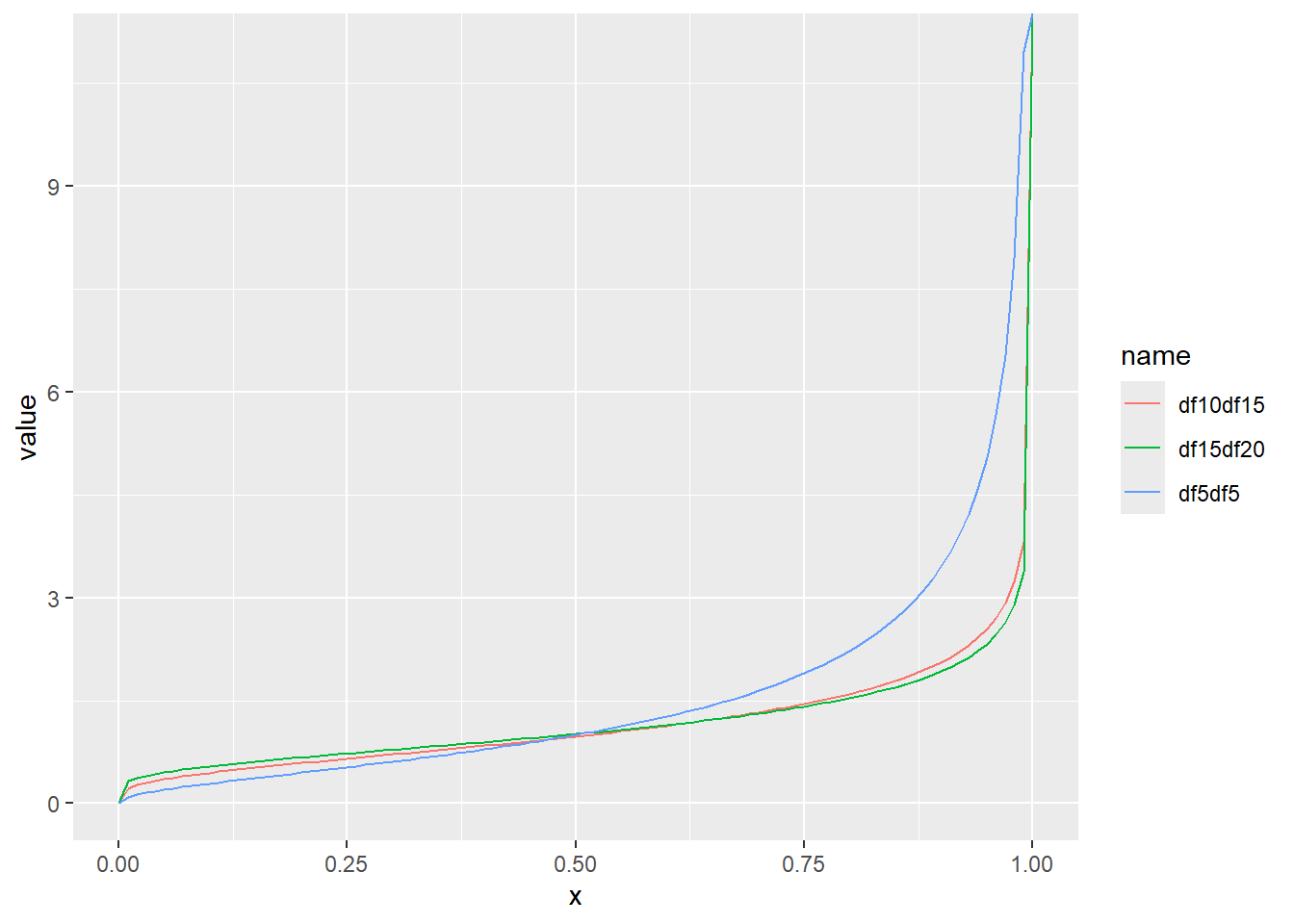
累積分布関数の分位点と値の関係をqfでプロット
乱数の確率密度をプロット
d <- tibble(
df5df5 = rf(1000, df1 = 5, df2 = 5), # 自由度1 5、自由度2 5
df10df15 = rf(1000, df1 = 10, df2 = 15), # 自由度1 10、自由度2 15
df15df20 = rf(1000, df1 = 20, df2 = 15) # 自由度1 20、自由度2 15
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position = "identity")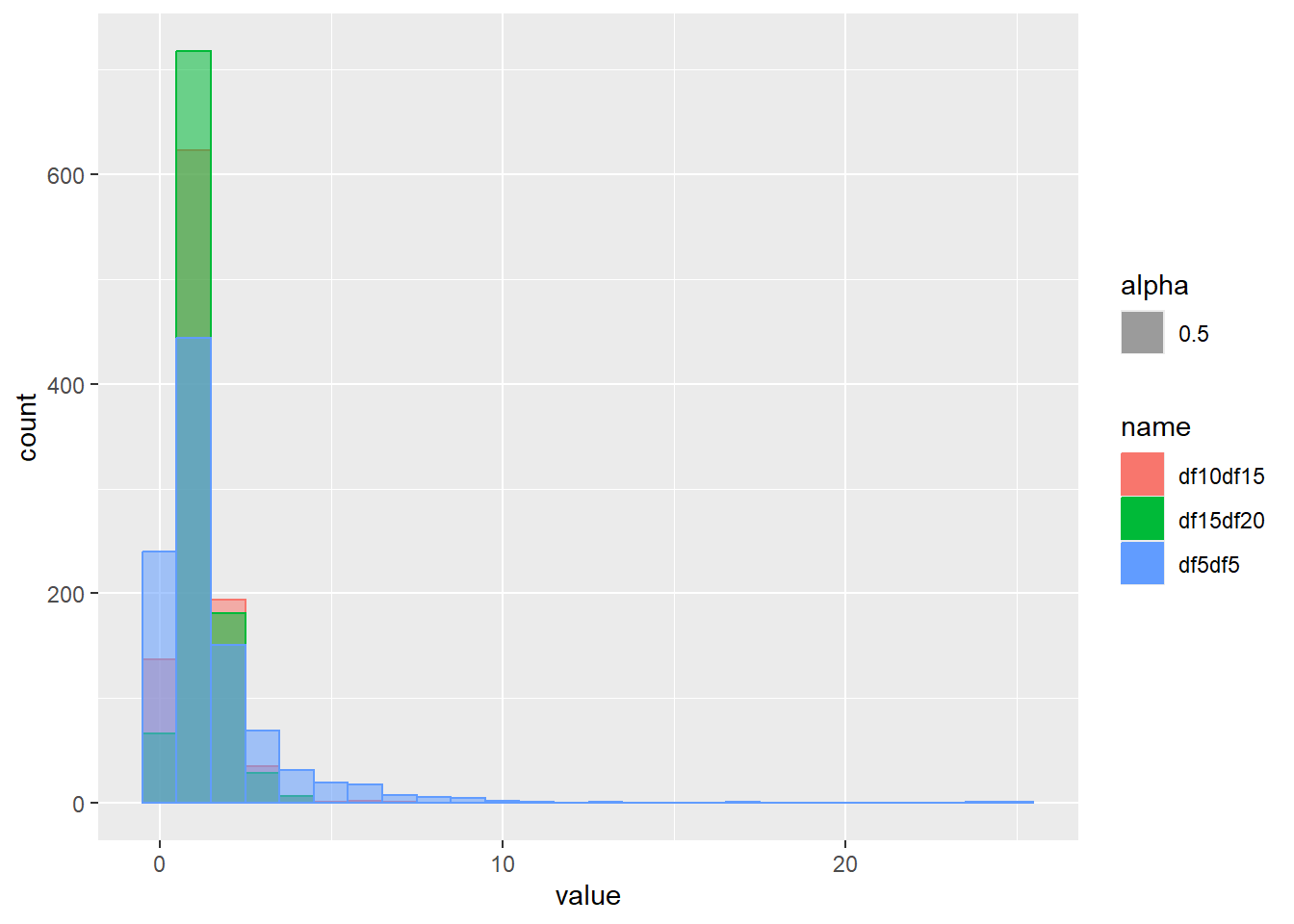
Rでデータフレームを変数に代入する場合、data.frameから変数名をdfとする場合があるのですが、このdfにデータフレームを代入してしまうと、F関数の確率密度関数であるdf関数を上書きしてしまいます。正直df関数を使う機会はほとんどないのですが、データフレームの変数名にはdの一文字を用いたり、きちんと意味のある名前を用いた方がよいでしょう。
ガンマ分布は機械の信頼性や降雨量などの説明に用いられる分布です。ガンマ分布のパラメータは形状パラメータγとスケールパラメータβの2つです。ガンマ分布の確率密度関数は以下の式で表されます。
\[Gamma(x, \gamma, \beta)=\frac{(\frac{x}{\beta})^{\gamma-1} \cdot \exp(-\frac{x}{\beta})}{\beta \cdot \Gamma(\gamma)}\]
Rでのガンマ分布の確率密度関数はdgamma関数で計算することができます。ガンマ分布のパラメータである形状パラメータはshape引数、スケールパラメータはscale引数で指定します。ガンマ分布は右側の裾が長い分布で、最頻値が0以上となる形状を示し、0~\(\infty\)の範囲を持つ連続値を取ります。
ガンマ分布の確率密度をプロット
x <- seq(0, 100, by = 0.1)
d <- tibble(
x,
df5df5 = dgamma(x, shape = 5, scale = 2), # shape 5 scale 2
df10df15 = dgamma(x, shape = 10, scale = 4), # shape 10 scale 4
df15df20 = dgamma(x, shape = 1, scale = 6) # shape 1 scale 6
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()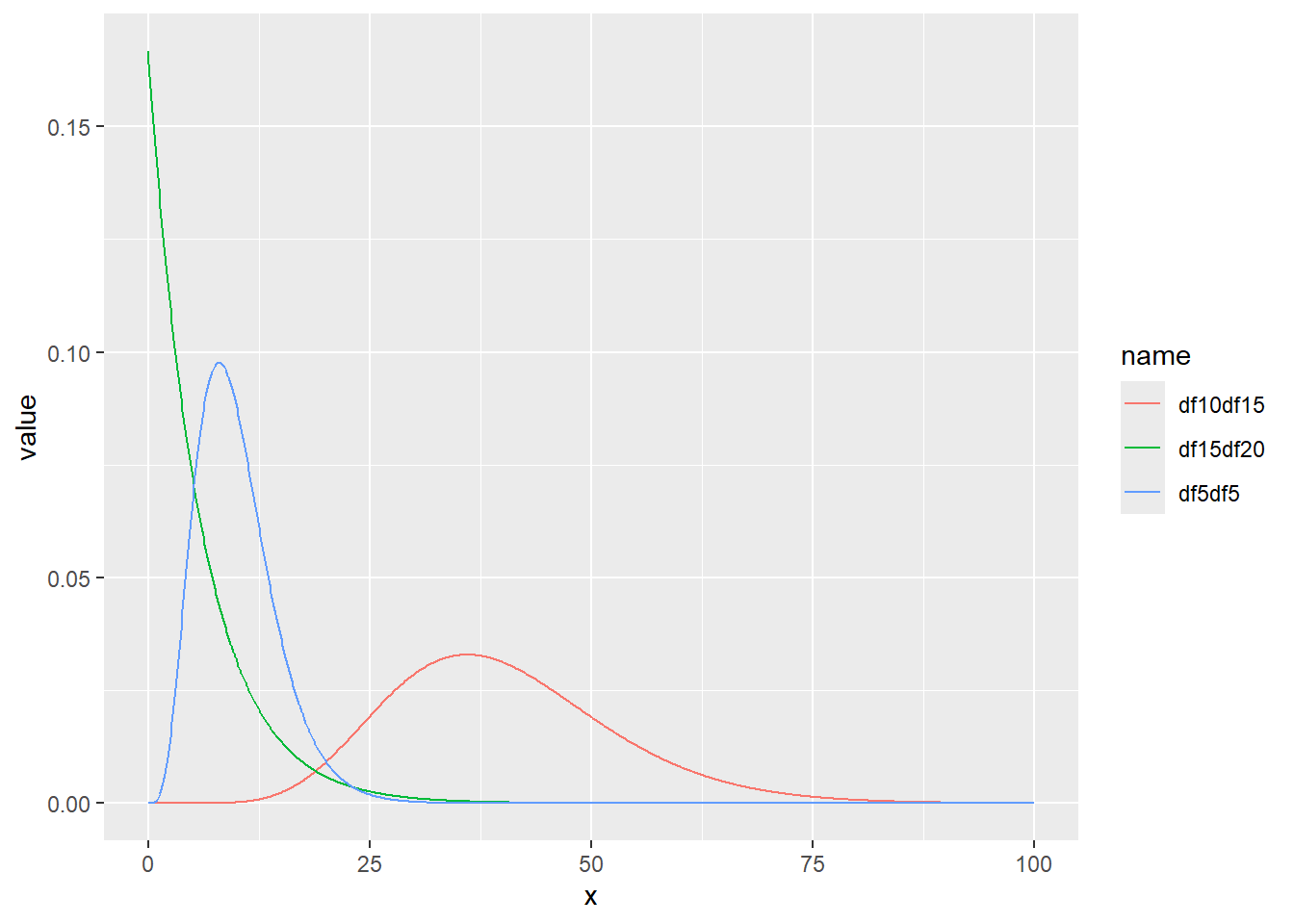
ガンマ分布の累積分布関数をプロット
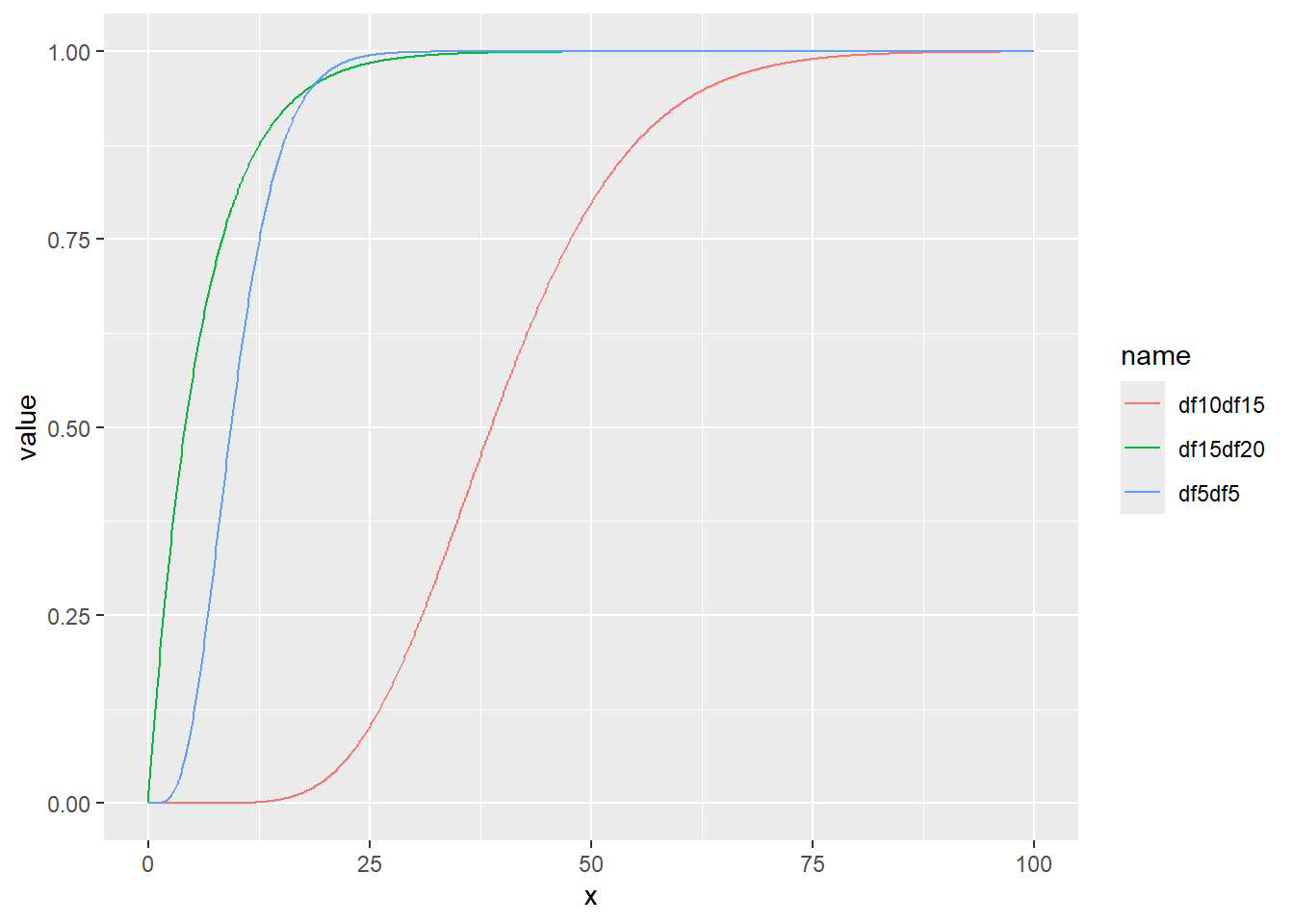
累積分布関数の分位点と値の関係をqfでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
df5df5 = qgamma(x, shape = 5, scale = 2), # shape 5 scale 2
df10df15 = qgamma(x, shape = 10, scale = 4), # shape 10 scale 4
df15df20 = qgamma(x, shape = 1, scale = 6) # shape 1 scale 6
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()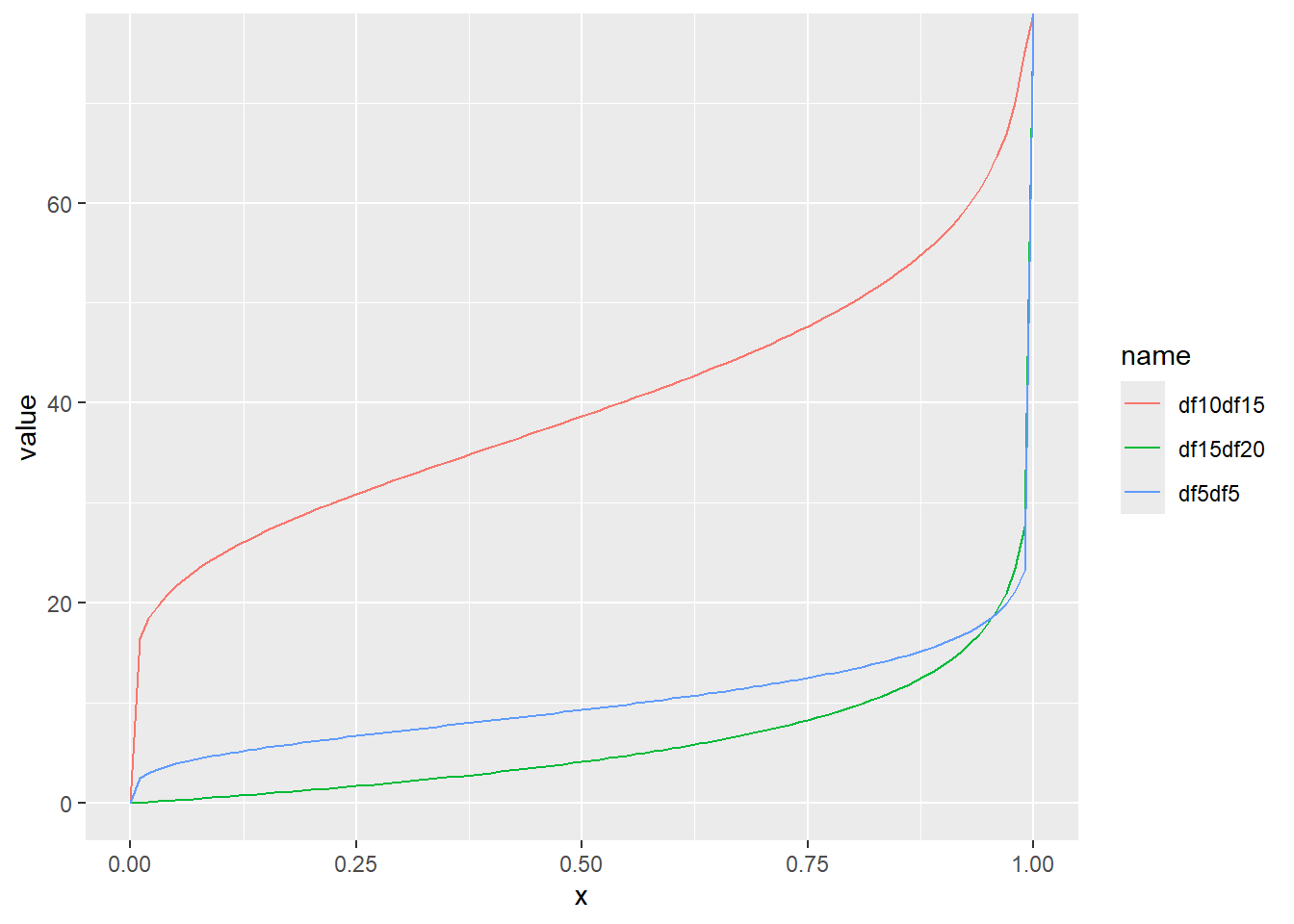
乱数の確率密度をプロット
d <- tibble(
df5df5 = rgamma(1000, shape = 5, scale = 2), # shape 5 scale 2
df10df15 = rgamma(1000, shape = 10, scale = 4), # shape 10 scale 4
df15df20 = rgamma(1000, shape = 1, scale = 6) # shape 1 scale 6
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 5, position = "identity")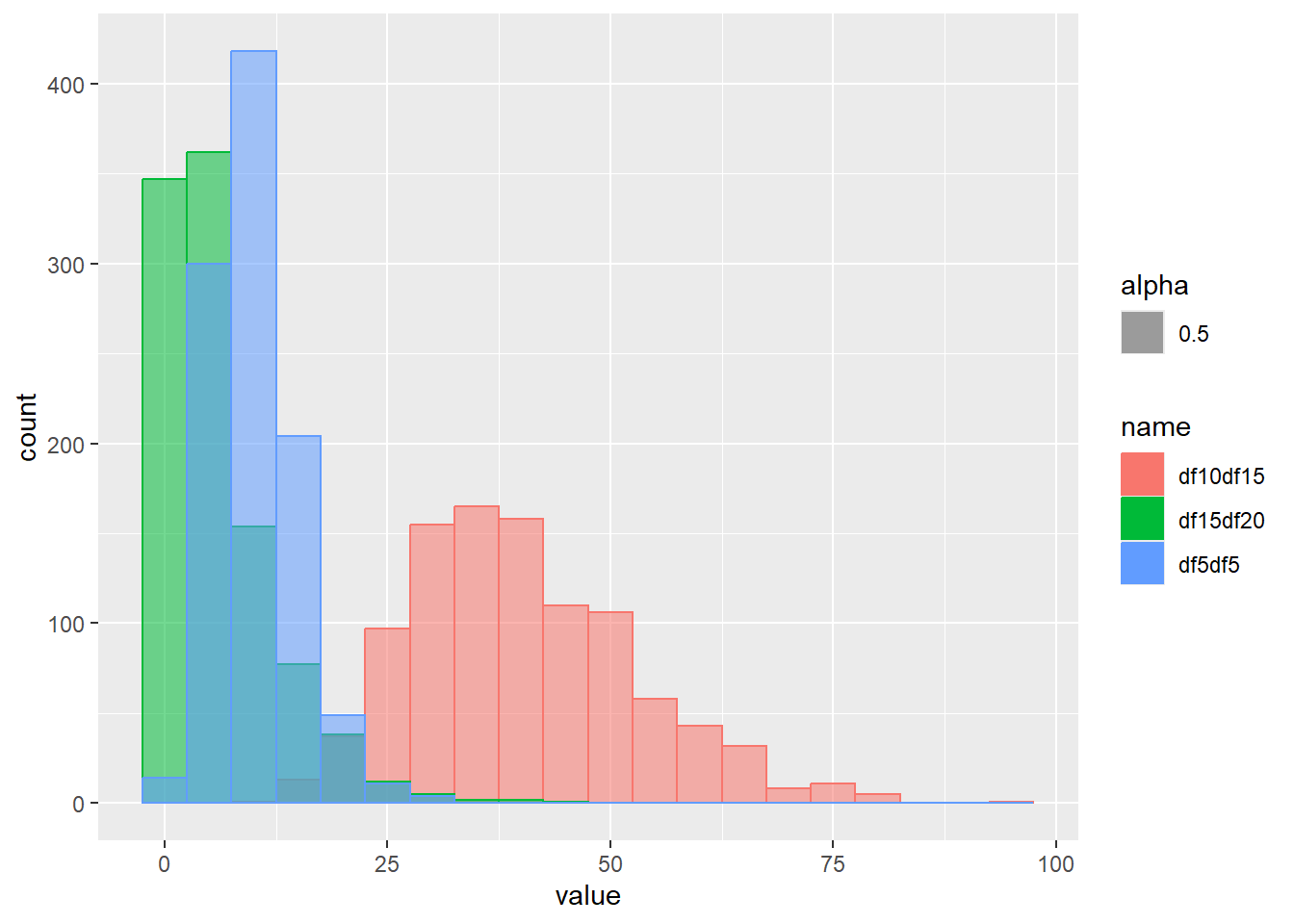
指数分布はポアソン分布する事象(まれに起こる事象)が起こる時間間隔の分布を示す確率分布です。指数分布は生存時間解析などの、イベントの発生数と時間の関係を解析するのに用いられています。指数分布のパラメータはλのみで、λは正の値を取ります。指数分布の確率密度関数は以下の式で表されます。
\[Exp(x, \lambda)=\lambda \cdot \exp(-\lambda x)\]
Rでは指数分布の確率密度関数はdexp関数で計算することができます。dexp関数では、λをrate引数で指定します。指数分布は単調減少で、0~\(\infty\)の範囲を持つ連続値を取ります。
ワイブル分布は指数分布を拡張したような確率分布です。指数分布では、ポアソン分布する事象(イベント)が起きる確率は常に一定であることを仮定していますが、ワイブル分布を用いると単調増加・単調減少でイベントが起きる確率が変化する場合を表現することができます。ワイブル分布のパラメータは形状パラメータのλとスケールパラメータのkの2つです。ワイブル分布の確率密度関数は以下の式で表されます。
\[Weibull(x, \lambda, k)=\frac{k}{\lambda}(\frac{x}{\lambda})^{k-1} \cdot \exp(-\frac{x}{\lambda})^k\]
Rでは、ワイブル分布の確率密度関数をdweibull関数で計算することができます。dweibull関数の引数は形状パラメータλであるshapeと、スケールパラメータkであるscaleの2つです。ワイブル分布はガンマ分布と同じく、右側の裾が長い分布で、最頻値が0以上となる形状を示し、0~\(\infty\)の範囲を持つ連続値を取ります。
ワイブル分布の確率密度をプロット
x <- seq(0, 5, by = 0.01)
d <- tibble(
x,
s1s1 = dweibull(x, shape = 1, scale = 1), # shape 1、scale 1
s2s2 = dweibull(x, shape = 2, scale = 2), # shape 2、scale 2
s05s05 = dweibull(x, shape = 0.5, scale = 0.5) # shape 0.5、scale 0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()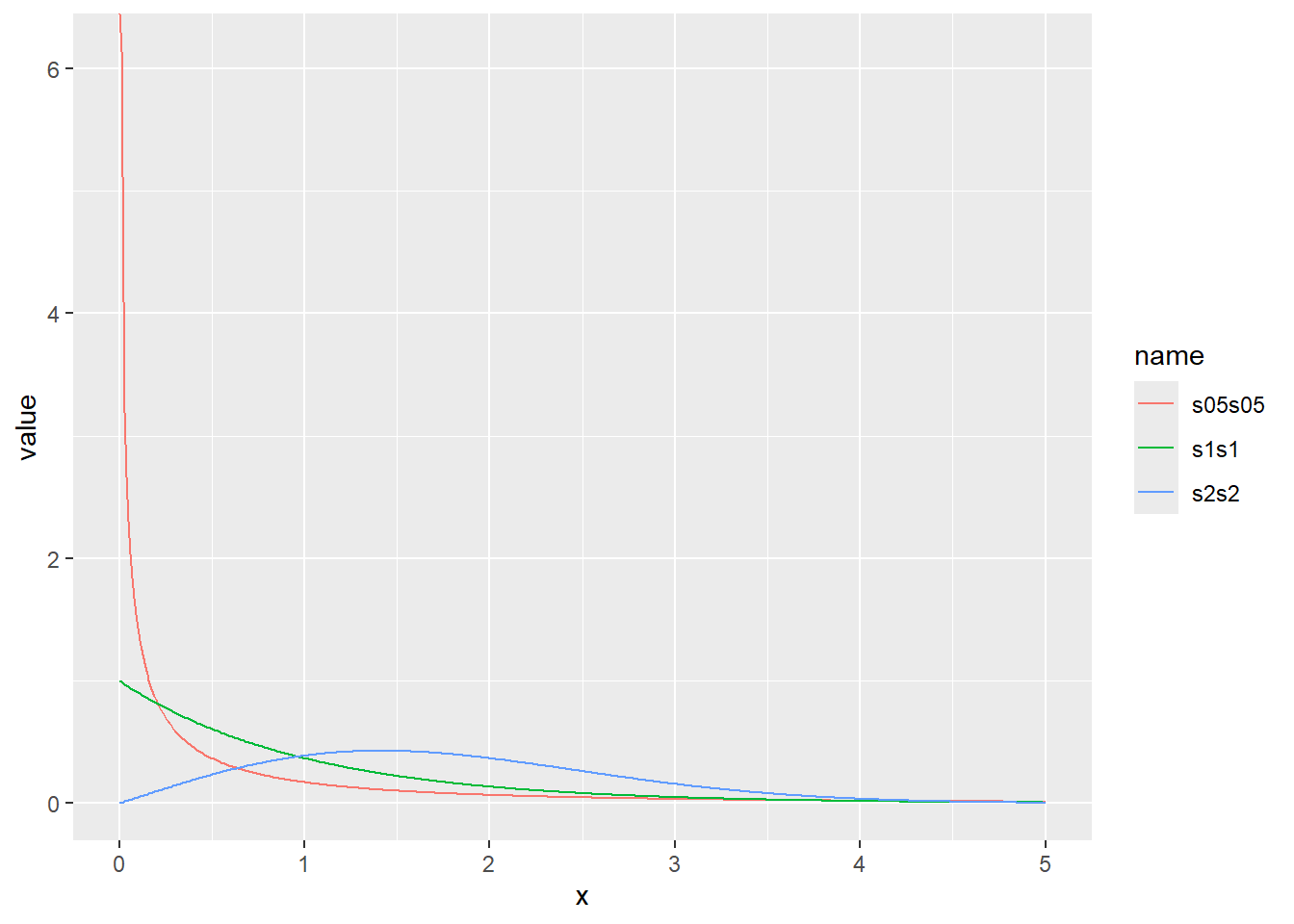
ワイブル分布の累積分布関数をプロット
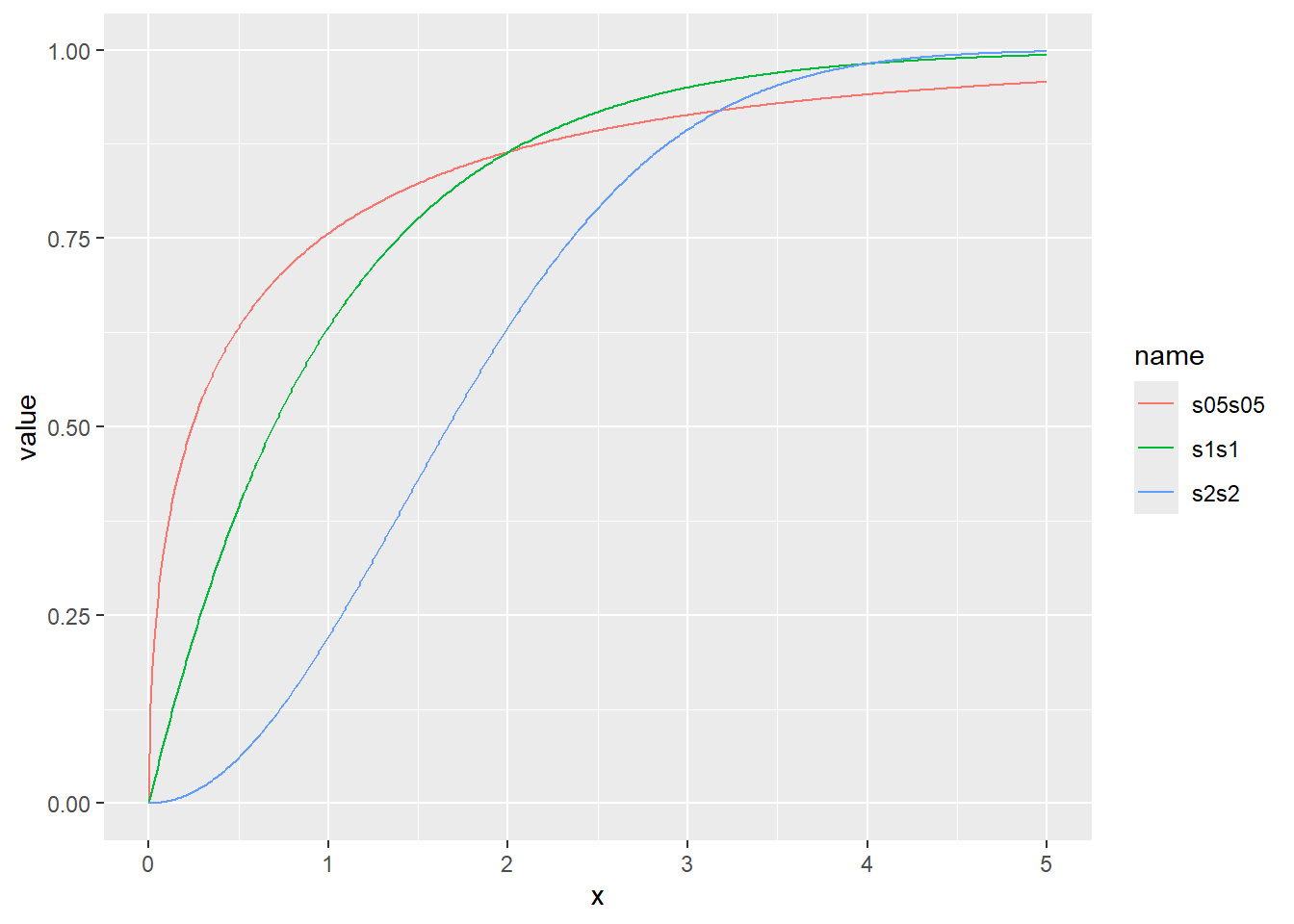
累積分布関数の分位点と値の関係をqfでプロット
x <- seq(0, 1, by = 0.01)
d <- tibble(
x,
s1s1 = qweibull(x, shape = 1, scale = 1), # shape 1、scale 1
s2s2 = qweibull(x, shape = 2, scale = 2), # shape 2、scale 2
s05s05 = qweibull(x, shape = 0.5, scale = 0.5) # shape 0.5、scale 0.5
)
d |>
pivot_longer(2:4) |>
ggplot(aes(x = x, y = value, color = name)) +
geom_line()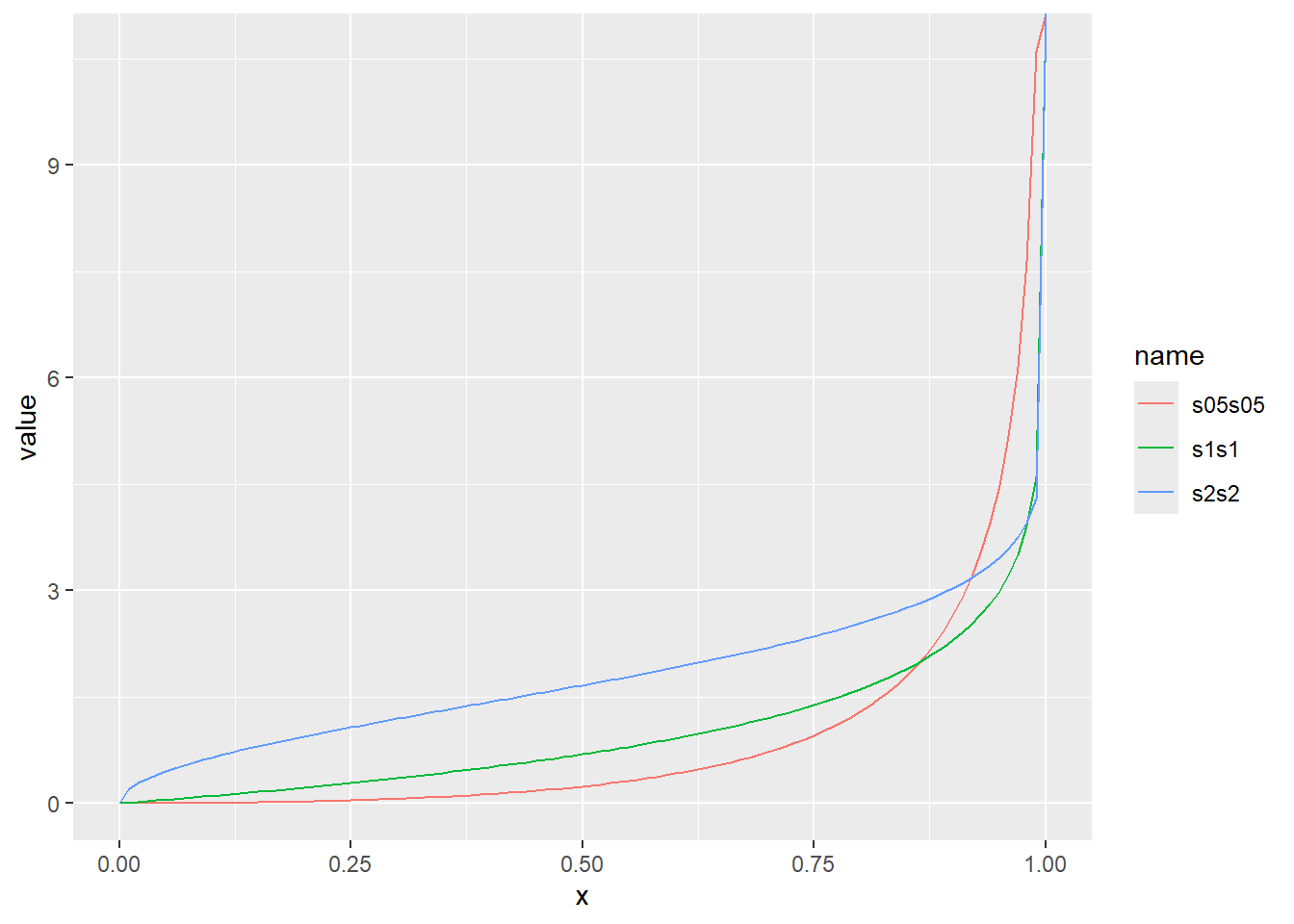
乱数の確率密度をプロット
d <- tibble(
s1s1 = rweibull(1000, shape = 1, scale = 1), # shape 1、scale 1
s2s2 = rweibull(1000, shape = 2, scale = 2), # shape 2、scale 2
s05s05 = rweibull(1000, shape = 0.5, scale = 0.5) # shape 0.5、scale 0.5
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 0.2, position = "identity")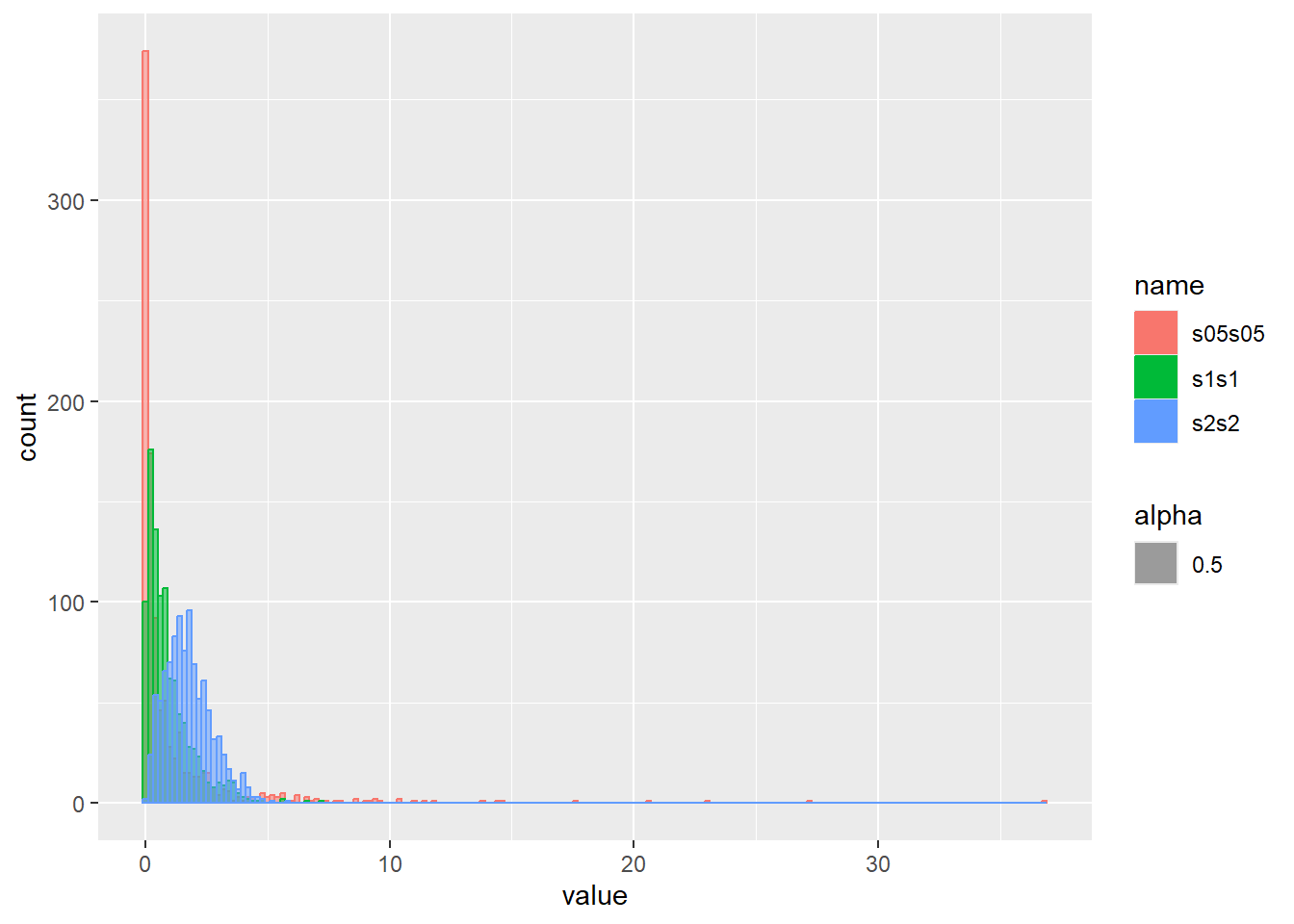
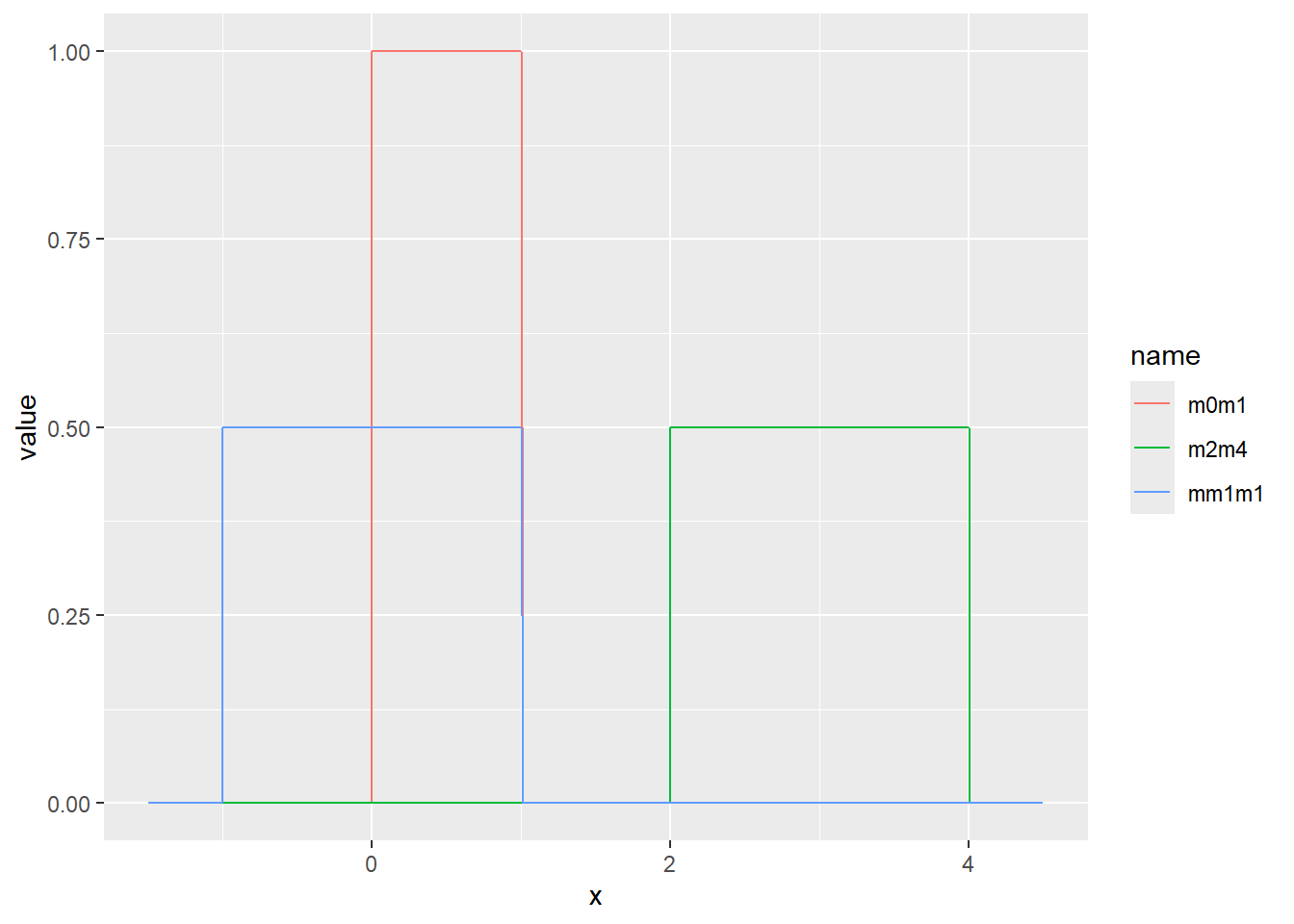
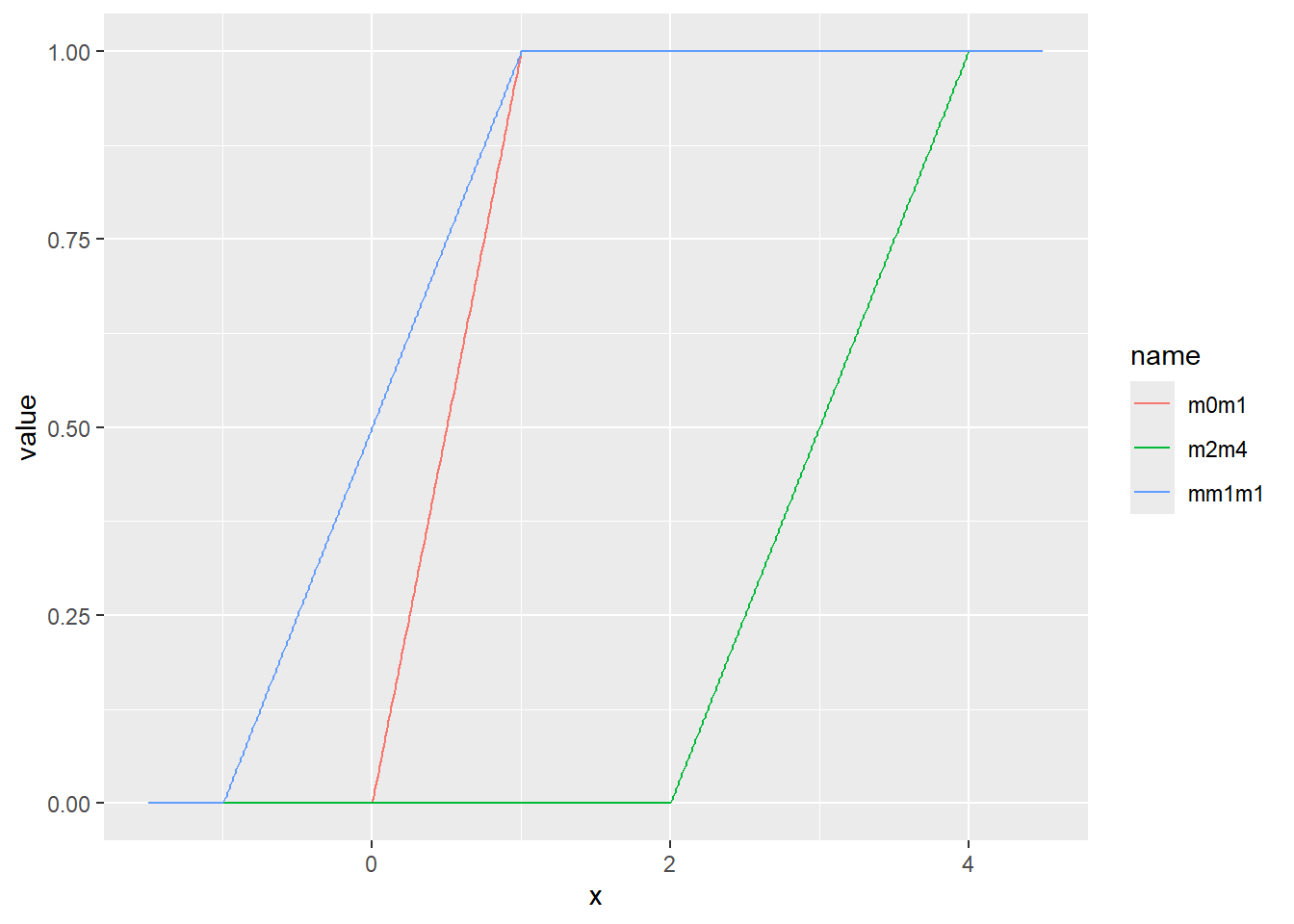
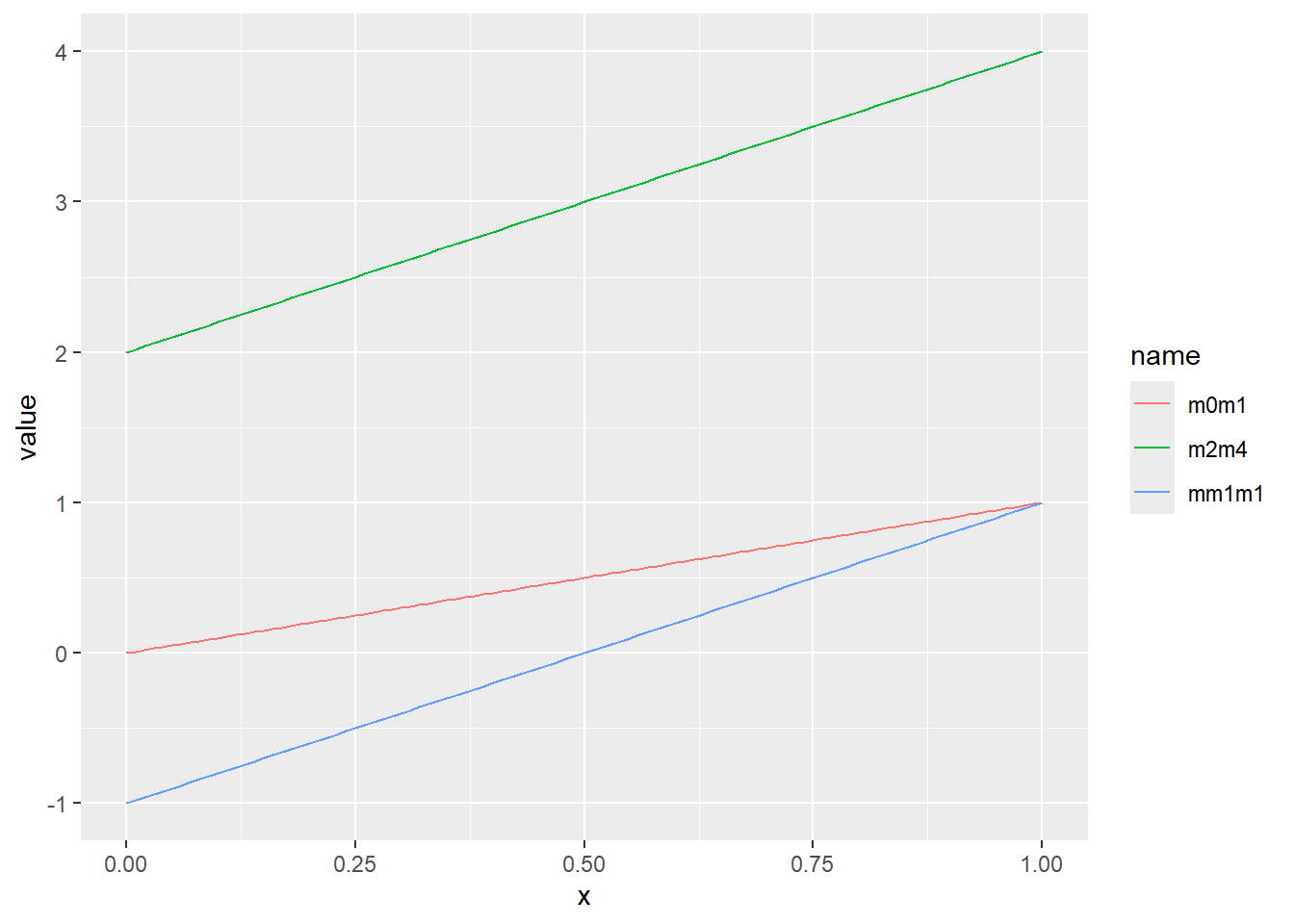
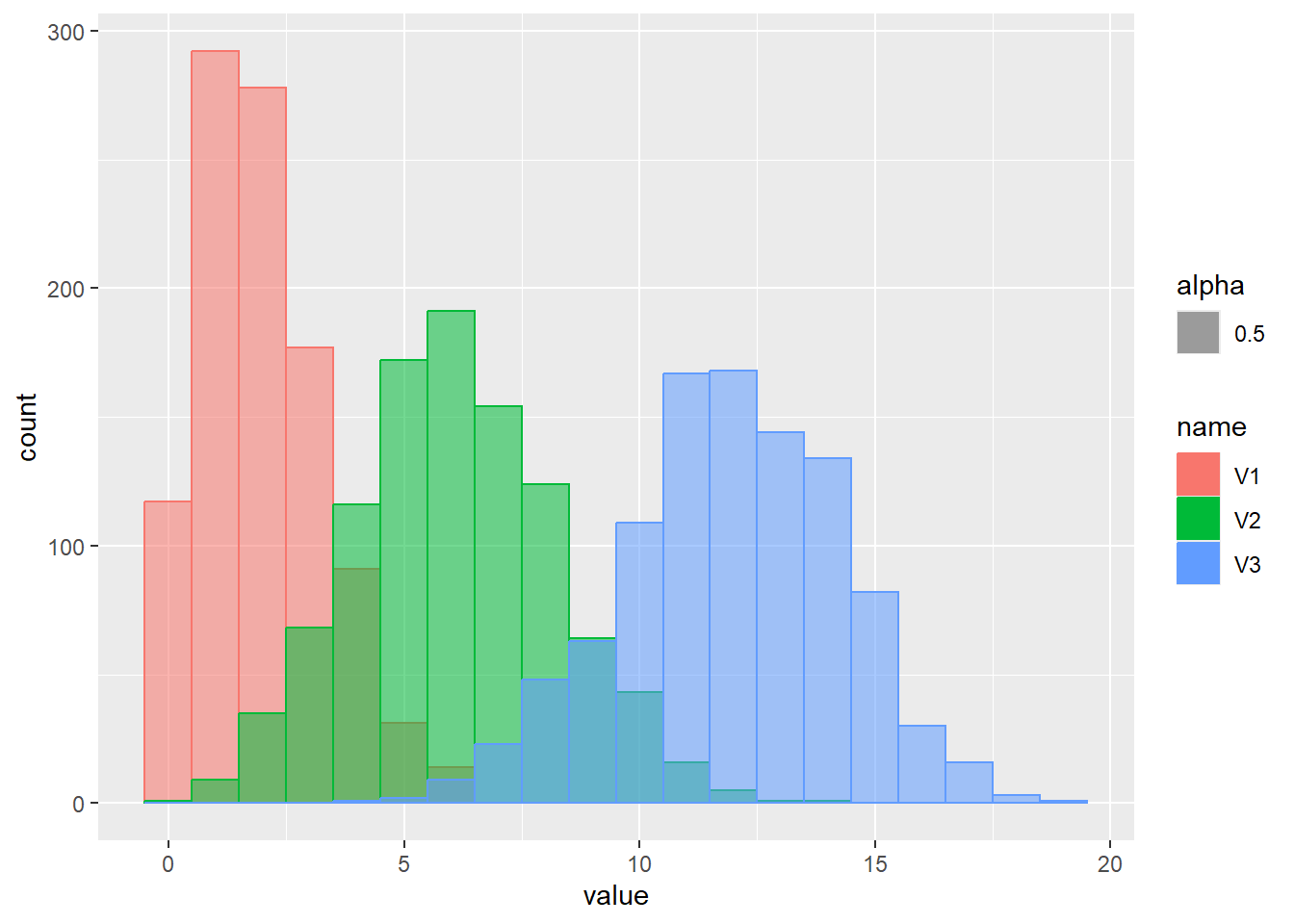
一様分布は、最小値(a)から最大値(b)まで、一定の確率で現れる現象を示す分布です。この章の始めに示したsample関数の乱数やサイコロなどが一様分布の典型的な例です。一様分布のパラメータは最小値aと最大値bの2つです。一様分布の確率密度関数は以下の式で表されます。
\[Uniform(x, a, b)=\frac{1}{b-a}\]
Rでは、一様分布の確率密度関数をdunif関数で計算することができます。dunif関数では最小値aとしてmin、最大値bとしてmaxの2つのパラメータを引数に指定します。一様分布はその名の通り確率密度が一定で、a~bの範囲を持つ連続値を取ります。
乱数の確率密度をプロット
d <- tibble(
m0m1 = runif(1000, min = 0, max = 1), # 最小0、最大1
mm1m1 = runif(1000, min = -1, max = 1), # 最小-1、最大1
m2m4 = runif(1000, min = 2, max = 4) # 最小2、最大4
)
d |>
pivot_longer(1:3) |>
ggplot(aes(x = value, color = name, fill = name, alpha = 0.5)) +
geom_histogram(binwidth = 1, position="identity")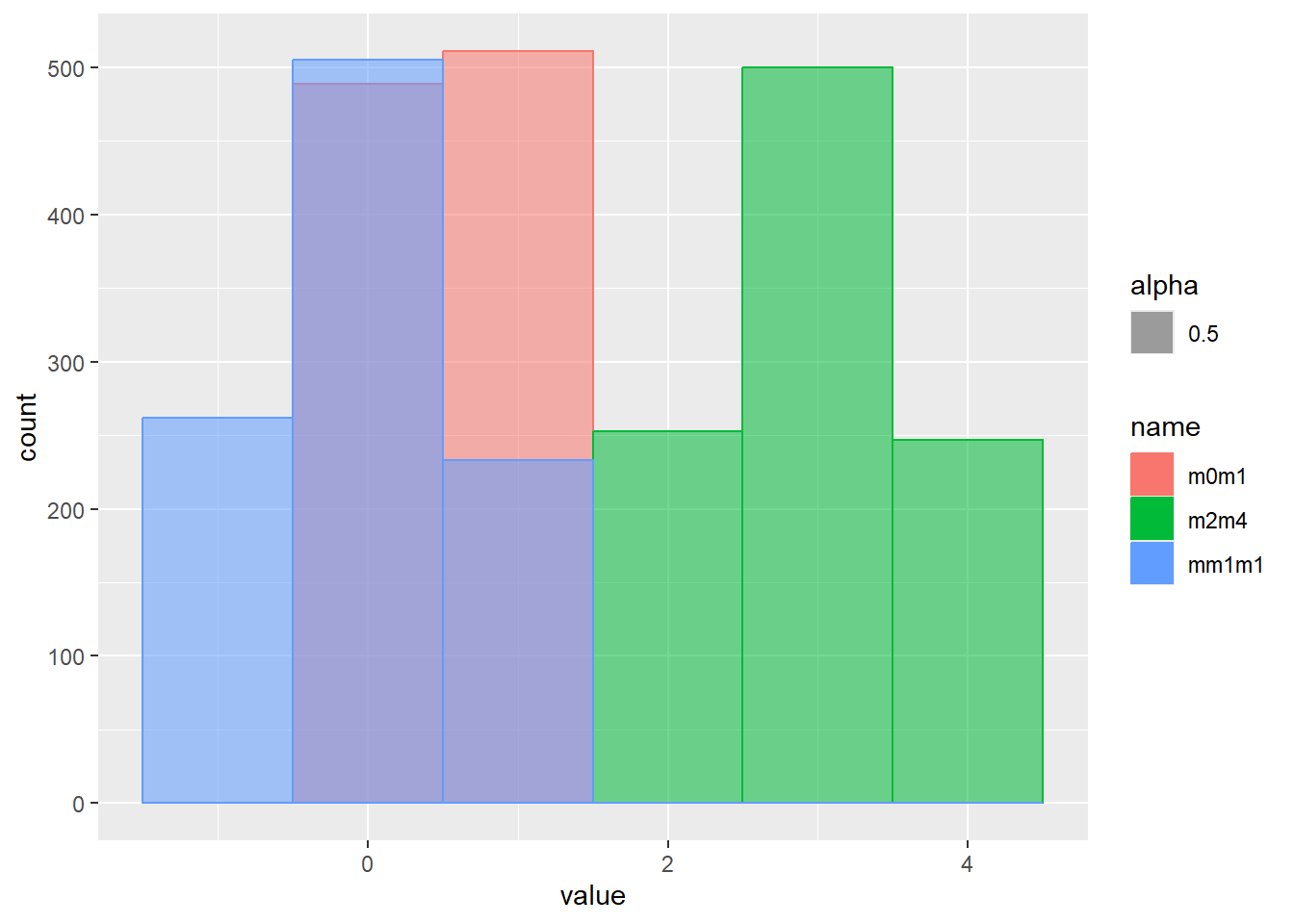
多項分布はここまでに示した確率分布とは異なり、Rには累積分布関数や分位点の関数が設定されていない確率分布です。多項分布は、複数の事象、例えばツボに白・赤・黒のボールを違う数で入れておき、取り出しては戻すような試行(復元抽出)を行うとき、それぞれの色のボールを特定の数だけ取り出す確率を計算するときに用います。各色のボールを取り出す確率はそれぞれ異なりますが、足し合わせれば確率が1となるような状況で多項分布は用いられます。
多項分布の確率質量関数のパラメータはボールの色がk色の時、ボールを取り出す回数n、各色のボールを取り出す数x1~xk、各色のボールを取り出す確率p1pkの4種類となります。nはx1~xkの和となります。
\[Multinomial(n, x_{1}, x_{2}, \cdots x_{k}, p_{1}, p_{2}, \cdots p_{k})=\frac{n!}{x_{1}! \cdot x_{2}! \cdot \cdots \cdot x_{k}!} \cdot p_{1}^{x_{1}} \cdot p_{2}^{x_{2}} \cdot \cdots p_{k}^{x_{k}}\]
Rでは、dmultinom関数で多項分布の確率質量関数を計算することができます。dmultinom関数の引数はボールを取り出す回数nを表すsize、各色のボールを取り出す数のx1~xkをベクターで表したx、各色のボールを取り出す確率であるp1pkを同じくベクターで表したprobの3つとなります。
また、多項分布の乱数を得る関数であるrmultinom関数も他の確率分布を示す乱数の関数とはやや使い方が異なります。sizeとprobの2つの引数を指定するのは上と同じですが、返り値は合計がsizeで指定した数値となるボールの数k個の乱数です。probで確率を指定したそれぞれに対する値(ボールの数のようなもの)が第一引数(n)で示した数だけ、列として並ぶ行列が返ってきます。
多項分布の関数
# 0.1、0.3、0.6の確率で起こる事象がそれぞれ1、2、4回同時に起こる確率
dmultinom(x = c(1, 2, 4), size = 7, prob = c(0.1, 0.3, 0.6))
## [1] 0.122472
# 足し合わせると20になるものが10個、列として返ってくる。
# 行の上から、0.1、0.3、0.6の確率で現れている
rmultinom(10, size=20, prob = c(0.1, 0.3, 0.6))
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 3 2 1 3 4 2 1 0 2 0
## [2,] 4 6 2 4 6 5 5 9 3 8
## [3,] 13 12 17 13 10 13 14 11 15 12